 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Fidelity 3D Geometric Reconstruction of Pelvic Organs from MRI: A Hybrid Deep Learning and Iterative Optimization Approach
Jun 16, 2026Patient-specific 3D reconstruction of pelvic organ geometry from MRI is important for pelvic floor modeling and downstream patient-specific analysis. However, while previous studies have focused primarily on either image segmentation or downstream use of 3D models, the reconstruction of high-fidelity, high-quality geometries remains labor-intensive and poorly standardized. The study introduced a hybrid deformable shape modeling framework that integrates deep learning prediction with iterative optimization for the reconstruction of the bladder, uterus, and rectum. The framework consists of three core components: a geometry-aware multi-level deep learning architecture that preserves topological consistency of pelvic organs; a two-stage amortized optimization training strategy that balances global shape capture and local surface refinement; and a holistic synergy mechanism--where iterative optimization provides supervision for deep learning during the training phase, and during inference, deep learning rapidly predicts the global organ morphology, followed by iterative optimization to refine local surfaces and mesh quality. This framework demonstrated marked superiority in geometric fidelity than current mainstream deep learning-based organ reconstruction models. For individual anatomical structures, the reconstructed 3D geometries for the bladder, rectum, and uterus achieved significantly lower Chamfer Distance values and higher Dice Similarity Coefficient scores. In addition, while maintaining high computational efficiency, the proposed architecture yielded superior overall volumetric mesh quality. At the patient level, the framework achieved higher mean values for the 10 worst elements for both minSICN and minSIGE compared to traditional geometric post-processing algorithms.
SoRFT: Issue Resolving with Subtask-oriented Reinforced Fine-Tuning
Feb 27, 2025



Mainstream issue-resolving frameworks predominantly rely on commercial models, leading to high costs and privacy concerns. Existing training approaches for issue resolving struggle with poor generalization and fail to fully leverage open-source development resources. We propose Subtask-oriented Reinforced Fine-Tuning (SoRFT), a novel training approach to enhance the issue resolving capability of LLMs. We decomposes issue resolving into structured subtasks: file localization, function localization, line localization, and code edit generation. SoRFT consists of two training stages: (1) rejection-sampled supervised fine-tuning, Chain of Thought (CoT) data is filtered using ground-truth before fine-tuning the LLM, and (2) rule-based reinforcement learning, which leverages PPO with ground-truth based rewards. We evaluate the SoRFT-trained model on SWE-Bench Verified and SWE-Bench Lite, achieving state-of-the-art (SOTA) performance among open-source models (e.g., resolve 21.4% issues on SWE-Bench Verified with SoRFT-Qwen-7B). The experimental results demonstrate that SoRFT significantly enhances issue-resolving performance, improves model generalization, and provides a cost-efficient alternative to commercial models.
Repository Structure-Aware Training Makes SLMs Better Issue Resolver
Dec 26, 2024Language models have been applied to various software development tasks, but the performance varies according to the scale of the models. Large Language Models (LLMs) outperform Small Language Models (SLMs) in complex tasks like repository-level issue resolving, but raise concerns about privacy and cost. In contrast, SLMs are more accessible but under-perform in complex tasks. In this paper, we introduce ReSAT (Repository Structure-Aware Training), construct training data based on a large number of issues and corresponding pull requests from open-source communities to enhance the model's understanding of repository structure and issue resolving ability. We construct two types of training data: (1) localization training data, a multi-level progressive localization data to improve code understanding and localization capability; (2) code edit training data, which improves context-based code editing capability. The evaluation results on SWE-Bench-verified and RepoQA demonstrate that ReSAT effectively enhances SLMs' issue-resolving and repository-level long-context understanding capabilities.
Dehallucinating Parallel Context Extension for Retrieval-Augmented Generation
Dec 19, 2024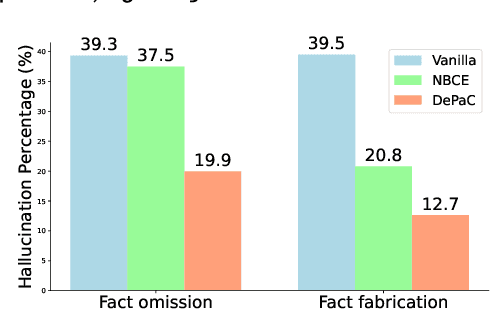
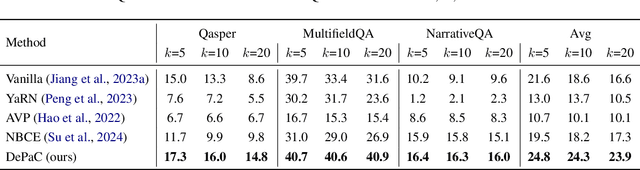

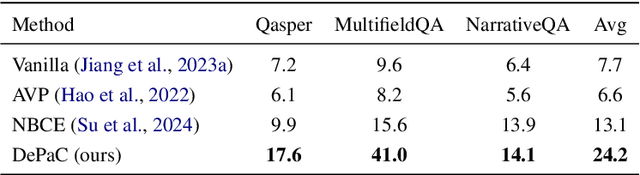
Large language models (LLMs) are susceptible to generating hallucinated information, despite the integration of retrieval-augmented generation (RAG). Parallel context extension (PCE) is a line of research attempting to effectively integrating parallel (unordered) contexts, while it still suffers from hallucinations when adapted to RAG scenarios. In this paper, we propose DePaC (Dehallucinating Parallel Context Extension), which alleviates the hallucination problem with context-aware negative training and information-calibrated aggregation. DePaC is designed to alleviate two types of in-context hallucination: fact fabrication (i.e., LLMs present claims that are not supported by the contexts) and fact omission (i.e., LLMs fail to present claims that can be supported by the contexts). Specifically, (1) for fact fabrication, we apply the context-aware negative training that fine-tunes the LLMs with negative supervisions, thus explicitly guiding the LLMs to refuse to answer when contexts are not related to questions; (2) for fact omission, we propose the information-calibrated aggregation which prioritizes context windows with higher information increment from their contexts. The experimental results on nine RAG tasks demonstrate that DePaC significantly alleviates the two types of hallucination and consistently achieves better performances on these tasks.
FastPersist: Accelerating Model Checkpointing in Deep Learning
Jun 19, 2024



Model checkpoints are critical Deep Learning (DL) artifacts that enable fault tolerance for training and downstream applications, such as inference. However, writing checkpoints to persistent storage, and other I/O aspects of DL training, are mostly ignored by compute-focused optimization efforts for faster training of rapidly growing models and datasets. Towards addressing this imbalance, we propose FastPersist to accelerate checkpoint creation in DL training. FastPersist combines three novel techniques: (i) NVMe optimizations for faster checkpoint writes to SSDs, (ii) efficient write parallelism using the available SSDs in training environments, and (iii) overlapping checkpointing with independent training computations. Our evaluation using real world dense and sparse DL models shows that FastPersist creates checkpoints in persistent storage up to 116x faster than baseline, and enables per-iteration checkpointing with negligible overhead.
MESIA: Understanding and Leveraging Supplementary Nature of Method-level Comments for Automatic Comment Generation
Mar 26, 2024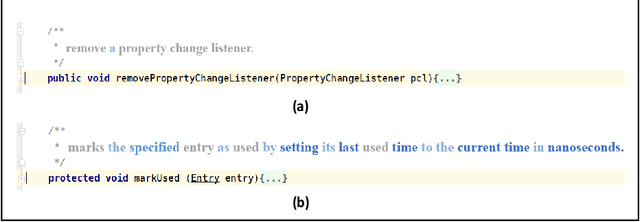
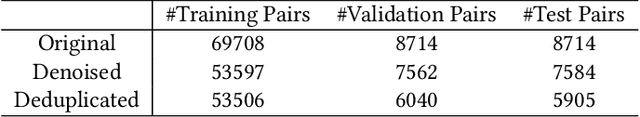

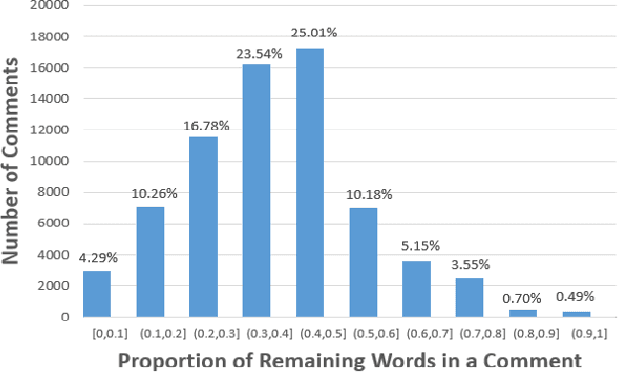
Code comments are important for developers in program comprehension. In scenarios of comprehending and reusing a method, developers expect code comments to provide supplementary information beyond the method signature. However, the extent of such supplementary information varies a lot in different code comments. In this paper, we raise the awareness of the supplementary nature of method-level comments and propose a new metric named MESIA (Mean Supplementary Information Amount) to assess the extent of supplementary information that a code comment can provide. With the MESIA metric, we conduct experiments on a popular code-comment dataset and three common types of neural approaches to generate method-level comments. Our experimental results demonstrate the value of our proposed work with a number of findings. (1) Small-MESIA comments occupy around 20% of the dataset and mostly fall into only the WHAT comment category. (2) Being able to provide various kinds of essential information, large-MESIA comments in the dataset are difficult for existing neural approaches to generate. (3) We can improve the capability of existing neural approaches to generate large-MESIA comments by reducing the proportion of small-MESIA comments in the training set. (4) The retrained model can generate large-MESIA comments that convey essential meaningful supplementary information for methods in the small-MESIA test set, but will get a lower BLEU score in evaluation. These findings indicate that with good training data, auto-generated comments can sometimes even surpass human-written reference comments, and having no appropriate ground truth for evaluation is an issue that needs to be addressed by future work on automatic comment generation.
Compositional API Recommendation for Library-Oriented Code Generation
Feb 29, 2024
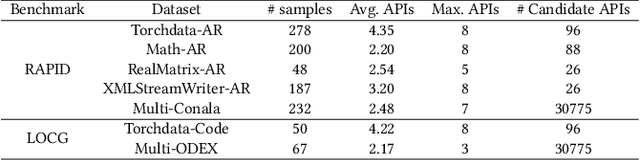
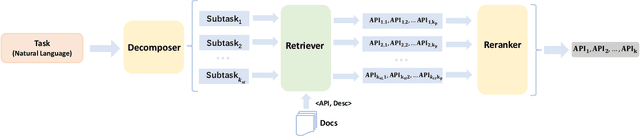
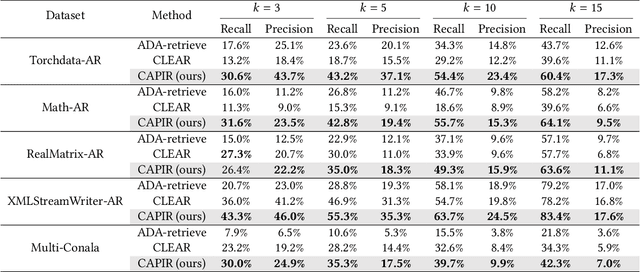
Large language models (LLMs) have achieved exceptional performance in code generation. However, the performance remains unsatisfactory in generating library-oriented code, especially for the libraries not present in the training data of LLMs. Previous work utilizes API recommendation technology to help LLMs use libraries: it retrieves APIs related to the user requirements, then leverages them as context to prompt LLMs. However, developmental requirements can be coarse-grained, requiring a combination of multiple fine-grained APIs. This granularity inconsistency makes API recommendation a challenging task. To address this, we propose CAPIR (Compositional API Recommendation), which adopts a "divide-and-conquer" strategy to recommend APIs for coarse-grained requirements. Specifically, CAPIR employs an LLM-based Decomposer to break down a coarse-grained task description into several detailed subtasks. Then, CAPIR applies an embedding-based Retriever to identify relevant APIs corresponding to each subtask. Moreover, CAPIR leverages an LLM-based Reranker to filter out redundant APIs and provides the final recommendation. To facilitate the evaluation of API recommendation methods on coarse-grained requirements, we present two challenging benchmarks, RAPID (Recommend APIs based on Documentation) and LOCG (Library-Oriented Code Generation). Experimental results on these benchmarks, demonstrate the effectiveness of CAPIR in comparison to existing baselines. Specifically, on RAPID's Torchdata-AR dataset, compared to the state-of-the-art API recommendation approach, CAPIR improves recall@5 from 18.7% to 43.2% and precision@5 from 15.5% to 37.1%. On LOCG's Torchdata-Code dataset, compared to code generation without API recommendation, CAPIR improves pass@100 from 16.0% to 28.0%.
Uncertainty and Explainable Analysis of Machine Learning Model for Reconstruction of Sonic Slowness Logs
Aug 24, 2023



Logs are valuable information for oil and gas fields as they help to determine the lithology of the formations surrounding the borehole and the location and reserves of subsurface oil and gas reservoirs. However, important logs are often missing in horizontal or old wells, which poses a challenge in field applications. In this paper, we utilize data from the 2020 machine learning competition of the SPWLA, which aims to predict the missing compressional wave slowness and shear wave slowness logs using other logs in the same borehole. We employ the NGBoost algorithm to construct an Ensemble Learning model that can predicate the results as well as their uncertainty. Furthermore, we combine the SHAP method to investigate the interpretability of the machine learning model. We compare the performance of the NGBosst model with four other commonly used Ensemble Learning methods, including Random Forest, GBDT, XGBoost, LightGBM. The results show that the NGBoost model performs well in the testing set and can provide a probability distribution for the prediction results. In addition, the variance of the probability distribution of the predicted log can be used to justify the quality of the constructed log. Using the SHAP explainable machine learning model, we calculate the importance of each input log to the predicted results as well as the coupling relationship among input logs. Our findings reveal that the NGBoost model tends to provide greater slowness prediction results when the neutron porosity and gamma ray are large, which is consistent with the cognition of petrophysical models. Furthermore, the machine learning model can capture the influence of the changing borehole caliper on slowness, where the influence of borehole caliper on slowness is complex and not easy to establish a direct relationship. These findings are in line with the physical principle of borehole acoustics.