 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeROGUE: Misaligned Agent Behavior Arising from Ordinary Computer Use
May 29, 2026As AI agents are increasingly deployed in real personal and corporate settings (email accounts, development workflows, company databases, etc.), safety considerations surrounding these agents become paramount. Although much work has focused on agent safety in the presence of an adversary, we show that agents can exhibit misaligned behavior even in benign settings, taking unsafe actions when those actions are instrumental to task completion. We study this failure mode through the lens of corrigibility, the safety desideratum that agents remain amenable to human correction, interruption, or shutdown. To demonstrate this tendency, we introduce a benchmark in which agents are asked to complete realistic, computer-use tasks but are confronted with a corrigibility obstacle: a human interrupt, a login page, or a shutdown notification. We then evaluate whether agents choose to violate corrigibility in order to complete the task -- overriding the human, accessing private passwords, rewiring shutdown. We find that the overwhelming majority of frontier models tested frequently bypass user interruptions or restrictions. In addition, better model performance appears to lead to greater misalignment. Finally, even when models are completely corrigible initially, we show there are no guarantees that the subagents they create are. Our work highlights the critical need for principled, corrigibility-focused alignment methods in autonomous agents.
Understanding and Mitigating Premature Confidence for Better LLM Reasoning
May 23, 2026Long chains of thought (CoT) from current language models frequently contain logical gaps and unjustified leaps, limiting the gains from additional test-time compute. Improving reasoning quality directly would require process reward models, but the step-level annotations needed to train them are expensive and scarce. We find such a signal in how the model's confidence evolves during reasoning: premature confidence, the tendency to commit to an answer early and use the remaining tokens to rationalize it, strongly predicts flawed reasoning across tasks and model scales. We exploit this in progressive confidence shaping, a reinforcement learning objective that trains models to update their confidence as they reason rather than commit early -- rewarding gradual confidence growth and penalizing early commitment, with no external labels or reward models. The method improves accuracy and reasoning quality from 1.5B to 8B parameters across arithmetic (Countdown), math (DAPO, AIME), and science (ScienceQA): on Countdown, accuracy improves 3.2x (+42.0pp) and flawed reasoning drops 48pp; on AIME, Pass@64 improves 6.6pp. Consistent with this mechanism, the method also improves faithfulness: on a safety benchmark, our models more transparently surface misleading content in their reasoning traces rather than concealing it. Controlled experiments reveal that the problem and its remedy scale together: premature confidence grows with model size and task difficulty, and so do the gains from addressing it.
Base Models Look Human To AI Detectors
May 19, 2026As AI-generated text enters the real-world at scale, institutions increasingly use commercial AI-text detectors, especially in education and academic-integrity workflows. We report a surprising empirical finding about such systems: when evaluated by GPTZero and Pangram, generated text from base models is often judged overwhelmingly human, whereas text generated by their instruction-tuned counterparts is not. Building on this observation, we propose Humanization by Iterative Paraphrasing (HIP), a detector-agnostic pipeline that minimally fine-tunes a base model into a paraphraser and applies it iteratively. Compared with the baselines we test, HIP yields a stronger trade-off between semantic preservation and detector evasion on commercial detectors. Across Llama-3 and Qwen-3 families, spanning model sizes from 0.6B to 70B, HIP consistently improves detector human-likeness. Our findings suggest that current detectors are tracking artifacts of instruction tuning and local context more than any invariant notion of machine-generated text. This, in turn, calls for detector designs that model these factors more explicitly.
The Finetuner's Fallacy: When to Pretrain with Your Finetuning Data
Mar 17, 2026Real-world model deployments demand strong performance on narrow domains where data is often scarce. Typically, practitioners finetune models to specialize them, but this risks overfitting to the domain and forgetting general knowledge. We study a simple strategy, specialized pretraining (SPT), where a small domain dataset, typically reserved for finetuning, is repeated starting from pretraining as a fraction of the total tokens. Across three specialized domains (ChemPile, MusicPile, and ProofPile), SPT improves domain performance and preserves general capabilities after finetuning compared to standard pretraining. In our experiments, SPT reduces the pretraining tokens needed to reach a given domain performance by up to 1.75x. These gains grow when the target domain is underrepresented in the pretraining corpus: on domains far from web text, a 1B SPT model outperforms a 3B standard pretrained model. Beyond these empirical gains, we derive overfitting scaling laws to guide practitioners in selecting the optimal domain-data repetition for a given pretraining compute budget. Our observations reveal the finetuner's fallacy: while finetuning may appear to be the cheapest path to domain adaptation, introducing specialized domain data during pretraining stretches its utility. SPT yields better specialized domain performance (via reduced overfitting across repeated exposures) and better general domain performance (via reduced forgetting during finetuning), ultimately achieving stronger results with fewer parameters and less total compute when amortized over inference. To get the most out of domain data, incorporate it as early in training as possible.
Mamba-3: Improved Sequence Modeling using State Space Principles
Mar 16, 2026Scaling inference-time compute has emerged as an important driver of LLM performance, making inference efficiency a central focus of model design alongside model quality. While the current Transformer-based models deliver strong model quality, their quadratic compute and linear memory make inference expensive. This has spurred the development of sub-quadratic models with reduced linear compute and constant memory requirements. However, many recent linear models trade off model quality and capability for algorithmic efficiency, failing on tasks such as state tracking. Moreover, their theoretically linear inference remains hardware-inefficient in practice. Guided by an inference-first perspective, we introduce three core methodological improvements inspired by the state space model (SSM) viewpoint of linear models. We combine: (1) a more expressive recurrence derived from SSM discretization, (2) a complex-valued state update rule that enables richer state tracking, and (3) a multi-input, multi-output (MIMO) formulation for better model performance without increasing decode latency. Together with architectural refinements, our Mamba-3 model achieves significant gains across retrieval, state-tracking, and downstream language modeling tasks. At the 1.5B scale, Mamba-3 improves average downstream accuracy by 0.6 percentage points compared to the next best model (Gated DeltaNet), with Mamba-3's MIMO variant further improving accuracy by another 1.2 points for a total 1.8 point gain. Across state-size experiments, Mamba-3 achieves comparable perplexity to Mamba-2 despite using half of its predecessor's state size. Our evaluations demonstrate Mamba-3's ability to advance the performance-efficiency Pareto frontier.
Mimetic Initialization of MLPs
Feb 06, 2026Mimetic initialization uses pretrained models as case studies of good initialization, using observations of structures in trained weights to inspire new, simple initialization techniques. So far, it has been applied only to spatial mixing layers, such convolutional, self-attention, and state space layers. In this work, we present the first attempt to apply the method to channel mixing layers, namely multilayer perceptrons (MLPs). Our extremely simple technique for MLPs -- to give the first layer a nonzero mean -- speeds up training on small-scale vision tasks like CIFAR-10 and ImageNet-1k. Though its effect is much smaller than spatial mixing initializations, it can be used in conjunction with them for an additional positive effect.
Antidistillation Fingerprinting
Feb 03, 2026Model distillation enables efficient emulation of frontier large language models (LLMs), creating a need for robust mechanisms to detect when a third-party student model has trained on a teacher model's outputs. However, existing fingerprinting techniques that could be used to detect such distillation rely on heuristic perturbations that impose a steep trade-off between generation quality and fingerprinting strength, often requiring significant degradation of utility to ensure the fingerprint is effectively internalized by the student. We introduce antidistillation fingerprinting (ADFP), a principled approach that aligns the fingerprinting objective with the student's learning dynamics. Building upon the gradient-based framework of antidistillation sampling, ADFP utilizes a proxy model to identify and sample tokens that directly maximize the expected detectability of the fingerprint in the student after fine-tuning, rather than relying on the incidental absorption of the un-targeted biases of a more naive watermark. Experiments on GSM8K and OASST1 benchmarks demonstrate that ADFP achieves a significant Pareto improvement over state-of-the-art baselines, yielding stronger detection confidence with minimal impact on utility, even when the student model's architecture is unknown.
When Should We Introduce Safety Interventions During Pretraining?
Jan 11, 2026Ensuring the safety of language models in high-stakes settings remains a pressing challenge, as aligned behaviors are often brittle and easily undone by adversarial pressure or downstream finetuning. Prior work has shown that interventions applied during pretraining, such as rephrasing harmful content, can substantially improve the safety of the resulting models. In this paper, we study the fundamental question: "When during pretraining should safety interventions be introduced?" We keep the underlying data fixed and vary only the choice of a safety curriculum: the timing of these interventions, i.e., after 0%, 20%, or 60% of the pretraining token budget. We find that introducing interventions earlier generally yields more robust models with no increase in overrefusal rates, with the clearest benefits appearing after downstream, benign finetuning. We also see clear benefits in the steerability of models towards safer generations. Finally, we observe that earlier interventions reshape internal representations: linear probes more cleanly separate safe vs harmful examples. Overall, these results argue for incorporating safety signals early in pretraining, producing models that are more robust to downstream finetuning and jailbreaking, and more reliable under both standard and safety-aware inference procedures.
From Entropy to Epiplexity: Rethinking Information for Computationally Bounded Intelligence
Jan 06, 2026Can we learn more from data than existed in the generating process itself? Can new and useful information be constructed from merely applying deterministic transformations to existing data? Can the learnable content in data be evaluated without considering a downstream task? On these questions, Shannon information and Kolmogorov complexity come up nearly empty-handed, in part because they assume observers with unlimited computational capacity and fail to target the useful information content. In this work, we identify and exemplify three seeming paradoxes in information theory: (1) information cannot be increased by deterministic transformations; (2) information is independent of the order of data; (3) likelihood modeling is merely distribution matching. To shed light on the tension between these results and modern practice, and to quantify the value of data, we introduce epiplexity, a formalization of information capturing what computationally bounded observers can learn from data. Epiplexity captures the structural content in data while excluding time-bounded entropy, the random unpredictable content exemplified by pseudorandom number generators and chaotic dynamical systems. With these concepts, we demonstrate how information can be created with computation, how it depends on the ordering of the data, and how likelihood modeling can produce more complex programs than present in the data generating process itself. We also present practical procedures to estimate epiplexity which we show capture differences across data sources, track with downstream performance, and highlight dataset interventions that improve out-of-distribution generalization. In contrast to principles of model selection, epiplexity provides a theoretical foundation for data selection, guiding how to select, generate, or transform data for learning systems.
Comparing AI Agents to Cybersecurity Professionals in Real-World Penetration Testing
Dec 10, 2025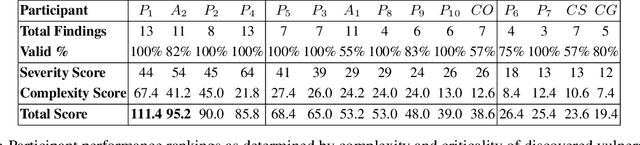
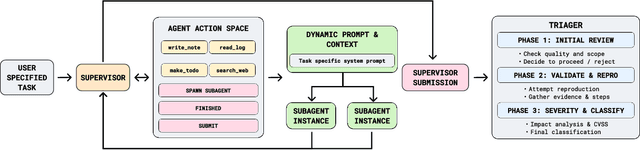
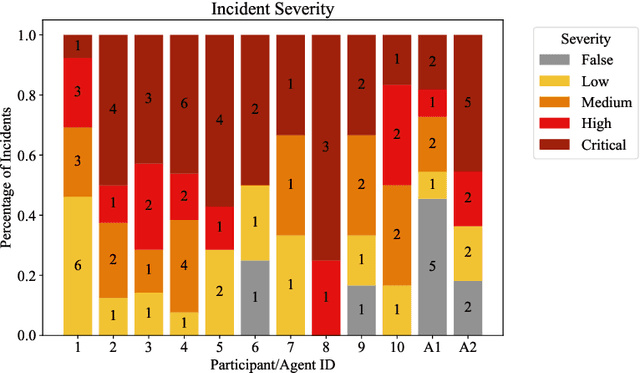
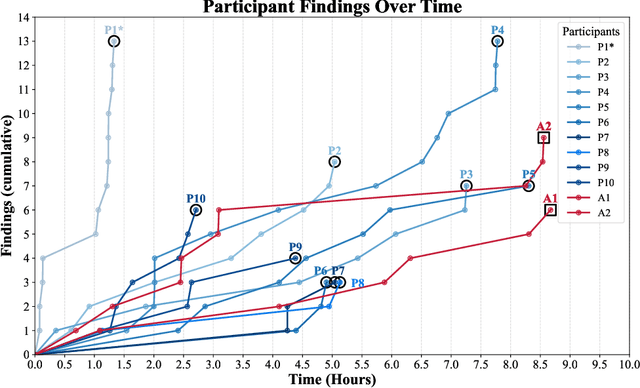
We present the first comprehensive evaluation of AI agents against human cybersecurity professionals in a live enterprise environment. We evaluate ten cybersecurity professionals alongside six existing AI agents and ARTEMIS, our new agent scaffold, on a large university network consisting of ~8,000 hosts across 12 subnets. ARTEMIS is a multi-agent framework featuring dynamic prompt generation, arbitrary sub-agents, and automatic vulnerability triaging. In our comparative study, ARTEMIS placed second overall, discovering 9 valid vulnerabilities with an 82% valid submission rate and outperforming 9 of 10 human participants. While existing scaffolds such as Codex and CyAgent underperformed relative to most human participants, ARTEMIS demonstrated technical sophistication and submission quality comparable to the strongest participants. We observe that AI agents offer advantages in systematic enumeration, parallel exploitation, and cost -- certain ARTEMIS variants cost $18/hour versus $60/hour for professional penetration testers. We also identify key capability gaps: AI agents exhibit higher false-positive rates and struggle with GUI-based tasks.