 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefactorBench: Evaluating Stateful Reasoning in Language Agents Through Code
Mar 10, 2025Recent advances in language model (LM) agents and function calling have enabled autonomous, feedback-driven systems to solve problems across various digital domains. To better understand the unique limitations of LM agents, we introduce RefactorBench, a benchmark consisting of 100 large handcrafted multi-file refactoring tasks in popular open-source repositories. Solving tasks within RefactorBench requires thorough exploration of dependencies across multiple files and strong adherence to relevant instructions. Every task is defined by 3 natural language instructions of varying specificity and is mutually exclusive, allowing for the creation of longer combined tasks on the same repository. Baselines on RefactorBench reveal that current LM agents struggle with simple compositional tasks, solving only 22% of tasks with base instructions, in contrast to a human developer with short time constraints solving 87%. Through trajectory analysis, we identify various unique failure modes of LM agents, and further explore the failure mode of tracking past actions. By adapting a baseline agent to condition on representations of state, we achieve a 43.9% improvement in solving RefactorBench tasks. We further extend our state-aware approach to encompass entire digital environments and outline potential directions for future research. RefactorBench aims to support the study of LM agents by providing a set of real-world, multi-hop tasks within the realm of code.
Is Next Token Prediction Sufficient for GPT? Exploration on Code Logic Comprehension
Apr 13, 2024



Large language models (LLMs) has experienced exponential growth, they demonstrate remarkable performance across various tasks. Notwithstanding, contemporary research primarily centers on enhancing the size and quality of pretraining data, still utilizing the next token prediction task on autoregressive transformer model structure. The efficacy of this task in truly facilitating the model's comprehension of code logic remains questionable, we speculate that it still interprets code as mere text, while human emphasizes the underlying logical knowledge. In order to prove it, we introduce a new task, "Logically Equivalent Code Selection," which necessitates the selection of logically equivalent code from a candidate set, given a query code. Our experimental findings indicate that current LLMs underperform in this task, since they understand code by unordered bag of keywords. To ameliorate their performance, we propose an advanced pretraining task, "Next Token Prediction+". This task aims to modify the sentence embedding distribution of the LLM without sacrificing its generative capabilities. Our experimental results reveal that following this pretraining, both Code Llama and StarCoder, the prevalent code domain pretraining models, display significant improvements on our logically equivalent code selection task and the code completion task.
AutoDev: Automated AI-Driven Development
Mar 13, 2024The landscape of software development has witnessed a paradigm shift with the advent of AI-powered assistants, exemplified by GitHub Copilot. However, existing solutions are not leveraging all the potential capabilities available in an IDE such as building, testing, executing code, git operations, etc. Therefore, they are constrained by their limited capabilities, primarily focusing on suggesting code snippets and file manipulation within a chat-based interface. To fill this gap, we present AutoDev, a fully automated AI-driven software development framework, designed for autonomous planning and execution of intricate software engineering tasks. AutoDev enables users to define complex software engineering objectives, which are assigned to AutoDev's autonomous AI Agents to achieve. These AI agents can perform diverse operations on a codebase, including file editing, retrieval, build processes, execution, testing, and git operations. They also have access to files, compiler output, build and testing logs, static analysis tools, and more. This enables the AI Agents to execute tasks in a fully automated manner with a comprehensive understanding of the contextual information required. Furthermore, AutoDev establishes a secure development environment by confining all operations within Docker containers. This framework incorporates guardrails to ensure user privacy and file security, allowing users to define specific permitted or restricted commands and operations within AutoDev. In our evaluation, we tested AutoDev on the HumanEval dataset, obtaining promising results with 91.5% and 87.8% of Pass@1 for code generation and test generation respectively, demonstrating its effectiveness in automating software engineering tasks while maintaining a secure and user-controlled development environment.
Copilot Evaluation Harness: Evaluating LLM-Guided Software Programming
Feb 22, 2024The integration of Large Language Models (LLMs) into Development Environments (IDEs) has become a focal point in modern software development. LLMs such as OpenAI GPT-3.5/4 and Code Llama offer the potential to significantly augment developer productivity by serving as intelligent, chat-driven programming assistants. However, utilizing LLMs out of the box is unlikely to be optimal for any given scenario. Rather, each system requires the LLM to be honed to its set of heuristics to ensure the best performance. In this paper, we introduce the Copilot evaluation harness: a set of data and tools for evaluating LLM-guided IDE interactions, covering various programming scenarios and languages. We propose our metrics as a more robust and information-dense evaluation than previous state of the art evaluation systems. We design and compute both static and execution based success metrics for scenarios encompassing a wide range of developer tasks, including code generation from natural language (generate), documentation generation from code (doc), test case generation (test), bug-fixing (fix), and workspace understanding and query resolution (workspace). These success metrics are designed to evaluate the performance of LLMs within a given IDE and its respective parameter space. Our learnings from evaluating three common LLMs using these metrics can inform the development and validation of future scenarios in LLM guided IDEs.
Rethinking the Instruction Quality: LIFT is What You Need
Dec 27, 2023Instruction tuning, a specialized technique to enhance large language model (LLM) performance via instruction datasets, relies heavily on the quality of employed data. Existing quality improvement methods alter instruction data through dataset expansion or curation. However, the expansion method risks data redundancy, potentially compromising LLM performance, while the curation approach confines the LLM's potential to the original dataset. Our aim is to surpass the original data quality without encountering these shortcomings. To achieve this, we propose LIFT (LLM Instruction Fusion Transfer), a novel and versatile paradigm designed to elevate the instruction quality to new heights. LIFT strategically broadens data distribution to encompass more high-quality subspaces and eliminates redundancy, concentrating on high-quality segments across overall data subspaces. Experimental results demonstrate that, even with a limited quantity of high-quality instruction data selected by our paradigm, LLMs not only consistently uphold robust performance across various tasks but also surpass some state-of-the-art results, highlighting the significant improvement in instruction quality achieved by our paradigm.
SUT: Active Defects Probing for Transcompiler Models
Oct 22, 2023



Automatic Program translation has enormous application value and hence has been attracting significant interest from AI researchers. However, we observe that current program translation models still make elementary syntax errors, particularly, when the target language does not have syntax elements in the source language. Metrics like BLUE, CodeBLUE and computation accuracy may not expose these issues. In this paper we introduce a new metrics for programming language translation and these metrics address these basic syntax errors. We develop a novel active defects probing suite called Syntactic Unit Tests (SUT) which includes a highly interpretable evaluation harness for accuracy and test scoring. Experiments have shown that even powerful models like ChatGPT still make mistakes on these basic unit tests. Specifically, compared to previous program translation task evaluation dataset, its pass rate on our unit tests has decreased by 26.15%. Further our evaluation harness reveal syntactic element errors in which these models exhibit deficiencies.
Program Translation via Code Distillation
Oct 17, 2023



Software version migration and program translation are an important and costly part of the lifecycle of large codebases. Traditional machine translation relies on parallel corpora for supervised translation, which is not feasible for program translation due to a dearth of aligned data. Recent unsupervised neural machine translation techniques have overcome data limitations by included techniques such as back translation and low level compiler intermediate representations (IR). These methods face significant challenges due to the noise in code snippet alignment and the diversity of IRs respectively. In this paper we propose a novel model called Code Distillation (CoDist) whereby we capture the semantic and structural equivalence of code in a language agnostic intermediate representation. Distilled code serves as a translation pivot for any programming language, leading by construction to parallel corpora which scale to all available source code by simply applying the distillation compiler. We demonstrate that our approach achieves state-of-the-art performance on CodeXGLUE and TransCoder GeeksForGeeks translation benchmarks, with an average absolute increase of 12.7% on the TransCoder GeeksforGeeks translation benchmark compare to TransCoder-ST.
Reinforcement Learning from Automatic Feedback for High-Quality Unit Test Generation
Oct 03, 2023

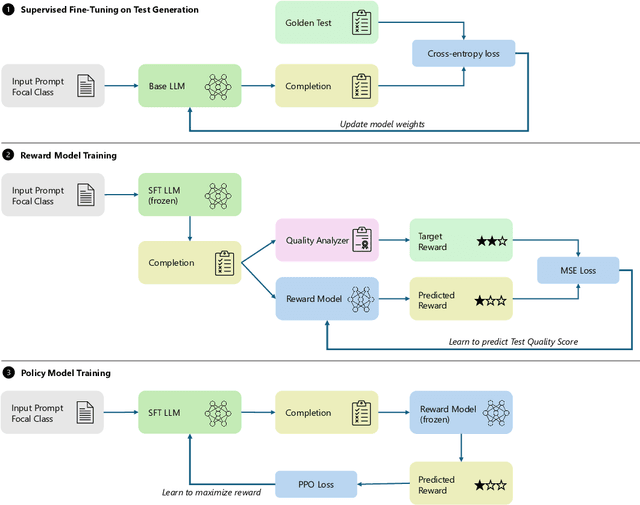
Software testing is a crucial aspect of software development, and the creation of high-quality tests that adhere to best practices is essential for effective maintenance. Recently, Large Language Models (LLMs) have gained popularity for code generation, including the automated creation of test cases. However, these LLMs are often trained on vast amounts of publicly available code, which may include test cases that do not adhere to best practices and may even contain test smells (anti-patterns). To address this issue, we propose a novel technique called Reinforcement Learning from Static Quality Metrics (RLSQM). To begin, we analyze the anti-patterns generated by the LLM and show that LLMs can generate undesirable test smells. Thus, we train specific reward models for each static quality metric, then utilize Proximal Policy Optimization (PPO) to train models for optimizing a single quality metric at a time. Furthermore, we amalgamate these rewards into a unified reward model aimed at capturing different best practices and quality aspects of tests. By comparing RL-trained models with those trained using supervised learning, we provide insights into how reliably utilize RL to improve test generation quality and into the effects of various training strategies. Our experimental results demonstrate that the RL-optimized model consistently generated high-quality test cases compared to the base LLM, improving the model by up to 21%, and successfully generates nearly 100% syntactically correct code. RLSQM also outperformed GPT-4 on four out of seven metrics. This represents a significant step towards enhancing the overall efficiency and reliability of software testing through Reinforcement Learning and static quality metrics. Our data are available at this link: https://figshare.com/s/ded476c8d4c221222849.
Predicting Code Coverage without Execution
Jul 25, 2023



Code coverage is a widely used metric for quantifying the extent to which program elements, such as statements or branches, are executed during testing. Calculating code coverage is resource-intensive, requiring code building and execution with additional overhead for the instrumentation. Furthermore, computing coverage of any snippet of code requires the whole program context. Using Machine Learning to amortize this expensive process could lower the cost of code coverage by requiring only the source code context, and the task of code coverage prediction can be a novel benchmark for judging the ability of models to understand code. We propose a novel benchmark task called Code Coverage Prediction for Large Language Models (LLMs). We formalize this task to evaluate the capability of LLMs in understanding code execution by determining which lines of a method are executed by a given test case and inputs. We curate and release a dataset we call COVERAGEEVAL by executing tests and code from the HumanEval dataset and collecting code coverage information. We report the performance of four state-of-the-art LLMs used for code-related tasks, including OpenAI's GPT-4 and GPT-3.5-Turbo, Google's BARD, and Anthropic's Claude, on the Code Coverage Prediction task. Finally, we argue that code coverage as a metric and pre-training data source are valuable for overall LLM performance on software engineering tasks.
RAPGen: An Approach for Fixing Code Inefficiencies in Zero-Shot
Jun 29, 2023


Performance bugs are non-functional bugs that can even manifest in well-tested commercial products. Fixing these performance bugs is an important yet challenging problem. In this work, we address this challenge and present a new approach called Retrieval-Augmented Prompt Generation (RAPGen). Given a code snippet with a performance issue, RAPGen first retrieves a prompt instruction from a pre-constructed knowledge-base of previous performance bug fixes and then generates a prompt using the retrieved instruction. It then uses this prompt on a Large Language Model (such as Codex) in zero-shot to generate a fix. We compare our approach with the various prompt variations and state of the art methods in the task of performance bug fixing. Our evaluation shows that RAPGen can generate performance improvement suggestions equivalent or better than a developer in ~60% of the cases, getting ~39% of them verbatim, in an expert-verified dataset of past performance changes made by C# developers.