 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefactorBench: Evaluating Stateful Reasoning in Language Agents Through Code
Mar 10, 2025Recent advances in language model (LM) agents and function calling have enabled autonomous, feedback-driven systems to solve problems across various digital domains. To better understand the unique limitations of LM agents, we introduce RefactorBench, a benchmark consisting of 100 large handcrafted multi-file refactoring tasks in popular open-source repositories. Solving tasks within RefactorBench requires thorough exploration of dependencies across multiple files and strong adherence to relevant instructions. Every task is defined by 3 natural language instructions of varying specificity and is mutually exclusive, allowing for the creation of longer combined tasks on the same repository. Baselines on RefactorBench reveal that current LM agents struggle with simple compositional tasks, solving only 22% of tasks with base instructions, in contrast to a human developer with short time constraints solving 87%. Through trajectory analysis, we identify various unique failure modes of LM agents, and further explore the failure mode of tracking past actions. By adapting a baseline agent to condition on representations of state, we achieve a 43.9% improvement in solving RefactorBench tasks. We further extend our state-aware approach to encompass entire digital environments and outline potential directions for future research. RefactorBench aims to support the study of LM agents by providing a set of real-world, multi-hop tasks within the realm of code.
AutoDev: Automated AI-Driven Development
Mar 13, 2024The landscape of software development has witnessed a paradigm shift with the advent of AI-powered assistants, exemplified by GitHub Copilot. However, existing solutions are not leveraging all the potential capabilities available in an IDE such as building, testing, executing code, git operations, etc. Therefore, they are constrained by their limited capabilities, primarily focusing on suggesting code snippets and file manipulation within a chat-based interface. To fill this gap, we present AutoDev, a fully automated AI-driven software development framework, designed for autonomous planning and execution of intricate software engineering tasks. AutoDev enables users to define complex software engineering objectives, which are assigned to AutoDev's autonomous AI Agents to achieve. These AI agents can perform diverse operations on a codebase, including file editing, retrieval, build processes, execution, testing, and git operations. They also have access to files, compiler output, build and testing logs, static analysis tools, and more. This enables the AI Agents to execute tasks in a fully automated manner with a comprehensive understanding of the contextual information required. Furthermore, AutoDev establishes a secure development environment by confining all operations within Docker containers. This framework incorporates guardrails to ensure user privacy and file security, allowing users to define specific permitted or restricted commands and operations within AutoDev. In our evaluation, we tested AutoDev on the HumanEval dataset, obtaining promising results with 91.5% and 87.8% of Pass@1 for code generation and test generation respectively, demonstrating its effectiveness in automating software engineering tasks while maintaining a secure and user-controlled development environment.
Copilot Evaluation Harness: Evaluating LLM-Guided Software Programming
Feb 22, 2024The integration of Large Language Models (LLMs) into Development Environments (IDEs) has become a focal point in modern software development. LLMs such as OpenAI GPT-3.5/4 and Code Llama offer the potential to significantly augment developer productivity by serving as intelligent, chat-driven programming assistants. However, utilizing LLMs out of the box is unlikely to be optimal for any given scenario. Rather, each system requires the LLM to be honed to its set of heuristics to ensure the best performance. In this paper, we introduce the Copilot evaluation harness: a set of data and tools for evaluating LLM-guided IDE interactions, covering various programming scenarios and languages. We propose our metrics as a more robust and information-dense evaluation than previous state of the art evaluation systems. We design and compute both static and execution based success metrics for scenarios encompassing a wide range of developer tasks, including code generation from natural language (generate), documentation generation from code (doc), test case generation (test), bug-fixing (fix), and workspace understanding and query resolution (workspace). These success metrics are designed to evaluate the performance of LLMs within a given IDE and its respective parameter space. Our learnings from evaluating three common LLMs using these metrics can inform the development and validation of future scenarios in LLM guided IDEs.
AdaptivePaste: Code Adaptation through Learning Semantics-aware Variable Usage Representations
May 23, 2022


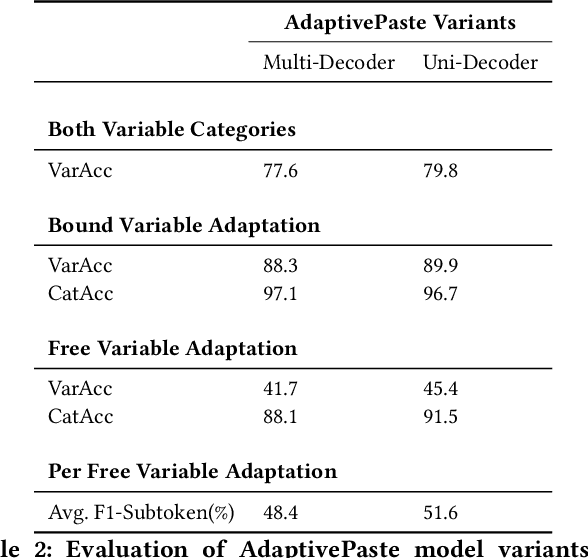
In software development, it is common for programmers to copy-paste code snippets and then adapt them to their use case. This scenario motivates \textit{code adaptation} task -- a variant of program repair which aims to adapt all variable identifiers in a pasted snippet of code to the surrounding, preexisting source code. Nevertheless, no existing approach have been shown to effectively address this task. In this paper, we introduce AdaptivePaste, a learning-based approach to source code adaptation, based on the transformer model and a dedicated dataflow-aware deobfuscation pre-training task to learn meaningful representations of variable usage patterns. We evaluate AdaptivePaste on a dataset of code snippets in Python. Evaluation results suggest that our model can learn to adapt copy-pasted code with 79.8\% accuracy.