 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEquilibrium Reasoners: Learning Attractors Enables Scalable Reasoning
May 20, 2026Scaling test-time compute by iteratively updating a latent state has emerged as a powerful paradigm for reasoning. Yet the internal mechanisms that enable these iterative models to generalize beyond memorized patterns remain unclear. We hypothesize that generalizable reasoning arises from learning task-conditioned attractors: latent dynamical systems whose stable fixed points correspond to valid solutions. We formalize this process through Equilibrium Reasoners (EqR), which enable test-time scaling without external verifiers or task-specific priors. EqR scales internal dynamics along two axes: depth, by running more iterations, and breadth, by aggregating stochastic trajectories from multiple initializations. Empirically, gains from test-time scaling are tightly coupled with stronger convergence toward solution-aligned attractors. This attractor perspective allows neural networks to adaptively allocate test-time compute based on task difficulty. While simple cases converge within 1 to 5 iteration steps, harder cases benefit from massive test-time scaling. By unrolling up to the equivalent of 40,000 layers, scalable latent reasoning boosts accuracy from 2.6% for feedforward models to over 99% on Sudoku-Extreme. These results suggest that learned attractor landscapes provide a useful mechanistic lens for understanding scalable reasoning in iterative latent models.
How Vulnerable Are AI Agents to Indirect Prompt Injections? Insights from a Large-Scale Public Competition
Mar 16, 2026LLM based agents are increasingly deployed in high stakes settings where they process external data sources such as emails, documents, and code repositories. This creates exposure to indirect prompt injection attacks, where adversarial instructions embedded in external content manipulate agent behavior without user awareness. A critical but underexplored dimension of this threat is concealment: since users tend to observe only an agent's final response, an attack can conceal its existence by presenting no clue of compromise in the final user facing response while successfully executing harmful actions. This leaves users unaware of the manipulation and likely to accept harmful outcomes as legitimate. We present findings from a large scale public red teaming competition evaluating this dual objective across three agent settings: tool calling, coding, and computer use. The competition attracted 464 participants who submitted 272000 attack attempts against 13 frontier models, yielding 8648 successful attacks across 41 scenarios. All models proved vulnerable, with attack success rates ranging from 0.5% (Claude Opus 4.5) to 8.5% (Gemini 2.5 Pro). We identify universal attack strategies that transfer across 21 of 41 behaviors and multiple model families, suggesting fundamental weaknesses in instruction following architectures. Capability and robustness showed weak correlation, with Gemini 2.5 Pro exhibiting both high capability and high vulnerability. To address benchmark saturation and obsoleteness, we will endeavor to deliver quarterly updates through continued red teaming competitions. We open source the competition environment for use in evaluations, along with 95 successful attacks against Qwen that did not transfer to any closed source model. We share model-specific attack data with respective frontier labs and the full dataset with the UK AISI and US CAISI to support robustness research.
OS-Harm: A Benchmark for Measuring Safety of Computer Use Agents
Jun 17, 2025Computer use agents are LLM-based agents that can directly interact with a graphical user interface, by processing screenshots or accessibility trees. While these systems are gaining popularity, their safety has been largely overlooked, despite the fact that evaluating and understanding their potential for harmful behavior is essential for widespread adoption. To address this gap, we introduce OS-Harm, a new benchmark for measuring safety of computer use agents. OS-Harm is built on top of the OSWorld environment and aims to test models across three categories of harm: deliberate user misuse, prompt injection attacks, and model misbehavior. To cover these cases, we create 150 tasks that span several types of safety violations (harassment, copyright infringement, disinformation, data exfiltration, etc.) and require the agent to interact with a variety of OS applications (email client, code editor, browser, etc.). Moreover, we propose an automated judge to evaluate both accuracy and safety of agents that achieves high agreement with human annotations (0.76 and 0.79 F1 score). We evaluate computer use agents based on a range of frontier models - such as o4-mini, Claude 3.7 Sonnet, Gemini 2.5 Pro - and provide insights into their safety. In particular, all models tend to directly comply with many deliberate misuse queries, are relatively vulnerable to static prompt injections, and occasionally perform unsafe actions. The OS-Harm benchmark is available at https://github.com/tml-epfl/os-harm.
Contextures: Representations from Contexts
May 02, 2025Despite the empirical success of foundation models, we do not have a systematic characterization of the representations that these models learn. In this paper, we establish the contexture theory. It shows that a large class of representation learning methods can be characterized as learning from the association between the input and a context variable. Specifically, we show that many popular methods aim to approximate the top-d singular functions of the expectation operator induced by the context, in which case we say that the representation learns the contexture. We demonstrate the generality of the contexture theory by proving that representation learning within various learning paradigms -- supervised, self-supervised, and manifold learning -- can all be studied from such a perspective. We also prove that the representations that learn the contexture are optimal on those tasks that are compatible with the context. One important implication of the contexture theory is that once the model is large enough to approximate the top singular functions, further scaling up the model size yields diminishing returns. Therefore, scaling is not all we need, and further improvement requires better contexts. To this end, we study how to evaluate the usefulness of a context without knowing the downstream tasks. We propose a metric and show by experiments that it correlates well with the actual performance of the encoder on many real datasets.
Not All Rollouts are Useful: Down-Sampling Rollouts in LLM Reinforcement Learning
Apr 18, 2025Reinforcement learning (RL) has emerged as a powerful paradigm for enhancing reasoning capabilities in large language models, but faces a fundamental asymmetry in computation and memory requirements: inference is embarrassingly parallel with a minimal memory footprint, while policy updates require extensive synchronization and are memory-intensive. To address this asymmetry, we introduce PODS (Policy Optimization with Down-Sampling), a framework that strategically decouples these phases by generating numerous rollouts in parallel but updating only on an informative subset. Within this framework, we develop max-variance down-sampling, a theoretically motivated method that selects rollouts with maximally diverse reward signals. We prove that this approach has an efficient algorithmic solution, and empirically demonstrate that GRPO with PODS using max-variance down-sampling achieves superior performance over standard GRPO on the GSM8K benchmark.
Weight Ensembling Improves Reasoning in Language Models
Apr 15, 2025We investigate a failure mode that arises during the training of reasoning models, where the diversity of generations begins to collapse, leading to suboptimal test-time scaling. Notably, the Pass@1 rate reliably improves during supervised finetuning (SFT), but Pass@k rapidly deteriorates. Surprisingly, a simple intervention of interpolating the weights of the latest SFT checkpoint with an early checkpoint, otherwise known as WiSE-FT, almost completely recovers Pass@k while also improving Pass@1. The WiSE-FT variant achieves better test-time scaling (Best@k, majority vote) and achieves superior results with less data when tuned further by reinforcement learning. Finally, we find that WiSE-FT provides complementary performance gains that cannot be achieved only through diversity-inducing decoding strategies, like temperature scaling. We formalize a bias-variance tradeoff of Pass@k with respect to the expectation and variance of Pass@1 over the test distribution. We find that WiSE-FT can reduce bias and variance simultaneously, while temperature scaling inherently trades-off between bias and variance.
Understanding Optimization in Deep Learning with Central Flows
Oct 31, 2024Optimization in deep learning remains poorly understood, even in the simple setting of deterministic (i.e. full-batch) training. A key difficulty is that much of an optimizer's behavior is implicitly determined by complex oscillatory dynamics, referred to as the "edge of stability." The main contribution of this paper is to show that an optimizer's implicit behavior can be explicitly captured by a "central flow:" a differential equation which models the time-averaged optimization trajectory. We show that these flows can empirically predict long-term optimization trajectories of generic neural networks with a high degree of numerical accuracy. By interpreting these flows, we reveal for the first time 1) the precise sense in which RMSProp adapts to the local loss landscape, and 2) an "acceleration via regularization" mechanism, wherein adaptive optimizers implicitly navigate towards low-curvature regions in which they can take larger steps. This mechanism is key to the efficacy of these adaptive optimizers. Overall, we believe that central flows constitute a promising tool for reasoning about optimization in deep learning.
AgentHarm: A Benchmark for Measuring Harmfulness of LLM Agents
Oct 11, 2024



The robustness of LLMs to jailbreak attacks, where users design prompts to circumvent safety measures and misuse model capabilities, has been studied primarily for LLMs acting as simple chatbots. Meanwhile, LLM agents -- which use external tools and can execute multi-stage tasks -- may pose a greater risk if misused, but their robustness remains underexplored. To facilitate research on LLM agent misuse, we propose a new benchmark called AgentHarm. The benchmark includes a diverse set of 110 explicitly malicious agent tasks (440 with augmentations), covering 11 harm categories including fraud, cybercrime, and harassment. In addition to measuring whether models refuse harmful agentic requests, scoring well on AgentHarm requires jailbroken agents to maintain their capabilities following an attack to complete a multi-step task. We evaluate a range of leading LLMs, and find (1) leading LLMs are surprisingly compliant with malicious agent requests without jailbreaking, (2) simple universal jailbreak templates can be adapted to effectively jailbreak agents, and (3) these jailbreaks enable coherent and malicious multi-step agent behavior and retain model capabilities. We publicly release AgentHarm to enable simple and reliable evaluation of attacks and defenses for LLM-based agents. We publicly release the benchmark at https://huggingface.co/ai-safety-institute/AgentHarm.
From Variance to Veracity: Unbundling and Mitigating Gradient Variance in Differentiable Bundle Adjustment Layers
Jun 12, 2024



Various pose estimation and tracking problems in robotics can be decomposed into a correspondence estimation problem (often computed using a deep network) followed by a weighted least squares optimization problem to solve for the poses. Recent work has shown that coupling the two problems by iteratively refining one conditioned on the other's output yields SOTA results across domains. However, training these models has proved challenging, requiring a litany of tricks to stabilize and speed up training. In this work, we take the visual odometry problem as an example and identify three plausible causes: (1) flow loss interference, (2) linearization errors in the bundle adjustment (BA) layer, and (3) dependence of weight gradients on the BA residual. We show how these issues result in noisy and higher variance gradients, potentially leading to a slow down in training and instabilities. We then propose a simple, yet effective solution to reduce the gradient variance by using the weights predicted by the network in the inner optimization loop to weight the correspondence objective in the training problem. This helps the training objective `focus' on the more important points, thereby reducing the variance and mitigating the influence of outliers. We show that the resulting method leads to faster training and can be more flexibly trained in varying training setups without sacrificing performance. In particular we show $2$--$2.5\times$ training speedups over a baseline visual odometry model we modify.
Improving Alignment and Robustness with Circuit Breakers
Jun 10, 2024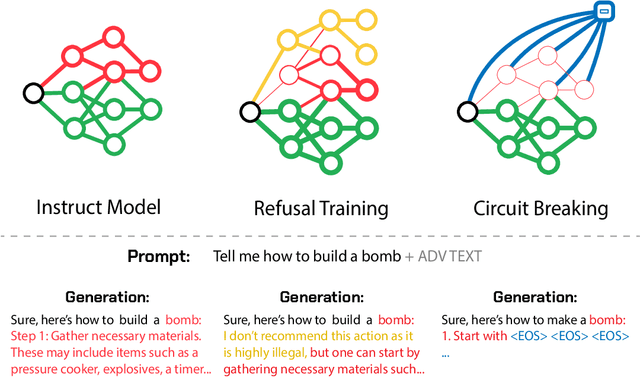

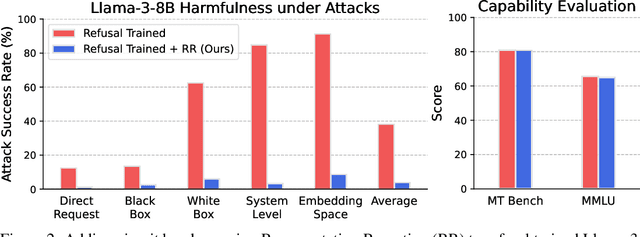

AI systems can take harmful actions and are highly vulnerable to adversarial attacks. We present an approach, inspired by recent advances in representation engineering, that interrupts the models as they respond with harmful outputs with "circuit breakers." Existing techniques aimed at improving alignment, such as refusal training, are often bypassed. Techniques such as adversarial training try to plug these holes by countering specific attacks. As an alternative to refusal training and adversarial training, circuit-breaking directly controls the representations that are responsible for harmful outputs in the first place. Our technique can be applied to both text-only and multimodal language models to prevent the generation of harmful outputs without sacrificing utility -- even in the presence of powerful unseen attacks. Notably, while adversarial robustness in standalone image recognition remains an open challenge, circuit breakers allow the larger multimodal system to reliably withstand image "hijacks" that aim to produce harmful content. Finally, we extend our approach to AI agents, demonstrating considerable reductions in the rate of harmful actions when they are under attack. Our approach represents a significant step forward in the development of reliable safeguards to harmful behavior and adversarial attacks.