 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFastPersist: Accelerating Model Checkpointing in Deep Learning
Jun 19, 2024



Model checkpoints are critical Deep Learning (DL) artifacts that enable fault tolerance for training and downstream applications, such as inference. However, writing checkpoints to persistent storage, and other I/O aspects of DL training, are mostly ignored by compute-focused optimization efforts for faster training of rapidly growing models and datasets. Towards addressing this imbalance, we propose FastPersist to accelerate checkpoint creation in DL training. FastPersist combines three novel techniques: (i) NVMe optimizations for faster checkpoint writes to SSDs, (ii) efficient write parallelism using the available SSDs in training environments, and (iii) overlapping checkpointing with independent training computations. Our evaluation using real world dense and sparse DL models shows that FastPersist creates checkpoints in persistent storage up to 116x faster than baseline, and enables per-iteration checkpointing with negligible overhead.
Artificial Intelligence for Neuro MRI Acquisition: A Review
Jun 10, 2024Magnetic resonance imaging (MRI) has significantly benefited from the resurgence of artificial intelligence (AI). By leveraging AI's capabilities in large-scale optimization and pattern recognition, innovative methods are transforming the MRI acquisition workflow, including planning, sequence design, and correction of acquisition artifacts. These emerging algorithms demonstrate substantial potential in enhancing the efficiency and throughput of acquisition steps. This review discusses several pivotal AI-based methods in neuro MRI acquisition, focusing on their technological advances, impact on clinical practice, and potential risks.
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Apr 23, 2024



We introduce phi-3-mini, a 3.8 billion parameter language model trained on 3.3 trillion tokens, whose overall performance, as measured by both academic benchmarks and internal testing, rivals that of models such as Mixtral 8x7B and GPT-3.5 (e.g., phi-3-mini achieves 69% on MMLU and 8.38 on MT-bench), despite being small enough to be deployed on a phone. The innovation lies entirely in our dataset for training, a scaled-up version of the one used for phi-2, composed of heavily filtered web data and synthetic data. The model is also further aligned for robustness, safety, and chat format. We also provide some initial parameter-scaling results with a 7B and 14B models trained for 4.8T tokens, called phi-3-small and phi-3-medium, both significantly more capable than phi-3-mini (e.g., respectively 75% and 78% on MMLU, and 8.7 and 8.9 on MT-bench).
ZeRO++: Extremely Efficient Collective Communication for Giant Model Training
Jun 16, 2023



Zero Redundancy Optimizer (ZeRO) has been used to train a wide range of large language models on massive GPUs clusters due to its ease of use, efficiency, and good scalability. However, when training on low-bandwidth clusters, or at scale which forces batch size per GPU to be small, ZeRO's effective throughput is limited because of high communication volume from gathering weights in forward pass, backward pass, and averaging gradients. This paper introduces three communication volume reduction techniques, which we collectively refer to as ZeRO++, targeting each of the communication collectives in ZeRO. First is block-quantization based all-gather. Second is data remapping that trades-off communication for more memory. Third is a novel all-to-all based quantized gradient averaging paradigm as replacement of reduce-scatter collective, which preserves accuracy despite communicating low precision data. Collectively, ZeRO++ reduces communication volume of ZeRO by 4x, enabling up to 2.16x better throughput at 384 GPU scale.
Adaptive Sampling for Linear Sensing Systems via Langevin Dynamics
Feb 27, 2023



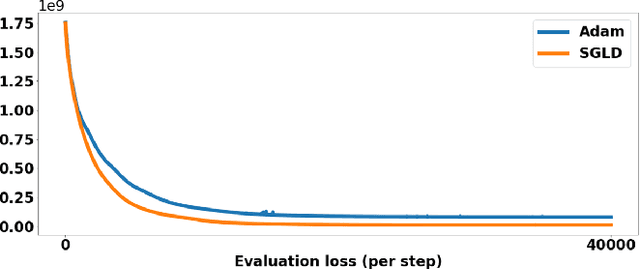
Adaptive or dynamic signal sampling in sensing systems can adapt subsequent sampling strategies based on acquired signals, thereby potentially improving image quality and speed. This paper proposes a Bayesian method for adaptive sampling based on greedy variance reduction and stochastic gradient Langevin dynamics (SGLD). The image priors involved can be either analytical or neural network-based. Notably, the learned image priors generalize well to out-of-distribution test cases that have different statistics than the training dataset. As a real-world validation, the method is applied to accelerate the acquisition of magnetic resonance imaging (MRI). Compared to non-adaptive sampling, the proposed method effectively improved the image quality by 2-3 dB in PSNR, and improved the restoration of subtle details.
Stochastic Optimization of 3D Non-Cartesian Sampling Trajectory (SNOPY)
Sep 22, 2022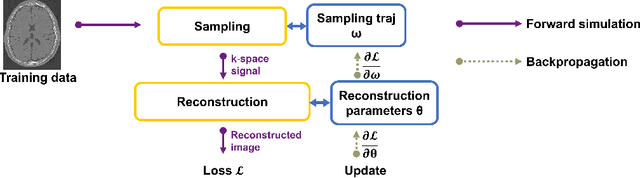
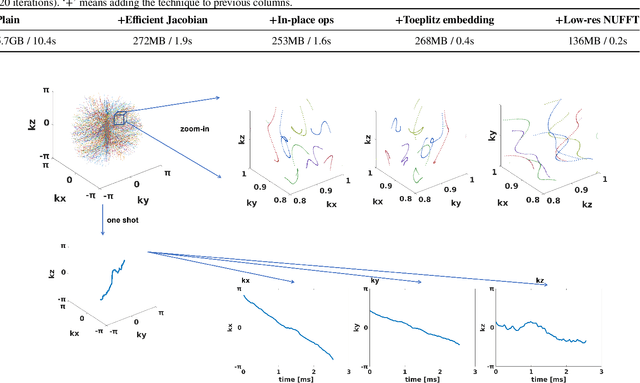

Optimizing 3D k-space sampling trajectories for efficient MRI is important yet challenging. This work proposes a generalized framework for optimizing 3D non-Cartesian sampling patterns via data-driven optimization. We built a differentiable MRI system model to enable gradient-based methods for sampling trajectory optimization. By combining training losses, the algorithm can simultaneously optimize multiple properties of sampling patterns, including image quality, hardware constraints (maximum slew rate and gradient strength), reduced peripheral nerve stimulation (PNS), and parameter-weighted contrast. The proposed method can either optimize the gradient waveform (spline-based freeform optimization) or optimize properties of given sampling trajectories (such as the rotation angle of radial trajectories). Notably, the method optimizes sampling trajectories synergistically with either model-based or learning-based reconstruction methods. We proposed several strategies to alleviate the severe non-convexity and huge computation demand posed by the high-dimensional optimization. The corresponding code is organized as an open-source, easy-to-use toolbox. We applied the optimized trajectory to multiple applications including structural and functional imaging. In the simulation studies, the reconstruction PSNR of a 3D kooshball trajectory was increased by 4 dB with SNOPY optimization. In the prospective studies, by optimizing the rotation angles of a stack-of-stars (SOS) trajectory, SNOPY improved the PSNR by 1.4dB compared to the best empirical method. Optimizing the gradient waveform of a rotational EPI trajectory improved subjects' rating of the PNS effect from 'strong' to 'mild.' In short, SNOPY provides an efficient data-driven and optimization-based method to tailor non-Cartesian sampling trajectories.
Efficient approximation of Jacobian matrices involving a non-uniform fast Fourier transform (NUFFT)
Nov 04, 2021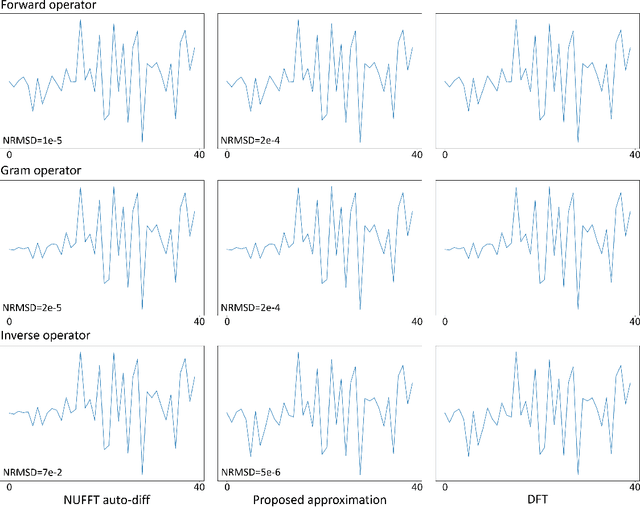
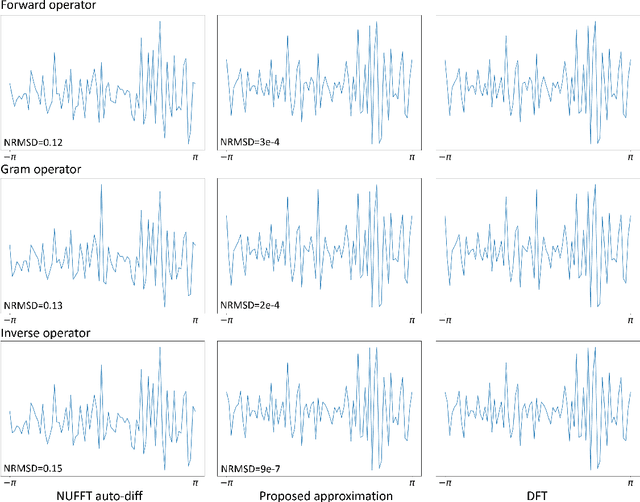
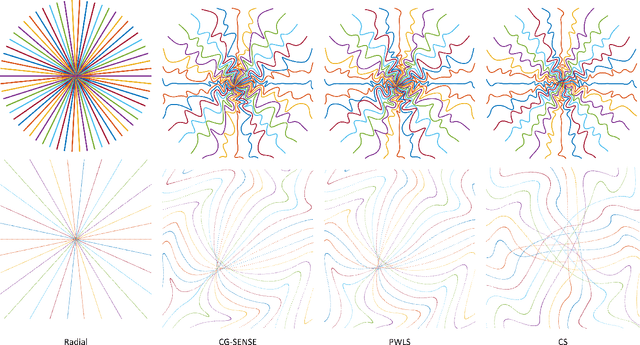

There is growing interest in learning k-space sampling patterns for MRI using optimization approaches. For non-Cartesian sampling patterns, reconstruction methods typically involve non-uniform FFT (NUFFT) operations. A typical NUFFT method contains frequency domain interpolation using Kaiser-Bessel kernel values that are retrieved by nearest neighbor look-up in a finely tabulated kernel. That look-up operation is not differentiable with respect to the sampling pattern, complicating auto-differentiation routines for backpropagation (stochastic gradient descent) for sampling pattern optimization. This paper describes an efficient and accurate approach for computing approximate gradients with respect to the sampling pattern for learning k-space sampling. Various numerical experiments validate the accuracy of the proposed approximation. We also showcase the trajectories optimized for different iterative reconstruction algorithms, including smooth convex regularized reconstruction and compressed sensing-based reconstruction.
Blind Primed Supervised Learning for MR Image Reconstruction
Apr 11, 2021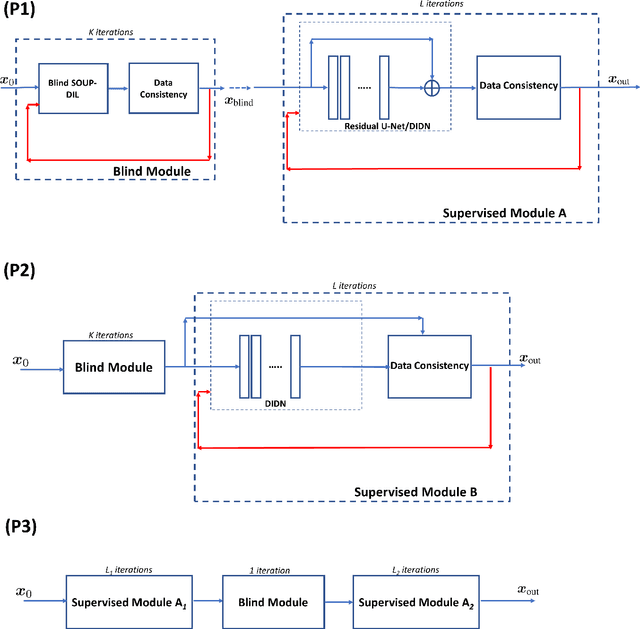
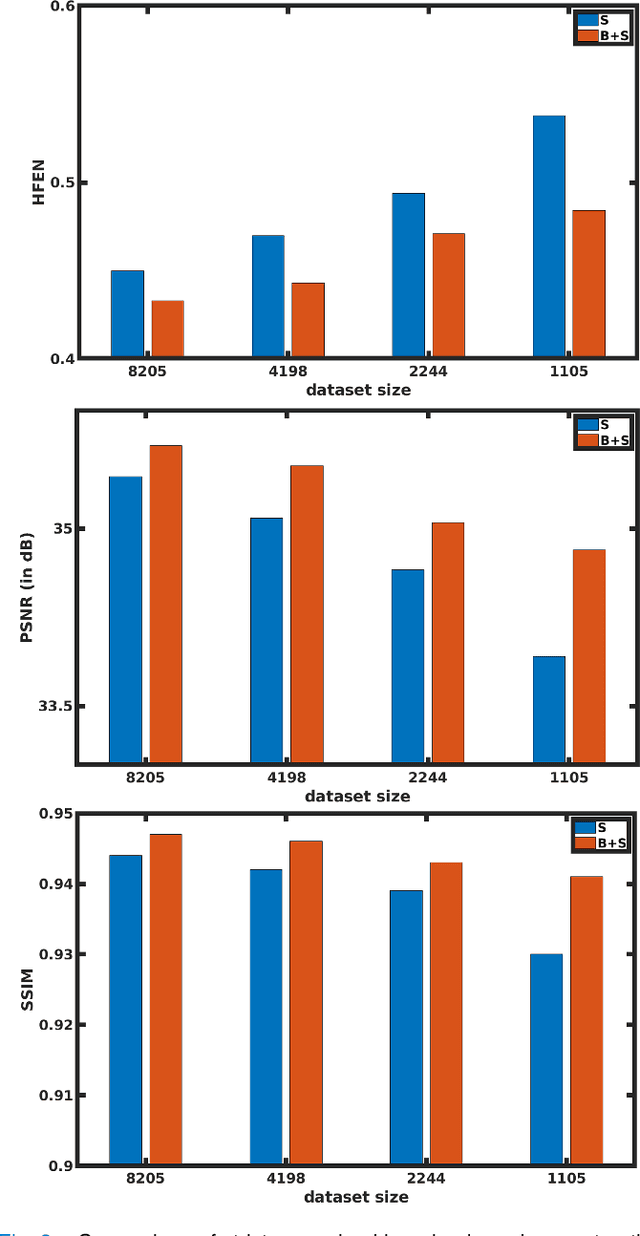
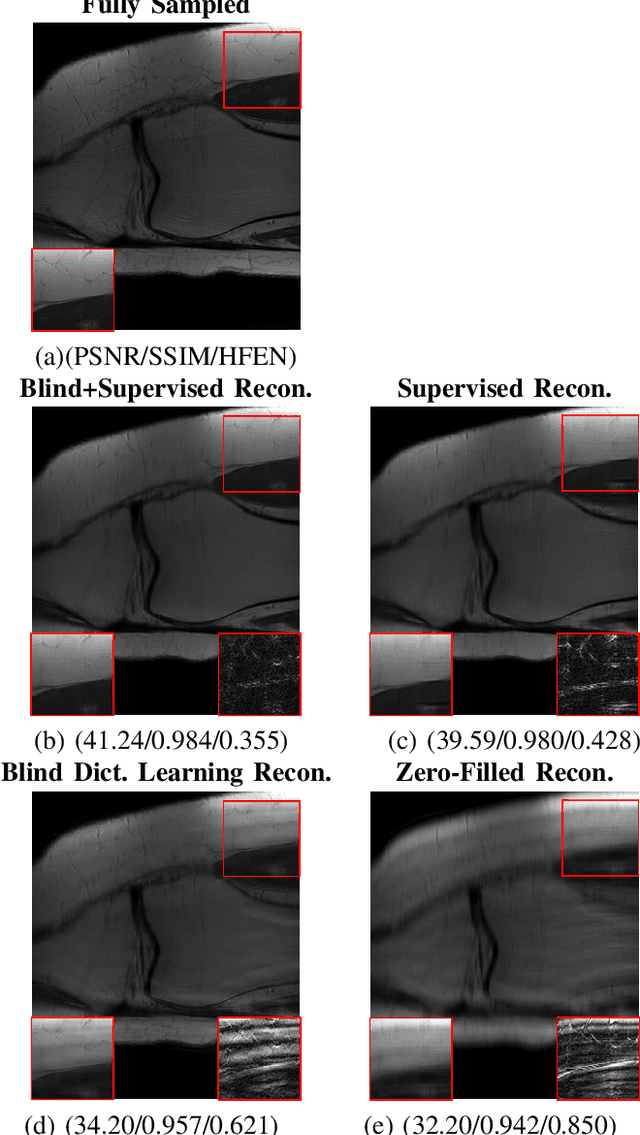
This paper examines a combined supervised-unsupervised framework involving dictionary-based blind learning and deep supervised learning for MR image reconstruction from under-sampled k-space data. A major focus of the work is to investigate the possible synergy of learned features in traditional shallow reconstruction using adaptive sparsity-based priors and deep prior-based reconstruction. Specifically, we propose a framework that uses an unrolled network to refine a blind dictionary learning-based reconstruction. We compare the proposed method with strictly supervised deep learning-based reconstruction approaches on several datasets of varying sizes and anatomies. We also compare the proposed method to alternative approaches for combining dictionary-based methods with supervised learning in MR image reconstruction. The improvements yielded by the proposed framework suggest that the blind dictionary-based approach preserves fine image details that the supervised approach can iteratively refine, suggesting that the features learned using the two methods are complementary
B-spline Parameterized Joint Optimization of Reconstruction and K-space Trajectories (BJORK) for Accelerated 2D MRI
Jan 27, 2021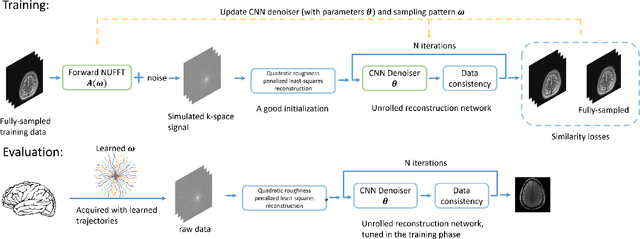
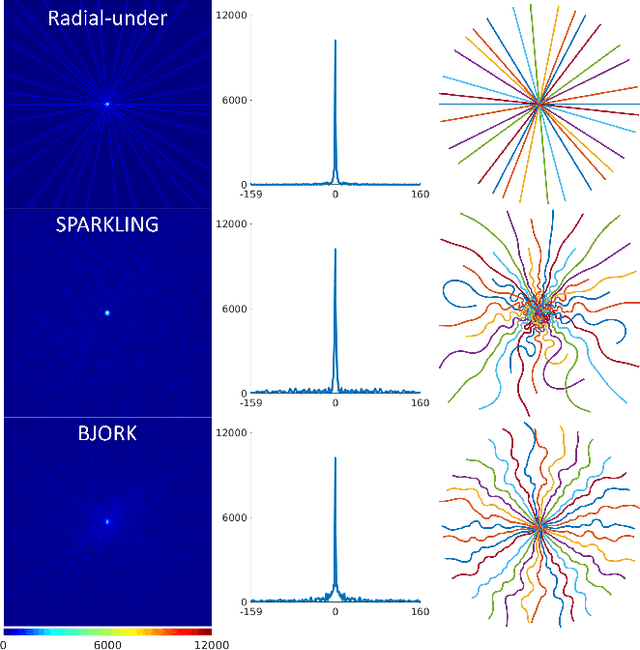


Optimizing k-space sampling trajectories is a challenging topic for fast magnetic resonance imaging (MRI). This work proposes to optimize a reconstruction algorithm and sampling trajectories jointly concerning image reconstruction quality. We parameterize trajectories with quadratic B-spline kernels to reduce the number of parameters and enable multi-scale optimization, which may help to avoid sub-optimal local minima. The algorithm includes an efficient non-Cartesian unrolled neural network-based reconstruction and an accurate approximation for backpropagation through the non-uniform fast Fourier transform (NUFFT) operator to accurately reconstruct and back-propagate multi-coil non-Cartesian data. Penalties on slew rate and gradient amplitude enforce hardware constraints. Sampling and reconstruction are trained jointly using large public datasets. To correct the potential eddy-current effect introduced by the curved trajectory, we use a pencil-beam trajectory mapping technique. In both simulations and in-vivo experiments, the learned trajectory demonstrates significantly improved image quality compared to previous model-based and learning-based trajectory optimization methods for 20x acceleration factors. Though trained with neural network-based reconstruction, the proposed trajectory also leads to improved image quality with compressed sensing-based reconstruction.
Failout: Achieving Failure-Resilient Inference in Distributed Neural Networks
Feb 18, 2020
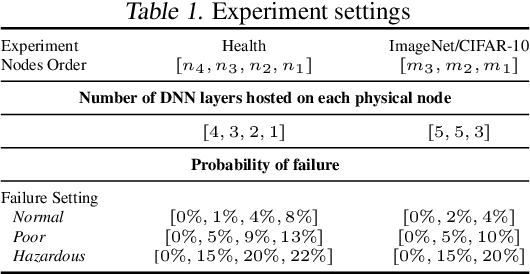

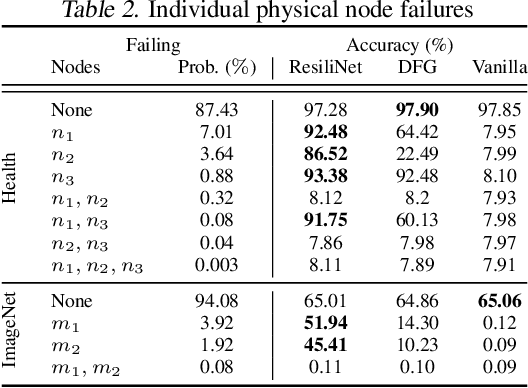
When a neural network is partitioned and distributed across physical nodes, failure of physical nodes causes the failure of the neural units that are placed on those nodes, which results in a significant performance drop. Current approaches focus on resiliency of training in distributed neural networks. However, resiliency of inference in distributed neural networks is less explored. We introduce ResiliNet, a scheme for making inference in distributed neural networks resilient to physical node failures. ResiliNet combines two concepts to provide resiliency: skip connection in residual neural networks, and a novel technique called failout, which is introduced in this paper. Failout simulates physical node failure conditions during training using dropout, and is specifically designed to improve the resiliency of distributed neural networks. The results of the experiments and ablation studies using three datasets confirm the ability of ResiliNet to provide inference resiliency for distributed neural networks.