 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoRFT: Issue Resolving with Subtask-oriented Reinforced Fine-Tuning
Feb 27, 2025



Mainstream issue-resolving frameworks predominantly rely on commercial models, leading to high costs and privacy concerns. Existing training approaches for issue resolving struggle with poor generalization and fail to fully leverage open-source development resources. We propose Subtask-oriented Reinforced Fine-Tuning (SoRFT), a novel training approach to enhance the issue resolving capability of LLMs. We decomposes issue resolving into structured subtasks: file localization, function localization, line localization, and code edit generation. SoRFT consists of two training stages: (1) rejection-sampled supervised fine-tuning, Chain of Thought (CoT) data is filtered using ground-truth before fine-tuning the LLM, and (2) rule-based reinforcement learning, which leverages PPO with ground-truth based rewards. We evaluate the SoRFT-trained model on SWE-Bench Verified and SWE-Bench Lite, achieving state-of-the-art (SOTA) performance among open-source models (e.g., resolve 21.4% issues on SWE-Bench Verified with SoRFT-Qwen-7B). The experimental results demonstrate that SoRFT significantly enhances issue-resolving performance, improves model generalization, and provides a cost-efficient alternative to commercial models.
Repository Structure-Aware Training Makes SLMs Better Issue Resolver
Dec 26, 2024Language models have been applied to various software development tasks, but the performance varies according to the scale of the models. Large Language Models (LLMs) outperform Small Language Models (SLMs) in complex tasks like repository-level issue resolving, but raise concerns about privacy and cost. In contrast, SLMs are more accessible but under-perform in complex tasks. In this paper, we introduce ReSAT (Repository Structure-Aware Training), construct training data based on a large number of issues and corresponding pull requests from open-source communities to enhance the model's understanding of repository structure and issue resolving ability. We construct two types of training data: (1) localization training data, a multi-level progressive localization data to improve code understanding and localization capability; (2) code edit training data, which improves context-based code editing capability. The evaluation results on SWE-Bench-verified and RepoQA demonstrate that ReSAT effectively enhances SLMs' issue-resolving and repository-level long-context understanding capabilities.
Dehallucinating Parallel Context Extension for Retrieval-Augmented Generation
Dec 19, 2024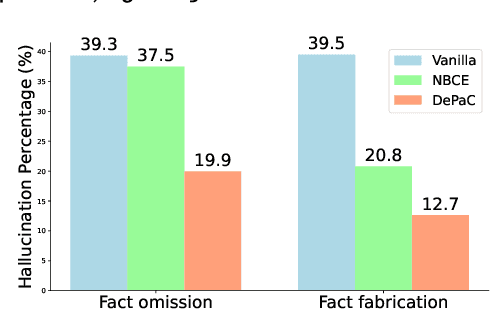
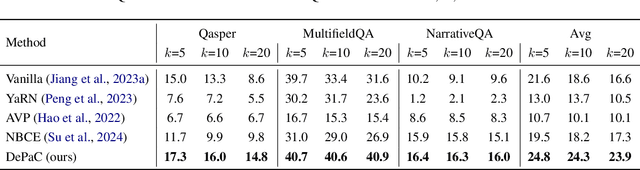

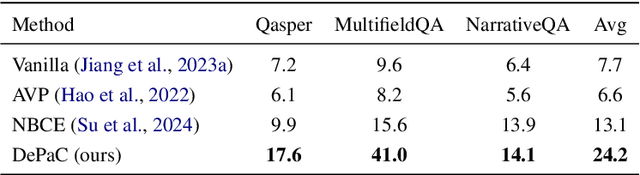
Large language models (LLMs) are susceptible to generating hallucinated information, despite the integration of retrieval-augmented generation (RAG). Parallel context extension (PCE) is a line of research attempting to effectively integrating parallel (unordered) contexts, while it still suffers from hallucinations when adapted to RAG scenarios. In this paper, we propose DePaC (Dehallucinating Parallel Context Extension), which alleviates the hallucination problem with context-aware negative training and information-calibrated aggregation. DePaC is designed to alleviate two types of in-context hallucination: fact fabrication (i.e., LLMs present claims that are not supported by the contexts) and fact omission (i.e., LLMs fail to present claims that can be supported by the contexts). Specifically, (1) for fact fabrication, we apply the context-aware negative training that fine-tunes the LLMs with negative supervisions, thus explicitly guiding the LLMs to refuse to answer when contexts are not related to questions; (2) for fact omission, we propose the information-calibrated aggregation which prioritizes context windows with higher information increment from their contexts. The experimental results on nine RAG tasks demonstrate that DePaC significantly alleviates the two types of hallucination and consistently achieves better performances on these tasks.
MESIA: Understanding and Leveraging Supplementary Nature of Method-level Comments for Automatic Comment Generation
Mar 26, 2024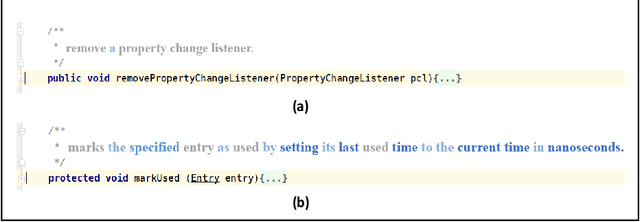
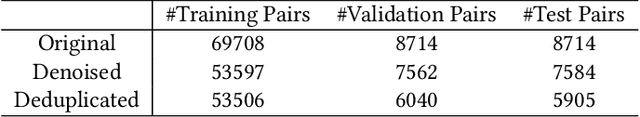

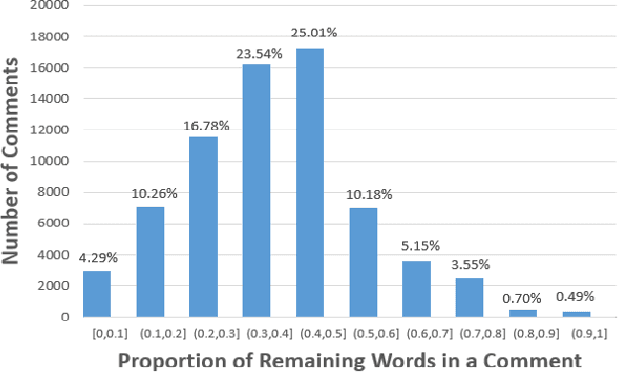
Code comments are important for developers in program comprehension. In scenarios of comprehending and reusing a method, developers expect code comments to provide supplementary information beyond the method signature. However, the extent of such supplementary information varies a lot in different code comments. In this paper, we raise the awareness of the supplementary nature of method-level comments and propose a new metric named MESIA (Mean Supplementary Information Amount) to assess the extent of supplementary information that a code comment can provide. With the MESIA metric, we conduct experiments on a popular code-comment dataset and three common types of neural approaches to generate method-level comments. Our experimental results demonstrate the value of our proposed work with a number of findings. (1) Small-MESIA comments occupy around 20% of the dataset and mostly fall into only the WHAT comment category. (2) Being able to provide various kinds of essential information, large-MESIA comments in the dataset are difficult for existing neural approaches to generate. (3) We can improve the capability of existing neural approaches to generate large-MESIA comments by reducing the proportion of small-MESIA comments in the training set. (4) The retrained model can generate large-MESIA comments that convey essential meaningful supplementary information for methods in the small-MESIA test set, but will get a lower BLEU score in evaluation. These findings indicate that with good training data, auto-generated comments can sometimes even surpass human-written reference comments, and having no appropriate ground truth for evaluation is an issue that needs to be addressed by future work on automatic comment generation.