 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemRep: Generative Code Representation Learning with Code Transformations
Mar 13, 2026Code transformation is a foundational capability in the software development process, where its effectiveness relies on constructing a high-quality code representation to characterize the input code semantics and guide the transformation. Existing approaches treat code transformation as an end-to-end learning task, leaving the construction of the representation needed for semantic reasoning implicit in model weights or relying on rigid compiler-level abstractions. We present SemRep, a framework that improves code transformation through generative code representation learning. Our key insight is to employ the semantics-preserving transformations as the intermediate representation, which serves as both a generative mid-training task and the guidance for subsequent instruction-specific code transformations. Across general code editing and optimization tasks (e.g., GPU kernel optimization), SemRep outperforms the extensively finetuned baselines with strictly the same training budget by 6.9% in correctness, 1.1x in performance, 13.9% in generalization, and 6.7% in robustness. With the improved exploration of diverse code transformations, SemRep is particularly amenable to evolutionary search. Combined with an evolutionary coding agent, SemRep finds optimizations that 685B larger-weight baselines fail to discover while achieving the same performance with 25% less inference compute.
DevBench: A Realistic, Developer-Informed Benchmark for Code Generation Models
Jan 17, 2026DevBench is a telemetry-driven benchmark designed to evaluate Large Language Models (LLMs) on realistic code completion tasks. It includes 1,800 evaluation instances across six programming languages and six task categories derived from real developer telemetry, such as API usage and code purpose understanding. Unlike prior benchmarks, it emphasizes ecological validity, avoids training data contamination, and enables detailed diagnostics. The evaluation combines functional correctness, similarity-based metrics, and LLM-judge assessments focused on usefulness and contextual relevance. 9 state-of-the-art models were assessed, revealing differences in syntactic precision, semantic reasoning, and practical utility. Our benchmark provides actionable insights to guide model selection and improvement-detail that is often missing from other benchmarks but is essential for both practical deployment and targeted model development.
Sphinx: Benchmarking and Modeling for LLM-Driven Pull Request Review
Jan 06, 2026Pull request (PR) review is essential for ensuring software quality, yet automating this task remains challenging due to noisy supervision, limited contextual understanding, and inadequate evaluation metrics. We present Sphinx, a unified framework for LLM-based PR review that addresses these limitations through three key components: (1) a structured data generation pipeline that produces context-rich, semantically grounded review comments by comparing pseudo-modified and merged code; (2) a checklist-based evaluation benchmark that assesses review quality based on structured coverage of actionable verification points, moving beyond surface-level metrics like BLEU; and (3) Checklist Reward Policy Optimization (CRPO), a novel training paradigm that uses rule-based, interpretable rewards to align model behavior with real-world review practices. Extensive experiments show that models trained with Sphinx achieve state-of-the-art performance on review completeness and precision, outperforming both proprietary and open-source baselines by up to 40\% in checklist coverage. Together, Sphinx enables the development of PR review models that are not only fluent but also context-aware, technically precise, and practically deployable in real-world development workflows. The data will be released after review.
SWE-bench Goes Live!
May 29, 2025The issue-resolving task, where a model generates patches to fix real-world bugs, has emerged as a critical benchmark for evaluating the capabilities of large language models (LLMs). While SWE-bench and its variants have become standard in this domain, they suffer from key limitations: they have not been updated since their initial releases, cover a narrow set of repositories, and depend heavily on manual effort for instance construction and environment setup. These factors hinder scalability and introduce risks of overfitting and data contamination. In this work, we present \textbf{SWE-bench-Live}, a \textit{live-updatable} benchmark designed to overcome these challenges. Our initial release consists of 1,319 tasks derived from real GitHub issues created since 2024, spanning 93 repositories. Each task is accompanied by a dedicated Docker image to ensure reproducible execution. Central to our benchmark is \method, an automated curation pipeline that streamlines the entire process from instance creation to environment setup, removing manual bottlenecks and enabling scalability and continuous updates. We evaluate a range of state-of-the-art agent frameworks and LLMs on SWE-bench-Live, revealing a substantial performance gap compared to static benchmarks like SWE-bench, even under controlled evaluation conditions. To better understand this discrepancy, we perform detailed analyses across repository origin, issue recency, and task difficulty. By providing a fresh, diverse, and executable benchmark grounded in live repository activity, SWE-bench-Live facilitates rigorous, contamination-resistant evaluation of LLMs and agents in dynamic, real-world software development settings.
Code Execution with Pre-trained Language Models
May 08, 2023



Code execution is a fundamental aspect of programming language semantics that reflects the exact behavior of the code. However, most pre-trained models for code intelligence ignore the execution trace and only rely on source code and syntactic structures. In this paper, we investigate how well pre-trained models can understand and perform code execution. We develop a mutation-based data augmentation technique to create a large-scale and realistic Python dataset and task for code execution, which challenges existing models such as Codex. We then present CodeExecutor, a Transformer model that leverages code execution pre-training and curriculum learning to enhance its semantic comprehension. We evaluate CodeExecutor on code execution and show its promising performance and limitations. We also demonstrate its potential benefits for code intelligence tasks such as zero-shot code-to-code search and text-to-code generation. Our analysis provides insights into the learning and generalization abilities of pre-trained models for code execution.
CodeReviewer: Pre-Training for Automating Code Review Activities
Mar 17, 2022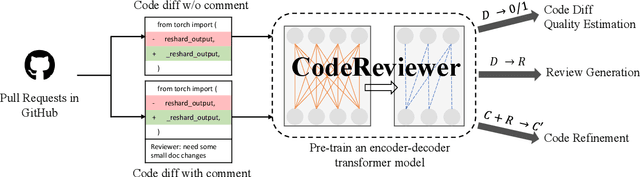

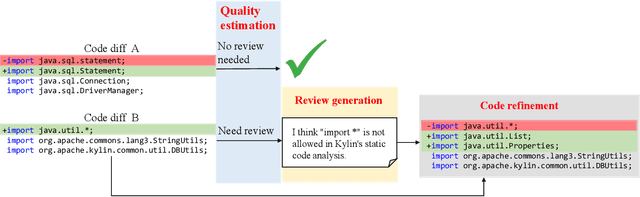
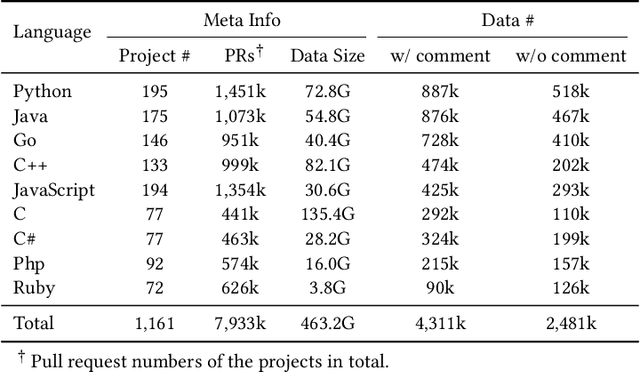
Code review is an essential part to software development lifecycle since it aims at guaranteeing the quality of codes. Modern code review activities necessitate developers viewing, understanding and even running the programs to assess logic, functionality, latency, style and other factors. It turns out that developers have to spend far too much time reviewing the code of their peers. Accordingly, it is in significant demand to automate the code review process. In this research, we focus on utilizing pre-training techniques for the tasks in the code review scenario. We collect a large-scale dataset of real world code changes and code reviews from open-source projects in nine of the most popular programming languages. To better understand code diffs and reviews, we propose CodeReviewer, a pre-trained model that utilizes four pre-training tasks tailored specifically for the code review senario. To evaluate our model, we focus on three key tasks related to code review activities, including code change quality estimation, review comment generation and code refinement. Furthermore, we establish a high-quality benchmark dataset based on our collected data for these three tasks and conduct comprehensive experiments on it. The experimental results demonstrate that our model outperforms the previous state-of-the-art pre-training approaches in all tasks. Further analysis show that our proposed pre-training tasks and the multilingual pre-training dataset benefit the model on the understanding of code changes and reviews.
CodeXGLUE: A Machine Learning Benchmark Dataset for Code Understanding and Generation
Feb 09, 2021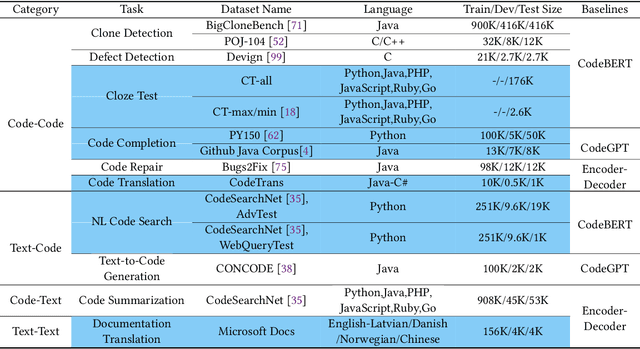

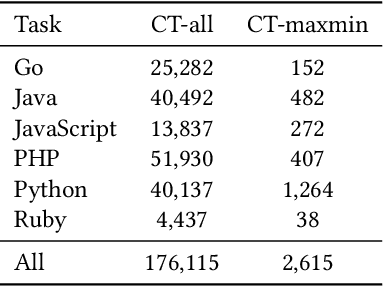

Benchmark datasets have a significant impact on accelerating research in programming language tasks. In this paper, we introduce CodeXGLUE, a benchmark dataset to foster machine learning research for program understanding and generation. CodeXGLUE includes a collection of 10 tasks across 14 datasets and a platform for model evaluation and comparison. CodeXGLUE also features three baseline systems, including the BERT-style, GPT-style, and Encoder-Decoder models, to make it easy for researchers to use the platform. The availability of such data and baselines can help the development and validation of new methods that can be applied to various program understanding and generation problems.
GraphCodeBERT: Pre-training Code Representations with Data Flow
Sep 29, 2020
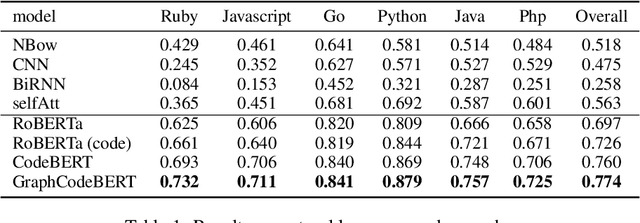
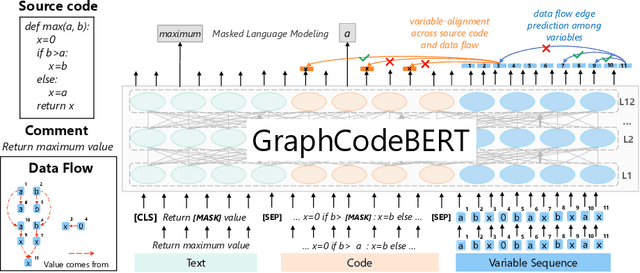
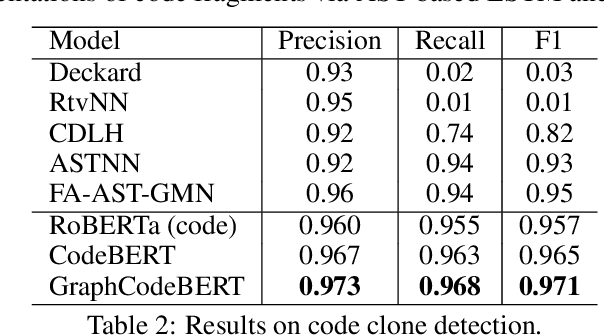
Pre-trained models for programming language have achieved dramatic empirical improvements on a variety of code-related tasks such as code search, code completion, code summarization, etc. However, existing pre-trained models regard a code snippet as a sequence of tokens, while ignoring the inherent structure of code, which provides crucial code semantics and would enhance the code understanding process. We present GraphCodeBERT, a pre-trained model for programming language that considers the inherent structure of code. Instead of taking syntactic-level structure of code like abstract syntax tree (AST), we use data flow in the pre-training stage, which is a semantic-level structure of code that encodes the relation of "where-the-value-comes-from" between variables. Such a semantic-level structure is neat and does not bring an unnecessarily deep hierarchy of AST, the property of which makes the model more efficient. We develop GraphCodeBERT based on Transformer. In addition to using the task of masked language modeling, we introduce two structure-aware pre-training tasks. One is to predict code structure edges, and the other is to align representations between source code and code structure. We implement the model in an efficient way with a graph-guided masked attention function to incorporate the code structure. We evaluate our model on four tasks, including code search, clone detection, code translation, and code refinement. Results show that code structure and newly introduced pre-training tasks can improve GraphCodeBERT and achieves state-of-the-art performance on the four downstream tasks. We further show that the model prefers structure-level attentions over token-level attentions in the task of code search.
IntelliCode Compose: Code Generation Using Transformer
May 16, 2020



In software development through integrated development environments (IDEs), code completion is one of the most widely used features. Nevertheless, majority of integrated development environments only support completion of methods and APIs, or arguments. In this paper, we introduce IntelliCode Compose $-$ a general-purpose multilingual code completion tool which is capable of predicting sequences of code tokens of arbitrary types, generating up to entire lines of syntactically correct code. It leverages state-of-the-art generative transformer model trained on 1.2 billion lines of source code in Python, $C\#$, JavaScript and TypeScript programming languages. IntelliCode Compose is deployed as a cloud-based web service. It makes use of client-side tree-based caching, efficient parallel implementation of the beam search decoder, and compute graph optimizations to meet edit-time completion suggestion requirements in the Visual Studio Code IDE and Azure Notebook. Our best model yields an average edit similarity of $86.7\%$ and a perplexity of 1.82 for Python programming language.
Pythia: AI-assisted Code Completion System
Nov 29, 2019


In this paper, we propose a novel end-to-end approach for AI-assisted code completion called Pythia. It generates ranked lists of method and API recommendations which can be used by software developers at edit time. The system is currently deployed as part of Intellicode extension in Visual Studio Code IDE. Pythia exploits state-of-the-art large-scale deep learning models trained on code contexts extracted from abstract syntax trees. It is designed to work at a high throughput predicting the best matching code completions on the order of 100 $ms$. We describe the architecture of the system, perform comparisons to frequency-based approach and invocation-based Markov Chain language model, and discuss challenges serving Pythia models on lightweight client devices. The offline evaluation results obtained on 2700 Python open source software GitHub repositories show a top-5 accuracy of 92\%, surpassing the baseline models by 20\% averaged over classes, for both intra and cross-project settings.