 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised and Unsupervised Neural Network Solver for First Order Hyperbolic Nonlinear PDEs
Jan 10, 2026We present a neural network-based method for learning scalar hyperbolic conservation laws. Our method replaces the traditional numerical flux in finite volume schemes with a trainable neural network while preserving the conservative structure of the scheme. The model can be trained both in a supervised setting with efficiently generated synthetic data or in an unsupervised manner, leveraging the weak formulation of the partial differential equation. We provide theoretical results that our model can perform arbitrarily well, and provide associated upper bounds on neural network size. Extensive experiments demonstrate that our method often outperforms efficient schemes such as Godunov's scheme, WENO, and Discontinuous Galerkin for comparable computational budgets. Finally, we demonstrate the effectiveness of our method on a traffic prediction task, leveraging field experimental highway data from the Berkeley DeepDrive drone dataset.
(U)NFV: Supervised and Unsupervised Neural Finite Volume Methods for Solving Hyperbolic PDEs
May 29, 2025We introduce (U)NFV, a modular neural network architecture that generalizes classical finite volume (FV) methods for solving hyperbolic conservation laws. Hyperbolic partial differential equations (PDEs) are challenging to solve, particularly conservation laws whose physically relevant solutions contain shocks and discontinuities. FV methods are widely used for their mathematical properties: convergence to entropy solutions, flow conservation, or total variation diminishing, but often lack accuracy and flexibility in complex settings. Neural Finite Volume addresses these limitations by learning update rules over extended spatial and temporal stencils while preserving conservation structure. It supports both supervised training on solution data (NFV) and unsupervised training via weak-form residual loss (UNFV). Applied to first-order conservation laws, (U)NFV achieves up to 10x lower error than Godunov's method, outperforms ENO/WENO, and rivals discontinuous Galerkin solvers with far less complexity. On traffic modeling problems, both from PDEs and from experimental highway data, (U)NFV captures nonlinear wave dynamics with significantly higher fidelity and scalability than traditional FV approaches.
Pareto Control Barrier Function for Inner Safe Set Maximization Under Input Constraints
Oct 05, 2024



This article introduces the Pareto Control Barrier Function (PCBF) algorithm to maximize the inner safe set of dynamical systems under input constraints. Traditional Control Barrier Functions (CBFs) ensure safety by maintaining system trajectories within a safe set but often fail to account for realistic input constraints. To address this problem, we leverage the Pareto multi-task learning framework to balance competing objectives of safety and safe set volume. The PCBF algorithm is applicable to high-dimensional systems and is computationally efficient. We validate its effectiveness through comparison with Hamilton-Jacobi reachability for an inverted pendulum and through simulations on a 12-dimensional quadrotor system. Results show that the PCBF consistently outperforms existing methods, yielding larger safe sets and ensuring safety under input constraints.
Reinforcement Learning Based Oscillation Dampening: Scaling up Single-Agent RL algorithms to a 100 AV highway field operational test
Feb 26, 2024In this article, we explore the technical details of the reinforcement learning (RL) algorithms that were deployed in the largest field test of automated vehicles designed to smooth traffic flow in history as of 2023, uncovering the challenges and breakthroughs that come with developing RL controllers for automated vehicles. We delve into the fundamental concepts behind RL algorithms and their application in the context of self-driving cars, discussing the developmental process from simulation to deployment in detail, from designing simulators to reward function shaping. We present the results in both simulation and deployment, discussing the flow-smoothing benefits of the RL controller. From understanding the basics of Markov decision processes to exploring advanced techniques such as deep RL, our article offers a comprehensive overview and deep dive of the theoretical foundations and practical implementations driving this rapidly evolving field. We also showcase real-world case studies and alternative research projects that highlight the impact of RL controllers in revolutionizing autonomous driving. From tackling complex urban environments to dealing with unpredictable traffic scenarios, these intelligent controllers are pushing the boundaries of what automated vehicles can achieve. Furthermore, we examine the safety considerations and hardware-focused technical details surrounding deployment of RL controllers into automated vehicles. As these algorithms learn and evolve through interactions with the environment, ensuring their behavior aligns with safety standards becomes crucial. We explore the methodologies and frameworks being developed to address these challenges, emphasizing the importance of building reliable control systems for automated vehicles.
Traffic Smoothing Controllers for Autonomous Vehicles Using Deep Reinforcement Learning and Real-World Trajectory Data
Jan 18, 2024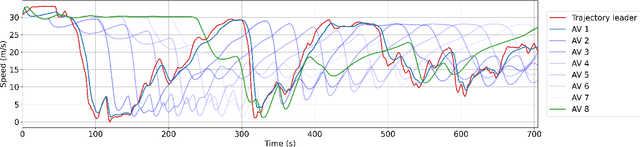
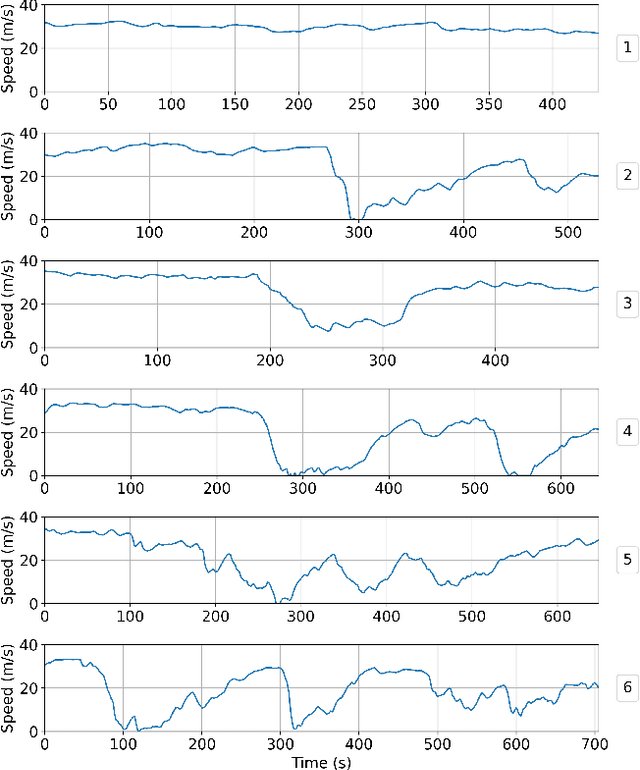
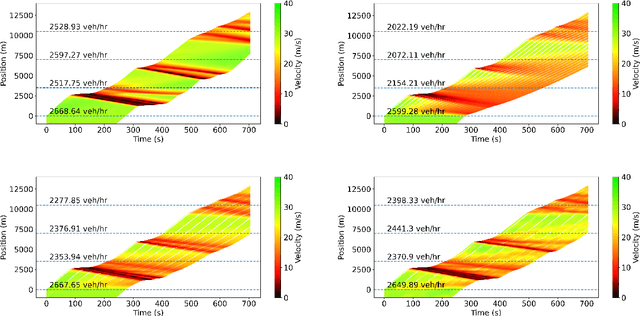
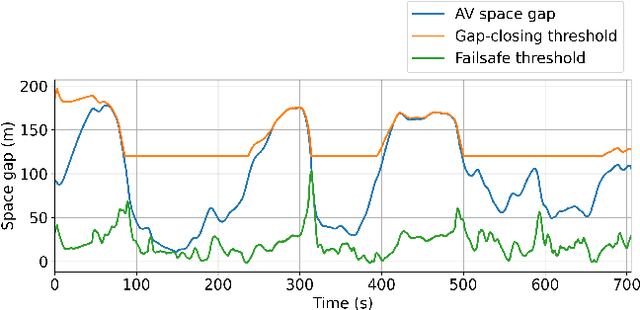
Designing traffic-smoothing cruise controllers that can be deployed onto autonomous vehicles is a key step towards improving traffic flow, reducing congestion, and enhancing fuel efficiency in mixed autonomy traffic. We bypass the common issue of having to carefully fine-tune a large traffic microsimulator by leveraging real-world trajectory data from the I-24 highway in Tennessee, replayed in a one-lane simulation. Using standard deep reinforcement learning methods, we train energy-reducing wave-smoothing policies. As an input to the agent, we observe the speed and distance of only the vehicle in front, which are local states readily available on most recent vehicles, as well as non-local observations about the downstream state of the traffic. We show that at a low 4% autonomous vehicle penetration rate, we achieve significant fuel savings of over 15% on trajectories exhibiting many stop-and-go waves. Finally, we analyze the smoothing effect of the controllers and demonstrate robustness to adding lane-changing into the simulation as well as the removal of downstream information.
Unified Automatic Control of Vehicular Systems with Reinforcement Learning
Jul 30, 2022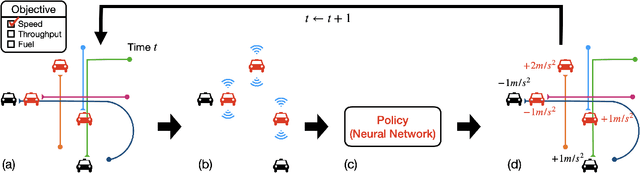
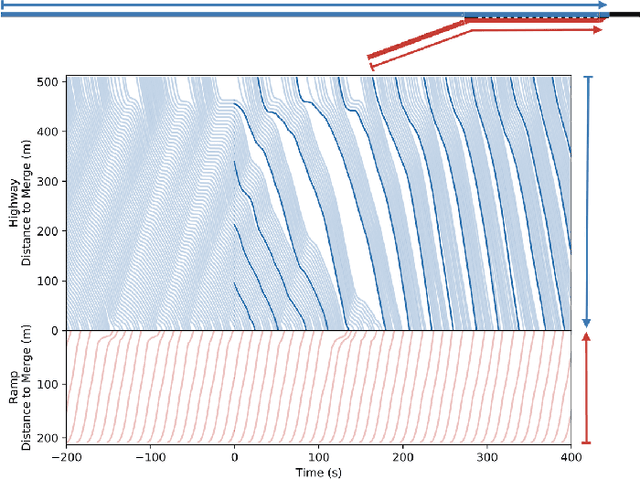
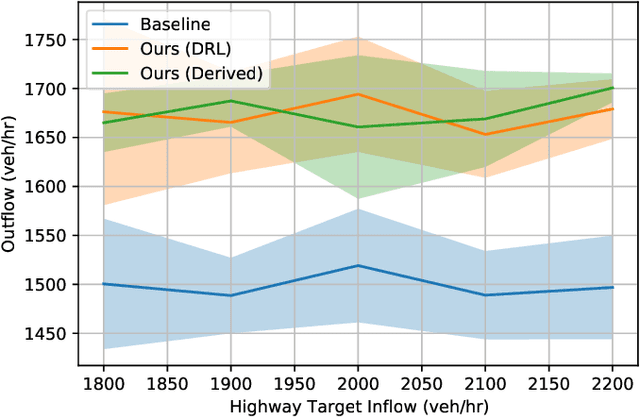

Emerging vehicular systems with increasing proportions of automated components present opportunities for optimal control to mitigate congestion and increase efficiency. There has been a recent interest in applying deep reinforcement learning (DRL) to these nonlinear dynamical systems for the automatic design of effective control strategies. Despite conceptual advantages of DRL being model-free, studies typically nonetheless rely on training setups that are painstakingly specialized to specific vehicular systems. This is a key challenge to efficient analysis of diverse vehicular and mobility systems. To this end, this article contributes a streamlined methodology for vehicular microsimulation and discovers high performance control strategies with minimal manual design. A variable-agent, multi-task approach is presented for optimization of vehicular Partially Observed Markov Decision Processes. The methodology is experimentally validated on mixed autonomy traffic systems, where fractions of vehicles are automated; empirical improvement, typically 15-60% over a human driving baseline, is observed in all configurations of six diverse open or closed traffic systems. The study reveals numerous emergent behaviors resembling wave mitigation, traffic signaling, and ramp metering. Finally, the emergent behaviors are analyzed to produce interpretable control strategies, which are validated against the learned control strategies.
Reachability Analysis for FollowerStopper: Safety Analysis and Experimental Results
Dec 29, 2021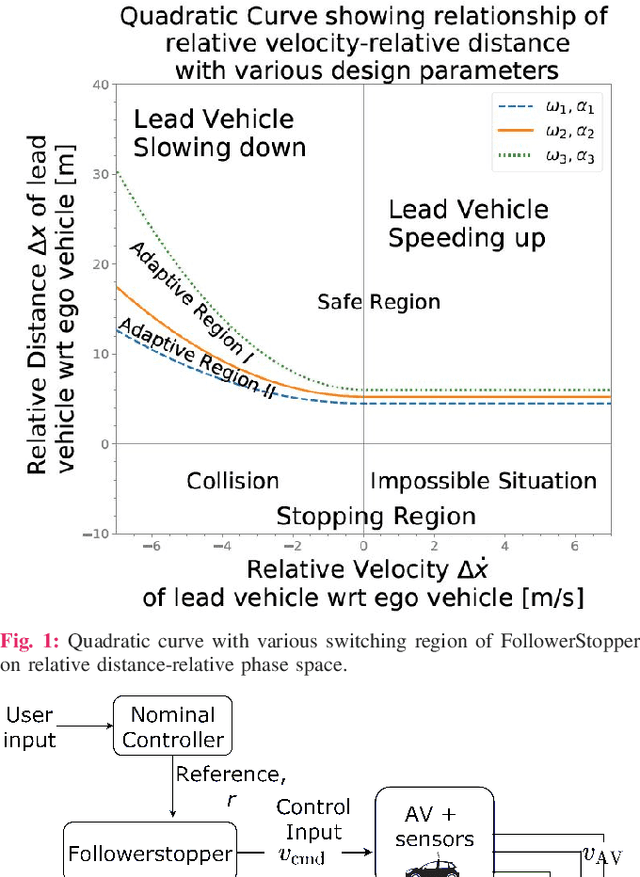
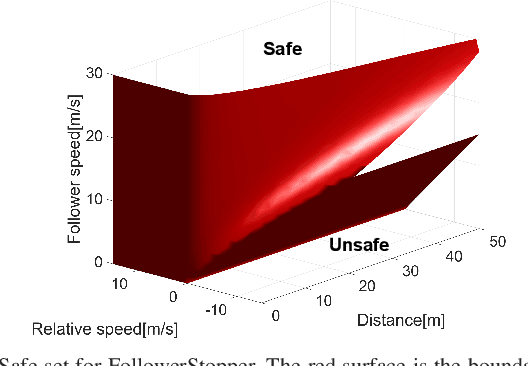
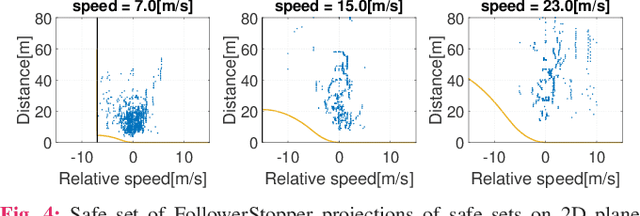
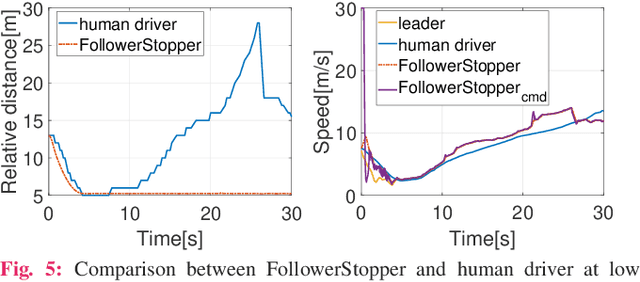
Motivated by earlier work and the developer of a new algorithm, the FollowerStopper, this article uses reachability analysis to verify the safety of the FollowerStopper algorithm, which is a controller designed for dampening stop- and-go traffic waves. With more than 1100 miles of driving data collected by our physical platform, we validate our analysis results by comparing it to human driving behaviors. The FollowerStopper controller has been demonstrated to dampen stop-and-go traffic waves at low speed, but previous analysis on its relative safety has been limited to upper and lower bounds of acceleration. To expand upon previous analysis, reachability analysis is used to investigate the safety at the speeds it was originally tested and also at higher speeds. Two formulations of safety analysis with different criteria are shown: distance-based and time headway-based. The FollowerStopper is considered safe with distance-based criterion. However, simulation results demonstrate that the FollowerStopper is not representative of human drivers - it follows too closely behind vehicles, specifically at a distance human would deem as unsafe. On the other hand, under the time headway-based safety analysis, the FollowerStopper is not considered safe anymore. A modified FollowerStopper is proposed to satisfy time-based safety criterion. Simulation results of the proposed FollowerStopper shows that its response represents human driver behavior better.
Failout: Achieving Failure-Resilient Inference in Distributed Neural Networks
Feb 18, 2020
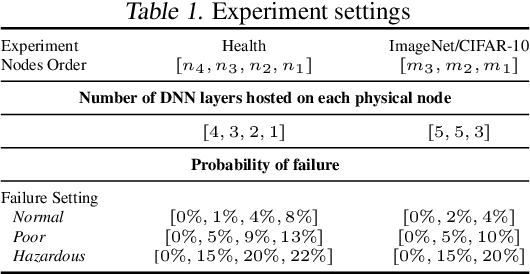

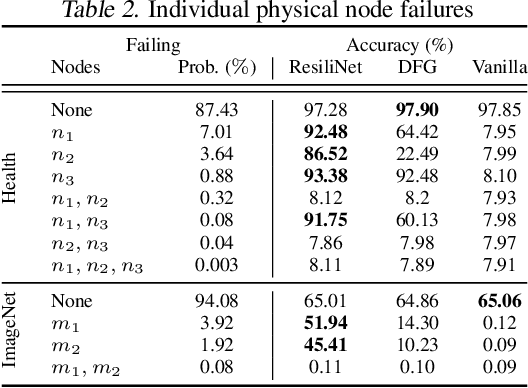
When a neural network is partitioned and distributed across physical nodes, failure of physical nodes causes the failure of the neural units that are placed on those nodes, which results in a significant performance drop. Current approaches focus on resiliency of training in distributed neural networks. However, resiliency of inference in distributed neural networks is less explored. We introduce ResiliNet, a scheme for making inference in distributed neural networks resilient to physical node failures. ResiliNet combines two concepts to provide resiliency: skip connection in residual neural networks, and a novel technique called failout, which is introduced in this paper. Failout simulates physical node failure conditions during training using dropout, and is specifically designed to improve the resiliency of distributed neural networks. The results of the experiments and ablation studies using three datasets confirm the ability of ResiliNet to provide inference resiliency for distributed neural networks.
Inter-Level Cooperation in Hierarchical Reinforcement Learning
Dec 05, 2019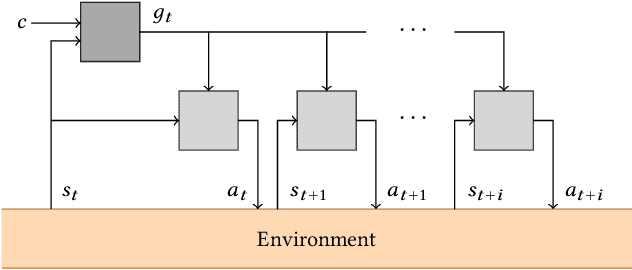
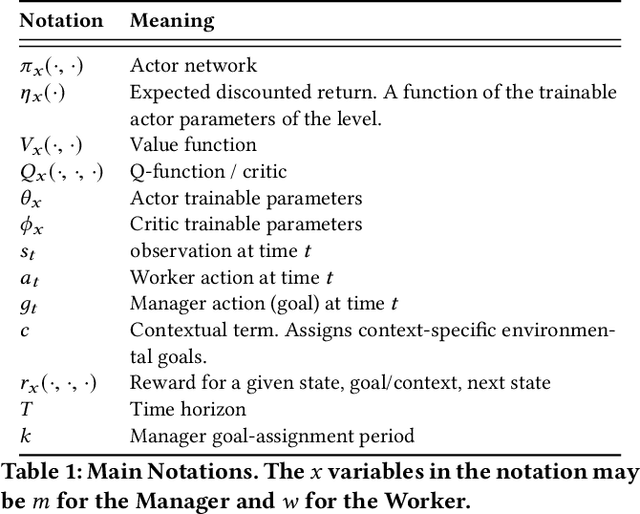


This article presents a novel algorithm for promoting cooperation between internal actors in a goal-conditioned hierarchical reinforcement learning (HRL) policy. Current techniques for HRL policy optimization treat the higher and lower level policies as separate entities which are trained to maximize different objective functions, rendering the HRL problem formulation more similar to a general sum game than a single-agent task. Within this setting, we hypothesize that improved cooperation between the internal agents of a hierarchy can simplify the credit assignment problem from the perspective of the high-level policies, thereby leading to significant improvements to training in situations where intricate sets of action primitives must be performed to yield improvements in performance. In order to promote cooperation within this setting, we propose the inclusion of a connected gradient term to the gradient computations of the higher level policies. Our method is demonstrated to achieve superior results to existing techniques in a set of difficult long time horizon tasks.
Guardians of the Deep Fog: Failure-Resilient DNN Inference from Edge to Cloud
Sep 21, 2019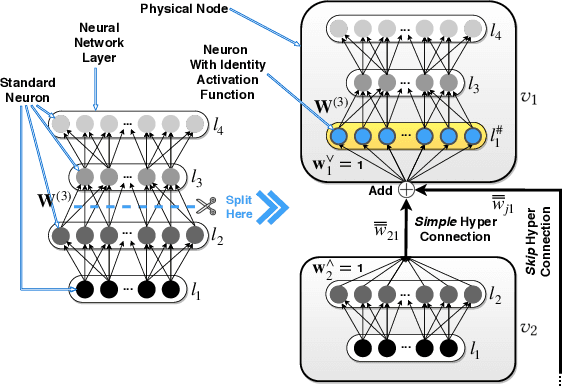

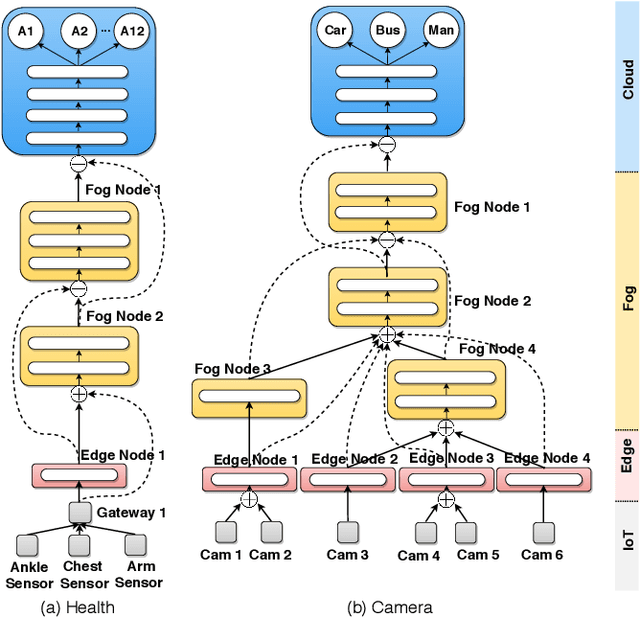
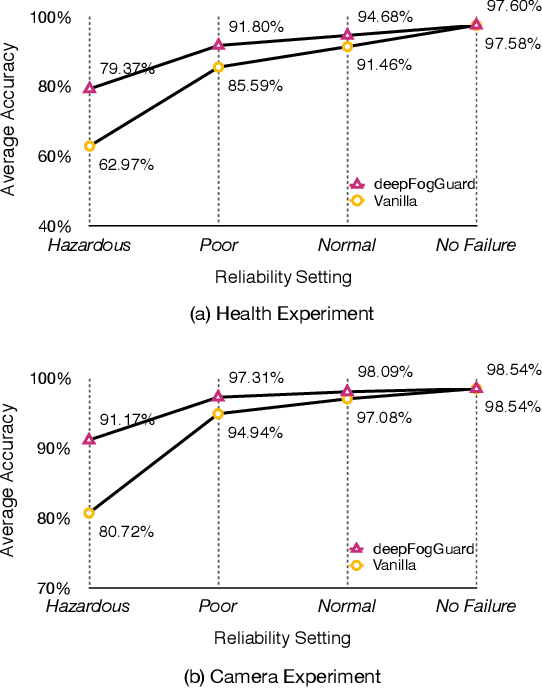
Partitioning and distributing deep neural networks (DNNs) over physical nodes such as edge, fog, or cloud nodes, could enhance sensor fusion, and reduce bandwidth and inference latency. However, when a DNN is distributed over physical nodes, failure of the physical nodes causes the failure of the DNN units that are placed on these nodes. The performance of the inference task will be unpredictable, and most likely, poor, if the distributed DNN is not specifically designed and properly trained for failures. Motivated by this, we introduce deepFogGuard, a DNN architecture augmentation scheme for making the distributed DNN inference task failure-resilient. To articulate deepFogGuard, we introduce the elements and a model for the resiliency of distributed DNN inference. Inspired by the concept of residual connections in DNNs, we introduce skip hyperconnections in distributed DNNs, which are the basis of deepFogGuard's design to provide resiliency. Next, our extensive experiments using two existing datasets for the sensing and vision applications confirm the ability of deepFogGuard to provide resiliency for distributed DNNs in edge-cloud networks.