 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMESIA: Understanding and Leveraging Supplementary Nature of Method-level Comments for Automatic Comment Generation
Mar 26, 2024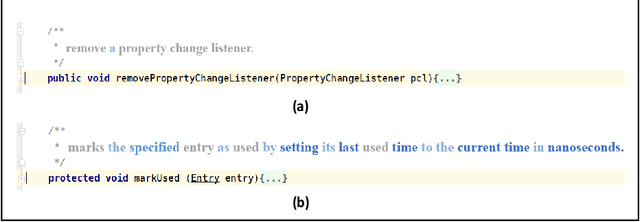
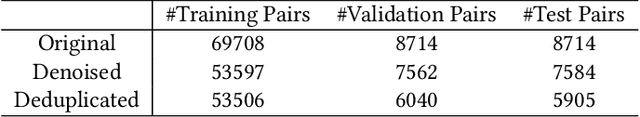

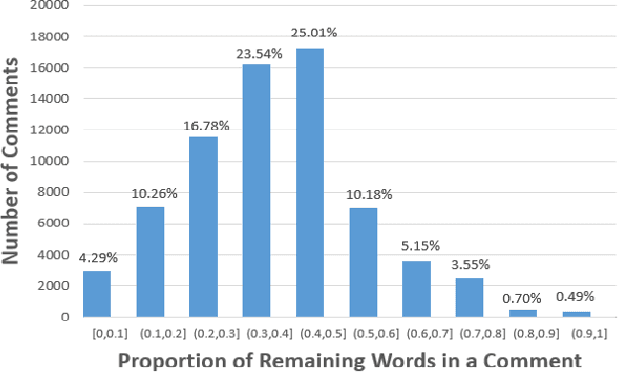
Code comments are important for developers in program comprehension. In scenarios of comprehending and reusing a method, developers expect code comments to provide supplementary information beyond the method signature. However, the extent of such supplementary information varies a lot in different code comments. In this paper, we raise the awareness of the supplementary nature of method-level comments and propose a new metric named MESIA (Mean Supplementary Information Amount) to assess the extent of supplementary information that a code comment can provide. With the MESIA metric, we conduct experiments on a popular code-comment dataset and three common types of neural approaches to generate method-level comments. Our experimental results demonstrate the value of our proposed work with a number of findings. (1) Small-MESIA comments occupy around 20% of the dataset and mostly fall into only the WHAT comment category. (2) Being able to provide various kinds of essential information, large-MESIA comments in the dataset are difficult for existing neural approaches to generate. (3) We can improve the capability of existing neural approaches to generate large-MESIA comments by reducing the proportion of small-MESIA comments in the training set. (4) The retrained model can generate large-MESIA comments that convey essential meaningful supplementary information for methods in the small-MESIA test set, but will get a lower BLEU score in evaluation. These findings indicate that with good training data, auto-generated comments can sometimes even surpass human-written reference comments, and having no appropriate ground truth for evaluation is an issue that needs to be addressed by future work on automatic comment generation.
Code Execution with Pre-trained Language Models
May 08, 2023



Code execution is a fundamental aspect of programming language semantics that reflects the exact behavior of the code. However, most pre-trained models for code intelligence ignore the execution trace and only rely on source code and syntactic structures. In this paper, we investigate how well pre-trained models can understand and perform code execution. We develop a mutation-based data augmentation technique to create a large-scale and realistic Python dataset and task for code execution, which challenges existing models such as Codex. We then present CodeExecutor, a Transformer model that leverages code execution pre-training and curriculum learning to enhance its semantic comprehension. We evaluate CodeExecutor on code execution and show its promising performance and limitations. We also demonstrate its potential benefits for code intelligence tasks such as zero-shot code-to-code search and text-to-code generation. Our analysis provides insights into the learning and generalization abilities of pre-trained models for code execution.
Evaluator for Emotionally Consistent Chatbots
Dec 02, 2021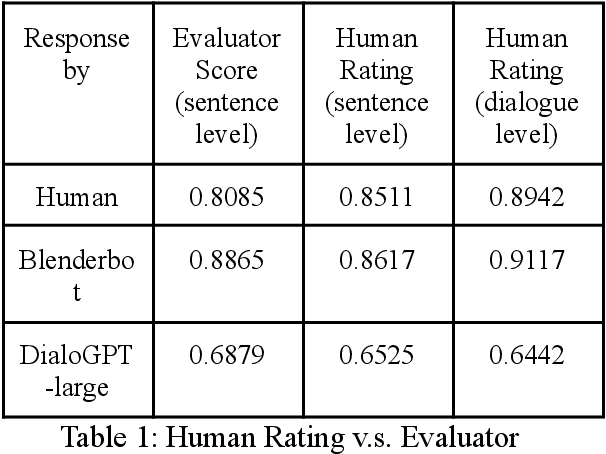
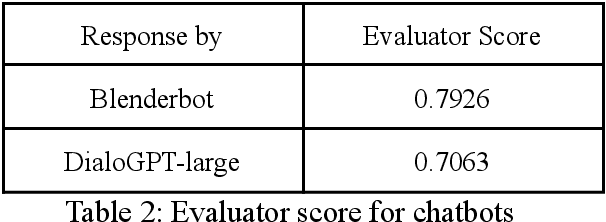

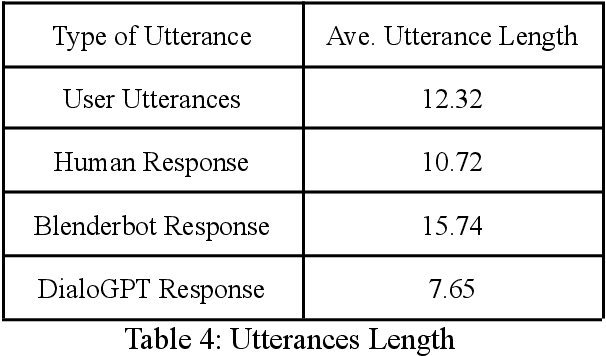
One challenge for evaluating current sequence- or dialogue-level chatbots, such as Empathetic Open-domain Conversation Models, is to determine whether the chatbot performs in an emotionally consistent way. The most recent work only evaluates on the aspects of context coherence, language fluency, response diversity, or logical self-consistency between dialogues. This work proposes training an evaluator to determine the emotional consistency of chatbots.
CodeQA: A Question Answering Dataset for Source Code Comprehension
Sep 17, 2021
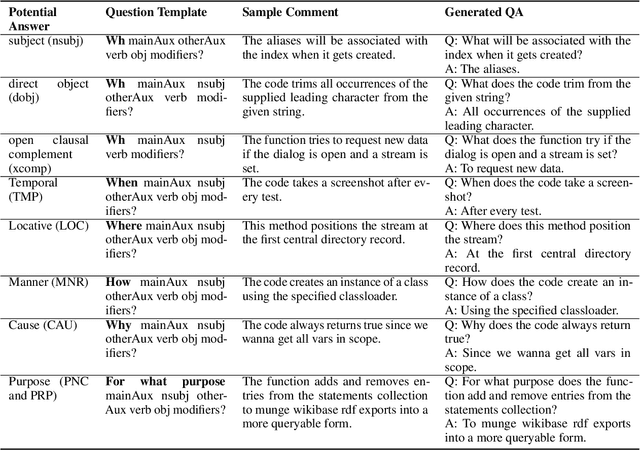


We propose CodeQA, a free-form question answering dataset for the purpose of source code comprehension: given a code snippet and a question, a textual answer is required to be generated. CodeQA contains a Java dataset with 119,778 question-answer pairs and a Python dataset with 70,085 question-answer pairs. To obtain natural and faithful questions and answers, we implement syntactic rules and semantic analysis to transform code comments into question-answer pairs. We present the construction process and conduct systematic analysis of our dataset. Experiment results achieved by several neural baselines on our dataset are shown and discussed. While research on question-answering and machine reading comprehension develops rapidly, few prior work has drawn attention to code question answering. This new dataset can serve as a useful research benchmark for source code comprehension.