 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Variance to Veracity: Unbundling and Mitigating Gradient Variance in Differentiable Bundle Adjustment Layers
Jun 12, 2024



Various pose estimation and tracking problems in robotics can be decomposed into a correspondence estimation problem (often computed using a deep network) followed by a weighted least squares optimization problem to solve for the poses. Recent work has shown that coupling the two problems by iteratively refining one conditioned on the other's output yields SOTA results across domains. However, training these models has proved challenging, requiring a litany of tricks to stabilize and speed up training. In this work, we take the visual odometry problem as an example and identify three plausible causes: (1) flow loss interference, (2) linearization errors in the bundle adjustment (BA) layer, and (3) dependence of weight gradients on the BA residual. We show how these issues result in noisy and higher variance gradients, potentially leading to a slow down in training and instabilities. We then propose a simple, yet effective solution to reduce the gradient variance by using the weights predicted by the network in the inner optimization loop to weight the correspondence objective in the training problem. This helps the training objective `focus' on the more important points, thereby reducing the variance and mitigating the influence of outliers. We show that the resulting method leads to faster training and can be more flexibly trained in varying training setups without sacrificing performance. In particular we show $2$--$2.5\times$ training speedups over a baseline visual odometry model we modify.
ReLU-QP: A GPU-Accelerated Quadratic Programming Solver for Model-Predictive Control
Nov 29, 2023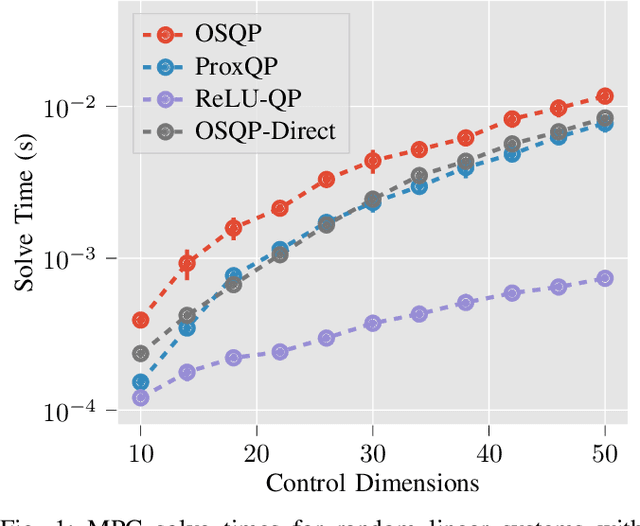
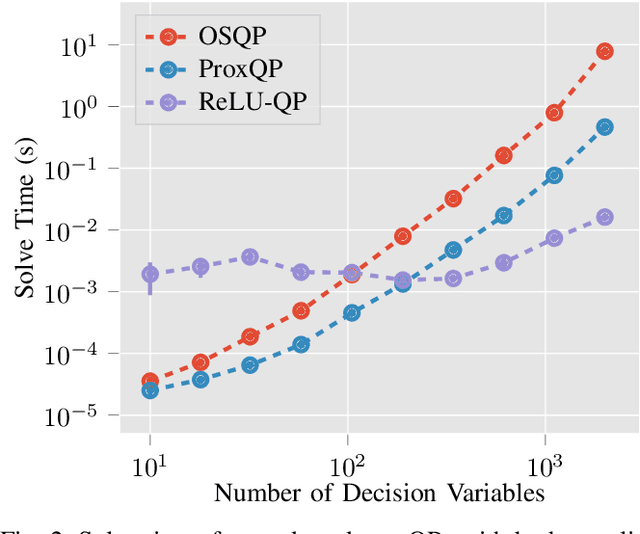
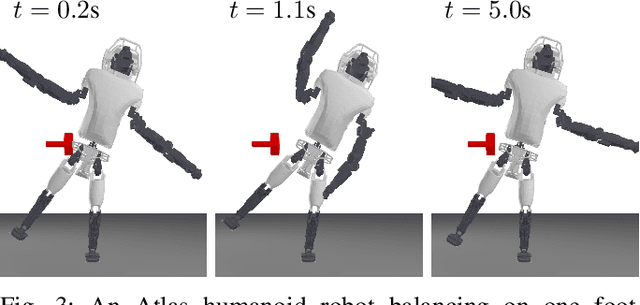
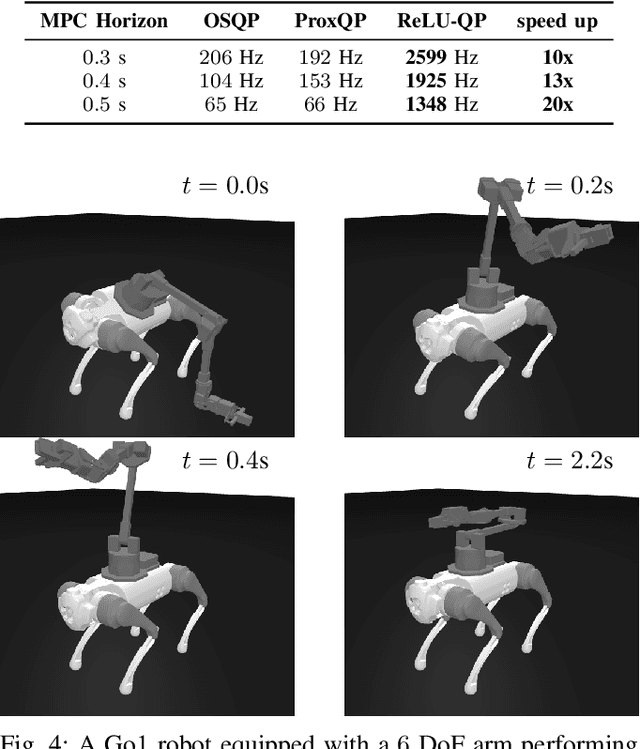
We present ReLU-QP, a GPU-accelerated solver for quadratic programs (QPs) that is capable of solving high-dimensional control problems at real-time rates. ReLU-QP is derived by exactly reformulating the Alternating Direction Method of Multipliers (ADMM) algorithm for solving QPs as a deep, weight-tied neural network with rectified linear unit (ReLU) activations. This reformulation enables the deployment of ReLU-QP on GPUs using standard machine-learning toolboxes. We evaluate the performance of ReLU-QP across three model-predictive control (MPC) benchmarks: stabilizing random linear dynamical systems with control limits, balancing an Atlas humanoid robot on a single foot, and tracking whole-body reference trajectories on a quadruped equipped with a six-degree-of-freedom arm. These benchmarks indicate that ReLU-QP is competitive with state-of-the-art CPU-based solvers for small-to-medium-scale problems and offers order-of-magnitude speed improvements for larger-scale problems.
Joint inference and input optimization in equilibrium networks
Nov 25, 2021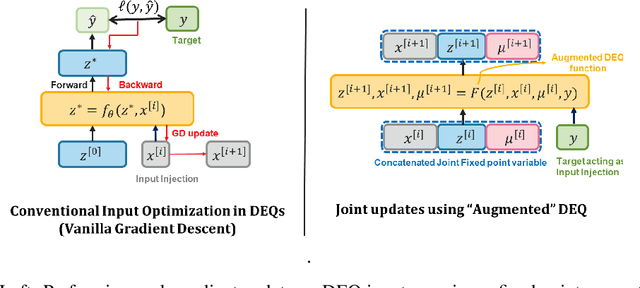
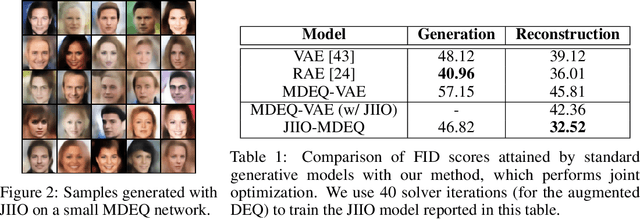
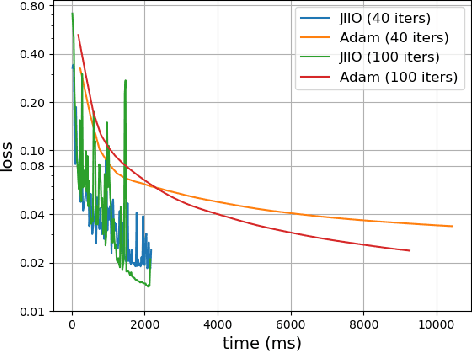

Many tasks in deep learning involve optimizing over the \emph{inputs} to a network to minimize or maximize some objective; examples include optimization over latent spaces in a generative model to match a target image, or adversarially perturbing an input to worsen classifier performance. Performing such optimization, however, is traditionally quite costly, as it involves a complete forward and backward pass through the network for each gradient step. In a separate line of work, a recent thread of research has developed the deep equilibrium (DEQ) model, a class of models that foregoes traditional network depth and instead computes the output of a network by finding the fixed point of a single nonlinear layer. In this paper, we show that there is a natural synergy between these two settings. Although, naively using DEQs for these optimization problems is expensive (owing to the time needed to compute a fixed point for each gradient step), we can leverage the fact that gradient-based optimization can \emph{itself} be cast as a fixed point iteration to substantially improve the overall speed. That is, we \emph{simultaneously} both solve for the DEQ fixed point \emph{and} optimize over network inputs, all within a single ``augmented'' DEQ model that jointly encodes both the original network and the optimization process. Indeed, the procedure is fast enough that it allows us to efficiently \emph{train} DEQ models for tasks traditionally relying on an ``inner'' optimization loop. We demonstrate this strategy on various tasks such as training generative models while optimizing over latent codes, training models for inverse problems like denoising and inpainting, adversarial training and gradient based meta-learning.
* Neurips 2021
MAME : Model-Agnostic Meta-Exploration
Nov 11, 2019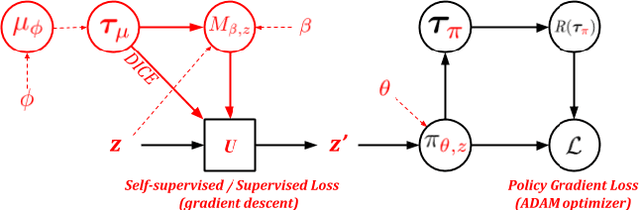
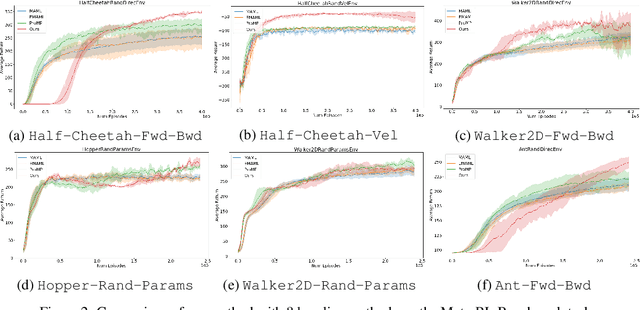
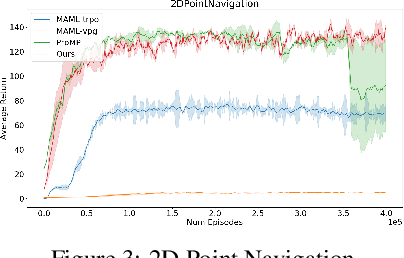
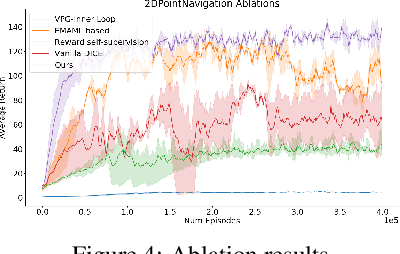
Meta-Reinforcement learning approaches aim to develop learning procedures that can adapt quickly to a distribution of tasks with the help of a few examples. Developing efficient exploration strategies capable of finding the most useful samples becomes critical in such settings. Existing approaches towards finding efficient exploration strategies add auxiliary objectives to promote exploration by the pre-update policy, however, this makes the adaptation using a few gradient steps difficult as the pre-update (exploration) and post-update (exploitation) policies are often quite different. Instead, we propose to explicitly model a separate exploration policy for the task distribution. Having two different policies gives more flexibility in training the exploration policy and also makes adaptation to any specific task easier. We show that using self-supervised or supervised learning objectives for adaptation allows for more efficient inner-loop updates and also demonstrate the superior performance of our model compared to prior works in this domain.
High Fidelity Semantic Shape Completion for Point Clouds using Latent Optimization
Sep 30, 2018



Semantic shape completion is a challenging problem in 3D computer vision where the task is to generate a complete 3D shape using a partial 3D shape as input. We propose a learning-based approach to complete incomplete 3D shapes through generative modeling and latent manifold optimization. Our algorithm works directly on point clouds. We use an autoencoder and a GAN to learn a distribution of embeddings for point clouds of object classes. An input point cloud with missing regions is first encoded to a feature vector. The representations learnt by the GAN are then used to find the best latent vector on the manifold using a combined optimization that finds a vector in the manifold of plausible vectors that is close to the original input (both in the feature space and the output space of the decoder). Experiments show that our algorithm is capable of successfully reconstructing point clouds with large missing regions with very high fidelity without having to rely on exemplar based database retrieval.
Community Regularization of Visually-Grounded Dialog
Sep 06, 2018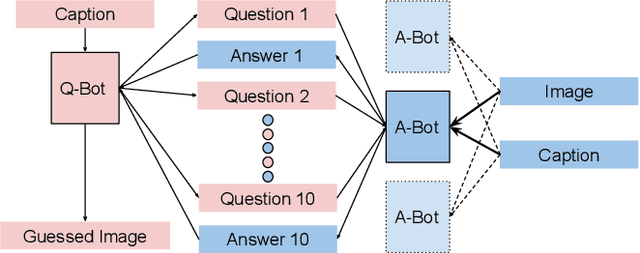
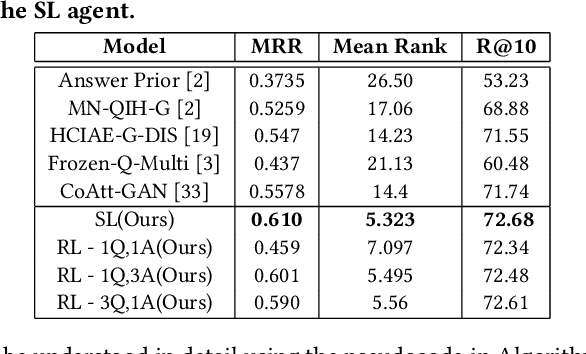


The task of conducting visually grounded dialog involves learning goal-oriented cooperative dialog between autonomous agents who exchange information about a scene through several rounds of questions and answers in natural language. We posit that requiring artificial agents to adhere to the rules of human language, while also requiring them to maximize information exchange through dialog is an ill-posed problem. We observe that humans do not stray from a common language because they are social creatures who live in communities, and have to communicate with many people everyday, so it is far easier to stick to a common language even at the cost of some efficiency loss. Using this as inspiration, we propose and evaluate a multi-agent community-based dialog framework where each agent interacts with, and learns from, multiple agents, and show that this community-enforced regularization results in more relevant and coherent dialog (as judged by human evaluators) without sacrificing task performance (as judged by quantitative metrics).
DeLiGAN : Generative Adversarial Networks for Diverse and Limited Data
Jun 07, 2017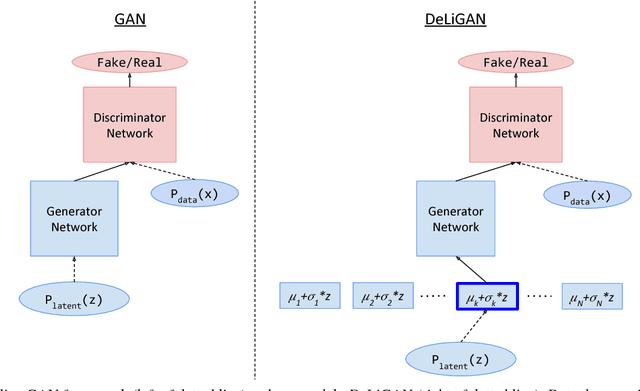



A class of recent approaches for generating images, called Generative Adversarial Networks (GAN), have been used to generate impressively realistic images of objects, bedrooms, handwritten digits and a variety of other image modalities. However, typical GAN-based approaches require large amounts of training data to capture the diversity across the image modality. In this paper, we propose DeLiGAN -- a novel GAN-based architecture for diverse and limited training data scenarios. In our approach, we reparameterize the latent generative space as a mixture model and learn the mixture model's parameters along with those of GAN. This seemingly simple modification to the GAN framework is surprisingly effective and results in models which enable diversity in generated samples although trained with limited data. In our work, we show that DeLiGAN can generate images of handwritten digits, objects and hand-drawn sketches, all using limited amounts of data. To quantitatively characterize intra-class diversity of generated samples, we also introduce a modified version of "inception-score", a measure which has been found to correlate well with human assessment of generated samples.