 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepSpeed4Science Initiative: Enabling Large-Scale Scientific Discovery through Sophisticated AI System Technologies
Oct 11, 2023



In the upcoming decade, deep learning may revolutionize the natural sciences, enhancing our capacity to model and predict natural occurrences. This could herald a new era of scientific exploration, bringing significant advancements across sectors from drug development to renewable energy. To answer this call, we present DeepSpeed4Science initiative (deepspeed4science.ai) which aims to build unique capabilities through AI system technology innovations to help domain experts to unlock today's biggest science mysteries. By leveraging DeepSpeed's current technology pillars (training, inference and compression) as base technology enablers, DeepSpeed4Science will create a new set of AI system technologies tailored for accelerating scientific discoveries by addressing their unique complexity beyond the common technical approaches used for accelerating generic large language models (LLMs). In this paper, we showcase the early progress we made with DeepSpeed4Science in addressing two of the critical system challenges in structural biology research.
Reinforcement Learning from Automatic Feedback for High-Quality Unit Test Generation
Oct 03, 2023
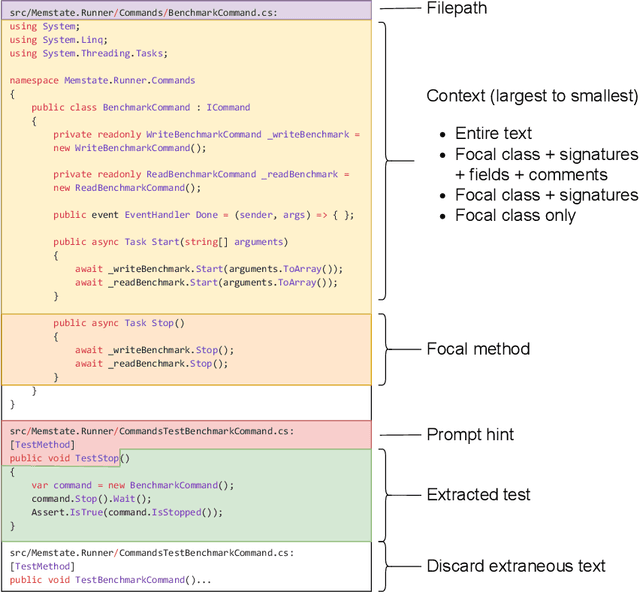

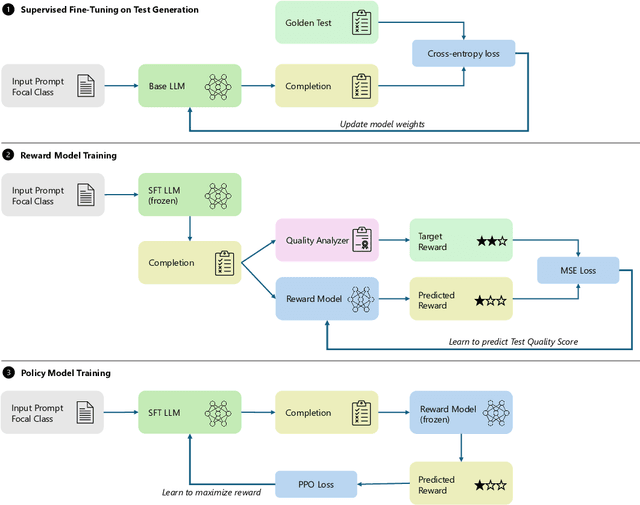
Software testing is a crucial aspect of software development, and the creation of high-quality tests that adhere to best practices is essential for effective maintenance. Recently, Large Language Models (LLMs) have gained popularity for code generation, including the automated creation of test cases. However, these LLMs are often trained on vast amounts of publicly available code, which may include test cases that do not adhere to best practices and may even contain test smells (anti-patterns). To address this issue, we propose a novel technique called Reinforcement Learning from Static Quality Metrics (RLSQM). To begin, we analyze the anti-patterns generated by the LLM and show that LLMs can generate undesirable test smells. Thus, we train specific reward models for each static quality metric, then utilize Proximal Policy Optimization (PPO) to train models for optimizing a single quality metric at a time. Furthermore, we amalgamate these rewards into a unified reward model aimed at capturing different best practices and quality aspects of tests. By comparing RL-trained models with those trained using supervised learning, we provide insights into how reliably utilize RL to improve test generation quality and into the effects of various training strategies. Our experimental results demonstrate that the RL-optimized model consistently generated high-quality test cases compared to the base LLM, improving the model by up to 21%, and successfully generates nearly 100% syntactically correct code. RLSQM also outperformed GPT-4 on four out of seven metrics. This represents a significant step towards enhancing the overall efficiency and reliability of software testing through Reinforcement Learning and static quality metrics. Our data are available at this link: https://figshare.com/s/ded476c8d4c221222849.
Code Execution with Pre-trained Language Models
May 08, 2023



Code execution is a fundamental aspect of programming language semantics that reflects the exact behavior of the code. However, most pre-trained models for code intelligence ignore the execution trace and only rely on source code and syntactic structures. In this paper, we investigate how well pre-trained models can understand and perform code execution. We develop a mutation-based data augmentation technique to create a large-scale and realistic Python dataset and task for code execution, which challenges existing models such as Codex. We then present CodeExecutor, a Transformer model that leverages code execution pre-training and curriculum learning to enhance its semantic comprehension. We evaluate CodeExecutor on code execution and show its promising performance and limitations. We also demonstrate its potential benefits for code intelligence tasks such as zero-shot code-to-code search and text-to-code generation. Our analysis provides insights into the learning and generalization abilities of pre-trained models for code execution.
Exploring and Evaluating Personalized Models for Code Generation
Aug 29, 2022
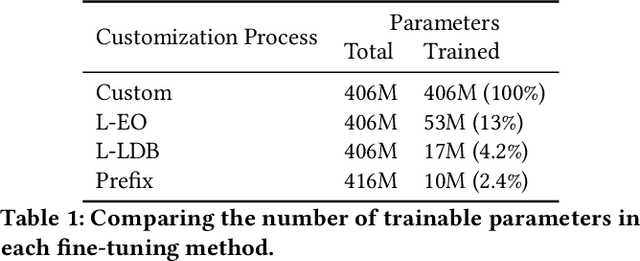
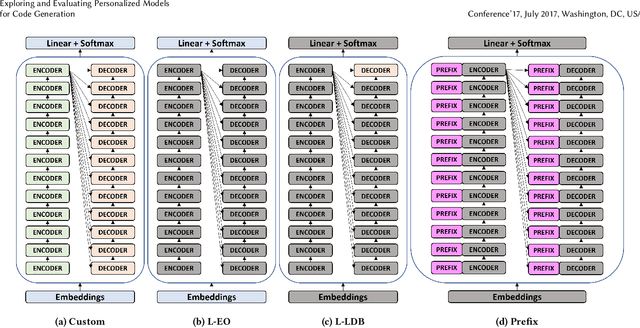
Large Transformer models achieved the state-of-the-art status for Natural Language Understanding tasks and are increasingly becoming the baseline model architecture for modeling source code. Transformers are usually pre-trained on large unsupervised corpora, learning token representations and transformations relevant to modeling generally available text, and are then fine-tuned on a particular downstream task of interest. While fine-tuning is a tried-and-true method for adapting a model to a new domain -- for example, question-answering on a given topic -- generalization remains an on-going challenge. In this paper, we explore and evaluate transformer model fine-tuning for personalization. In the context of generating unit tests for Java methods, we evaluate learning to personalize to a specific software project using several personalization techniques. We consider three key approaches: (i) custom fine-tuning, which allows all the model parameters to be tuned; (ii) lightweight fine-tuning, which freezes most of the model's parameters, allowing tuning of the token embeddings and softmax layer only or the final layer alone; (iii) prefix tuning, which keeps model parameters frozen, but optimizes a small project-specific prefix vector. Each of these techniques offers a trade-off in total compute cost and predictive performance, which we evaluate by code and task-specific metrics, training time, and total computational operations. We compare these fine-tuning strategies for code generation and discuss the potential generalization and cost benefits of each in various deployment scenarios.
AdaptivePaste: Code Adaptation through Learning Semantics-aware Variable Usage Representations
May 23, 2022


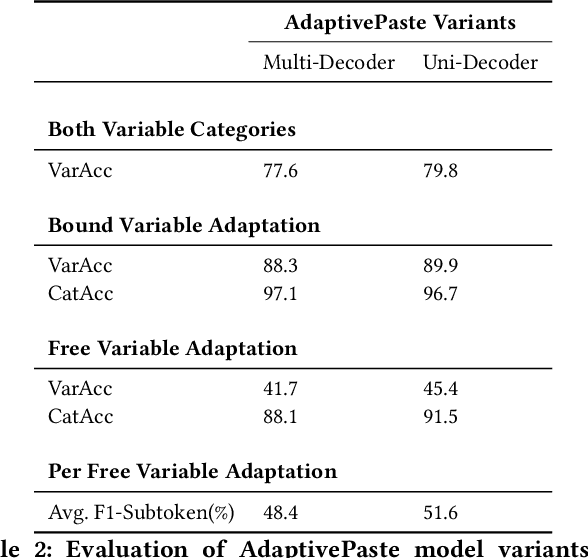
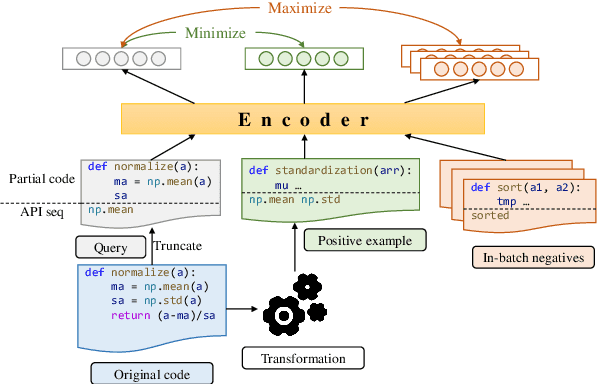
In software development, it is common for programmers to copy-paste code snippets and then adapt them to their use case. This scenario motivates \textit{code adaptation} task -- a variant of program repair which aims to adapt all variable identifiers in a pasted snippet of code to the surrounding, preexisting source code. Nevertheless, no existing approach have been shown to effectively address this task. In this paper, we introduce AdaptivePaste, a learning-based approach to source code adaptation, based on the transformer model and a dedicated dataflow-aware deobfuscation pre-training task to learn meaningful representations of variable usage patterns. We evaluate AdaptivePaste on a dataset of code snippets in Python. Evaluation results suggest that our model can learn to adapt copy-pasted code with 79.8\% accuracy.
CodeReviewer: Pre-Training for Automating Code Review Activities
Mar 17, 2022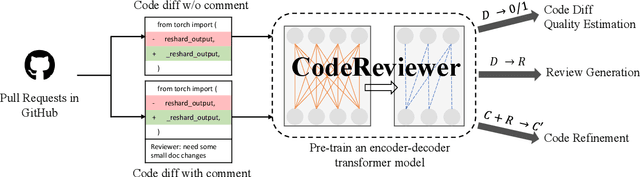

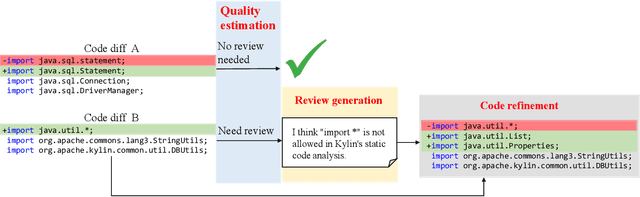
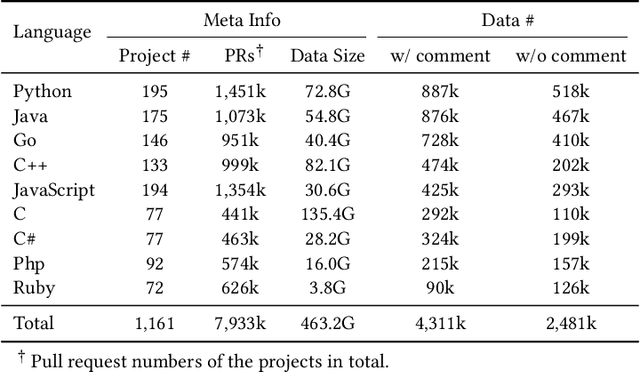
Code review is an essential part to software development lifecycle since it aims at guaranteeing the quality of codes. Modern code review activities necessitate developers viewing, understanding and even running the programs to assess logic, functionality, latency, style and other factors. It turns out that developers have to spend far too much time reviewing the code of their peers. Accordingly, it is in significant demand to automate the code review process. In this research, we focus on utilizing pre-training techniques for the tasks in the code review scenario. We collect a large-scale dataset of real world code changes and code reviews from open-source projects in nine of the most popular programming languages. To better understand code diffs and reviews, we propose CodeReviewer, a pre-trained model that utilizes four pre-training tasks tailored specifically for the code review senario. To evaluate our model, we focus on three key tasks related to code review activities, including code change quality estimation, review comment generation and code refinement. Furthermore, we establish a high-quality benchmark dataset based on our collected data for these three tasks and conduct comprehensive experiments on it. The experimental results demonstrate that our model outperforms the previous state-of-the-art pre-training approaches in all tasks. Further analysis show that our proposed pre-training tasks and the multilingual pre-training dataset benefit the model on the understanding of code changes and reviews.
ReACC: A Retrieval-Augmented Code Completion Framework
Mar 15, 2022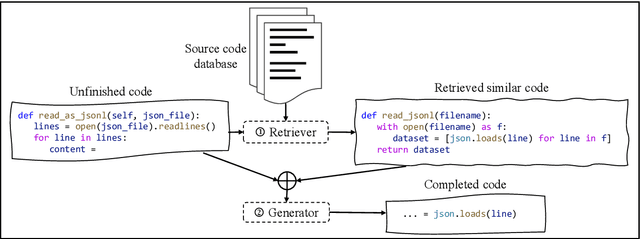

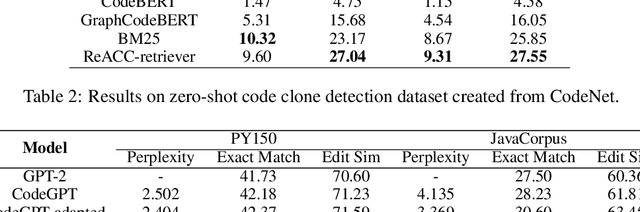
Code completion, which aims to predict the following code token(s) according to the code context, can improve the productivity of software development. Recent work has proved that statistical language modeling with transformers can greatly improve the performance in the code completion task via learning from large-scale source code datasets. However, current approaches focus only on code context within the file or project, i.e. internal context. Our distinction is utilizing "external" context, inspired by human behaviors of copying from the related code snippets when writing code. Specifically, we propose a retrieval-augmented code completion framework, leveraging both lexical copying and referring to code with similar semantics by retrieval. We adopt a stage-wise training approach that combines a source code retriever and an auto-regressive language model for programming language. We evaluate our approach in the code completion task in Python and Java programming languages, achieving a state-of-the-art performance on CodeXGLUE benchmark.
Long-Range Modeling of Source Code Files with eWASH: Extended Window Access by Syntax Hierarchy
Sep 17, 2021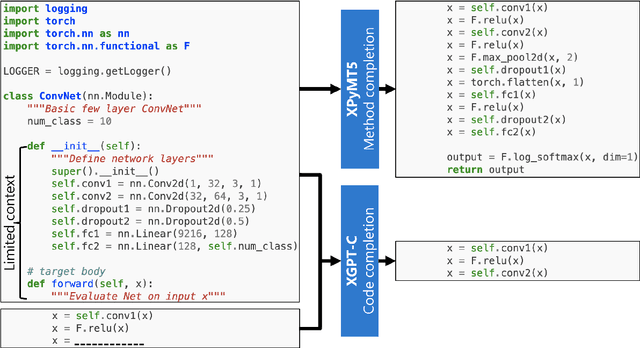
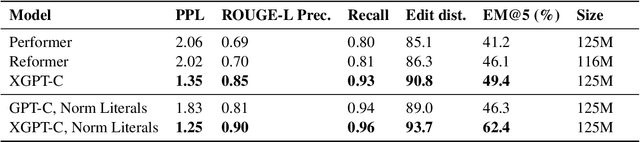

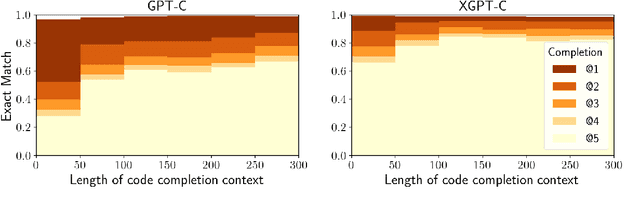
Statistical language modeling and translation with transformers have found many successful applications in program understanding and generation tasks, setting high benchmarks for tools in modern software development environments. The finite context window of these neural models means, however, that they will be unable to leverage the entire relevant context of large files and packages for any given task. While there are many efforts to extend the context window, we introduce an architecture-independent approach for leveraging the syntactic hierarchies of source code for incorporating entire file-level context into a fixed-length window. Using concrete syntax trees of each source file we extract syntactic hierarchies and integrate them into context window by selectively removing from view more specific, less relevant scopes for a given task. We evaluate this approach on code generation tasks and joint translation of natural language and source code in Python programming language, achieving a new state-of-the-art in code completion and summarization for Python in the CodeXGLUE benchmark. We also introduce new CodeXGLUE benchmarks for user-experience-motivated tasks: code completion with normalized literals, method body completion/code summarization conditioned on file-level context.
MergeBERT: Program Merge Conflict Resolution via Neural Transformers
Sep 08, 2021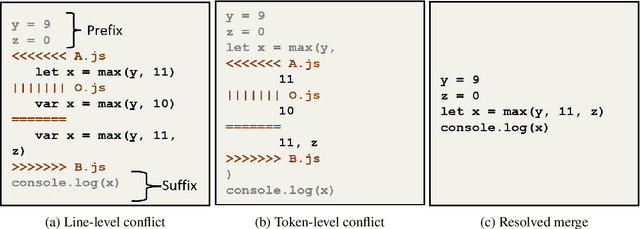
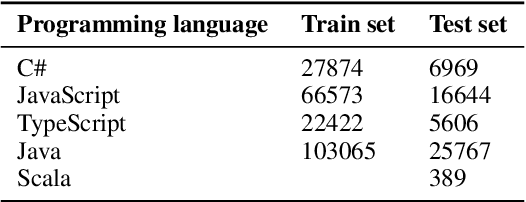

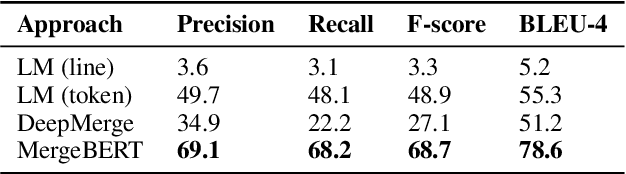
Collaborative software development is an integral part of the modern software development life cycle, essential to the success of large-scale software projects. When multiple developers make concurrent changes around the same lines of code, a merge conflict may occur. Such conflicts stall pull requests and continuous integration pipelines for hours to several days, seriously hurting developer productivity. In this paper, we introduce MergeBERT, a novel neural program merge framework based on the token-level three-way differencing and a transformer encoder model. Exploiting restricted nature of merge conflict resolutions, we reformulate the task of generating the resolution sequence as a classification task over a set of primitive merge patterns extracted from real-world merge commit data. Our model achieves 64--69% precision of merge resolution synthesis, yielding nearly a 2x performance improvement over existing structured and neural program merge tools. Finally, we demonstrate versatility of our model, which is able to perform program merge in a multilingual setting with Java, JavaScript, TypeScript, and C# programming languages, generalizing zero-shot to unseen languages.
Learning to Generate Code Sketches
Jun 18, 2021

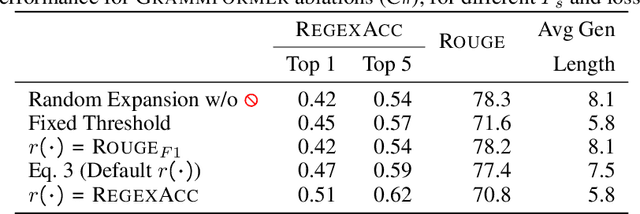
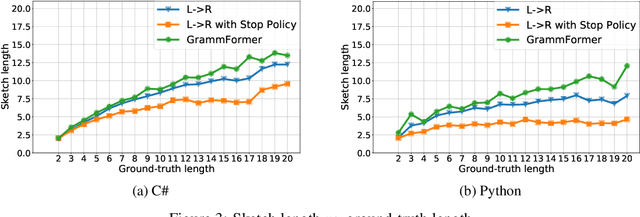
Traditional generative models are limited to predicting sequences of terminal tokens. However, ambiguities in the generation task may lead to incorrect outputs. Towards addressing this, we introduce Grammformers, transformer-based grammar-guided models that learn (without explicit supervision) to generate sketches -- sequences of tokens with holes. Through reinforcement learning, Grammformers learn to introduce holes avoiding the generation of incorrect tokens where there is ambiguity in the target task. We train Grammformers for statement-level source code completion, i.e., the generation of code snippets given an ambiguous user intent, such as a partial code context. We evaluate Grammformers on code completion for C# and Python and show that it generates 10-50% more accurate sketches compared to traditional generative models and 37-50% longer sketches compared to sketch-generating baselines trained with similar techniques.