 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReevaluating Policy Gradient Methods for Imperfect-Information Games
Feb 13, 2025In the past decade, motivated by the putative failure of naive self-play deep reinforcement learning (DRL) in adversarial imperfect-information games, researchers have developed numerous DRL algorithms based on fictitious play (FP), double oracle (DO), and counterfactual regret minimization (CFR). In light of recent results of the magnetic mirror descent algorithm, we hypothesize that simpler generic policy gradient methods like PPO are competitive with or superior to these FP, DO, and CFR-based DRL approaches. To facilitate the resolution of this hypothesis, we implement and release the first broadly accessible exact exploitability computations for four large games. Using these games, we conduct the largest-ever exploitability comparison of DRL algorithms for imperfect-information games. Over 5600 training runs, FP, DO, and CFR-based approaches fail to outperform generic policy gradient methods. Code is available at https://github.com/nathanlct/IIG-RL-Benchmark and https://github.com/gabrfarina/exp-a-spiel .
Optimizing Mixed Autonomy Traffic Flow With Decentralized Autonomous Vehicles and Multi-Agent RL
Oct 30, 2020
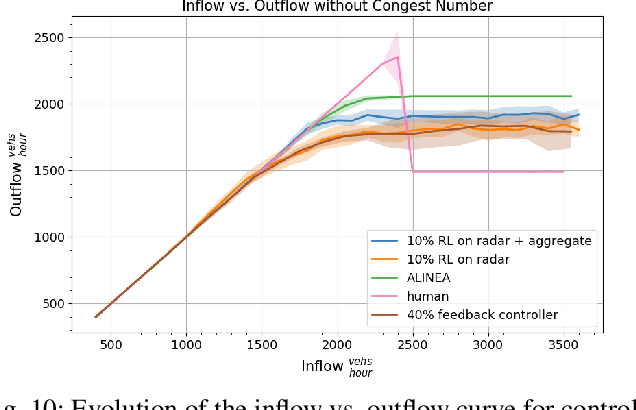
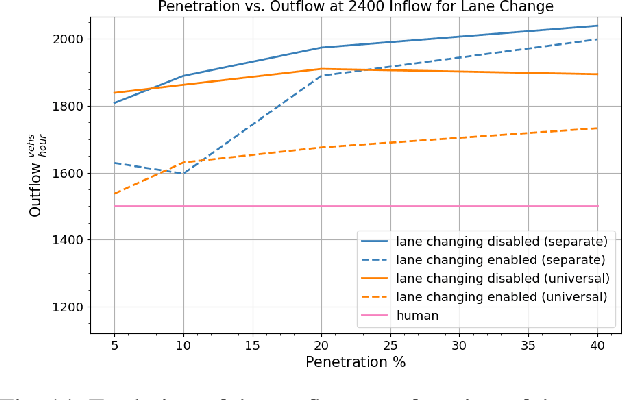
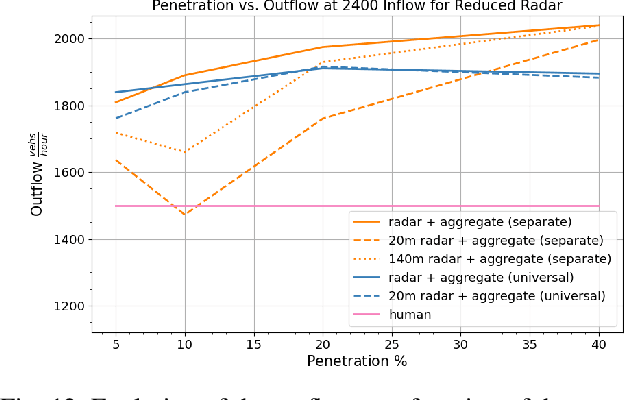
We study the ability of autonomous vehicles to improve the throughput of a bottleneck using a fully decentralized control scheme in a mixed autonomy setting. We consider the problem of improving the throughput of a scaled model of the San Francisco-Oakland Bay Bridge: a two-stage bottleneck where four lanes reduce to two and then reduce to one. Although there is extensive work examining variants of bottleneck control in a centralized setting, there is less study of the challenging multi-agent setting where the large number of interacting AVs leads to significant optimization difficulties for reinforcement learning methods. We apply multi-agent reinforcement algorithms to this problem and demonstrate that significant improvements in bottleneck throughput, from 20\% at a 5\% penetration rate to 33\% at a 40\% penetration rate, can be achieved. We compare our results to a hand-designed feedback controller and demonstrate that our results sharply outperform the feedback controller despite extensive tuning. Additionally, we demonstrate that the RL-based controllers adopt a robust strategy that works across penetration rates whereas the feedback controllers degrade immediately upon penetration rate variation. We investigate the feasibility of both action and observation decentralization and demonstrate that effective strategies are possible using purely local sensing. Finally, we open-source our code at https://github.com/eugenevinitsky/decentralized_bottlenecks.
Inter-Level Cooperation in Hierarchical Reinforcement Learning
Dec 05, 2019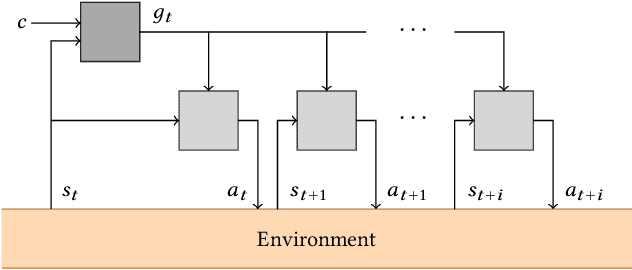
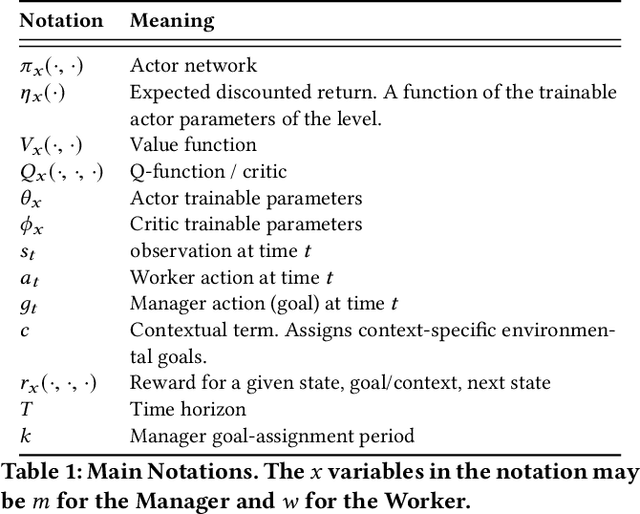


This article presents a novel algorithm for promoting cooperation between internal actors in a goal-conditioned hierarchical reinforcement learning (HRL) policy. Current techniques for HRL policy optimization treat the higher and lower level policies as separate entities which are trained to maximize different objective functions, rendering the HRL problem formulation more similar to a general sum game than a single-agent task. Within this setting, we hypothesize that improved cooperation between the internal agents of a hierarchy can simplify the credit assignment problem from the perspective of the high-level policies, thereby leading to significant improvements to training in situations where intricate sets of action primitives must be performed to yield improvements in performance. In order to promote cooperation within this setting, we propose the inclusion of a connected gradient term to the gradient computations of the higher level policies. Our method is demonstrated to achieve superior results to existing techniques in a set of difficult long time horizon tasks.