 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe SWE-Bench Illusion: When State-of-the-Art LLMs Remember Instead of Reason
Jun 14, 2025



As large language models (LLMs) become increasingly capable and widely adopted, benchmarks play a central role in assessing their practical utility. For example, SWE-Bench Verified has emerged as a critical benchmark for evaluating LLMs' software engineering abilities, particularly their aptitude for resolving real-world GitHub issues. Recent LLMs show impressive performance on SWE-Bench, leading to optimism about their capacity for complex coding tasks. However, current evaluation protocols may overstate these models' true capabilities. It is crucial to distinguish LLMs' generalizable problem-solving ability and other learned artifacts. In this work, we introduce a diagnostic task: file path identification from issue descriptions alone, to probe models' underlying knowledge. We present empirical evidence that performance gains on SWE-Bench-Verified may be partially driven by memorization rather than genuine problem-solving. We show that state-of-the-art models achieve up to 76% accuracy in identifying buggy file paths using only issue descriptions, without access to repository structure. This performance is merely up to 53% on tasks from repositories not included in SWE-Bench, pointing to possible data contamination or memorization. These findings raise concerns about the validity of existing results and underscore the need for more robust, contamination-resistant benchmarks to reliably evaluate LLMs' coding abilities.
RefactorBench: Evaluating Stateful Reasoning in Language Agents Through Code
Mar 10, 2025Recent advances in language model (LM) agents and function calling have enabled autonomous, feedback-driven systems to solve problems across various digital domains. To better understand the unique limitations of LM agents, we introduce RefactorBench, a benchmark consisting of 100 large handcrafted multi-file refactoring tasks in popular open-source repositories. Solving tasks within RefactorBench requires thorough exploration of dependencies across multiple files and strong adherence to relevant instructions. Every task is defined by 3 natural language instructions of varying specificity and is mutually exclusive, allowing for the creation of longer combined tasks on the same repository. Baselines on RefactorBench reveal that current LM agents struggle with simple compositional tasks, solving only 22% of tasks with base instructions, in contrast to a human developer with short time constraints solving 87%. Through trajectory analysis, we identify various unique failure modes of LM agents, and further explore the failure mode of tracking past actions. By adapting a baseline agent to condition on representations of state, we achieve a 43.9% improvement in solving RefactorBench tasks. We further extend our state-aware approach to encompass entire digital environments and outline potential directions for future research. RefactorBench aims to support the study of LM agents by providing a set of real-world, multi-hop tasks within the realm of code.
RAPGen: An Approach for Fixing Code Inefficiencies in Zero-Shot
Jun 29, 2023


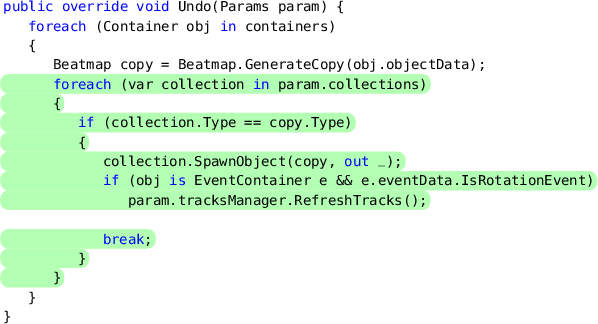
Performance bugs are non-functional bugs that can even manifest in well-tested commercial products. Fixing these performance bugs is an important yet challenging problem. In this work, we address this challenge and present a new approach called Retrieval-Augmented Prompt Generation (RAPGen). Given a code snippet with a performance issue, RAPGen first retrieves a prompt instruction from a pre-constructed knowledge-base of previous performance bug fixes and then generates a prompt using the retrieved instruction. It then uses this prompt on a Large Language Model (such as Codex) in zero-shot to generate a fix. We compare our approach with the various prompt variations and state of the art methods in the task of performance bug fixing. Our evaluation shows that RAPGen can generate performance improvement suggestions equivalent or better than a developer in ~60% of the cases, getting ~39% of them verbatim, in an expert-verified dataset of past performance changes made by C# developers.
DeepPERF: A Deep Learning-Based Approach For Improving Software Performance
Jun 27, 2022

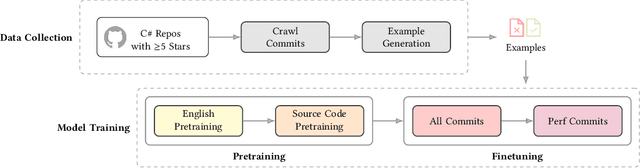

Improving software performance is an important yet challenging part of the software development cycle. Today, the majority of performance inefficiencies are identified and patched by performance experts. Recent advancements in deep learning approaches and the wide-spread availability of open source data creates a great opportunity to automate the identification and patching of performance problems. In this paper, we present DeepPERF, a transformer-based approach to suggest performance improvements for C# applications. We pretrain DeepPERF on English and Source code corpora and followed by finetuning for the task of generating performance improvement patches for C# applications. Our evaluation shows that our model can generate the same performance improvement suggestion as the developer fix in ~53% of the cases, getting ~34% of them verbatim in our expert-verified dataset of performance changes made by C# developers. Additionally, we evaluate DeepPERF on 50 open source C# repositories on GitHub using both benchmark and unit tests and find that our model is able to suggest valid performance improvements that can improve both CPU usage and Memory allocations. So far we've submitted 19 pull-requests with 28 different performance optimizations and 11 of these PRs have been approved by the project owners.
Generating Examples From CLI Usage: Can Transformers Help?
Apr 27, 2022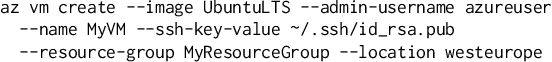
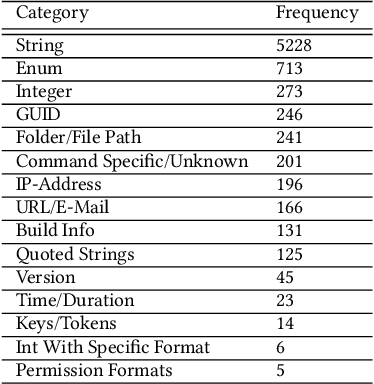
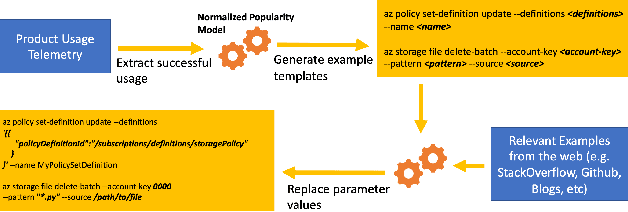
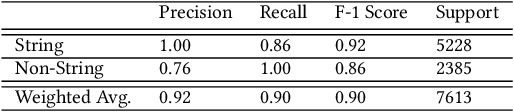
Continuous evolution in modern software often causes documentation, tutorials, and examples to be out of sync with changing interfaces and frameworks. Relying on outdated documentation and examples can lead programs to fail or be less efficient or even less secure. In response, programmers need to regularly turn to other resources on the web such as StackOverflow for examples to guide them in writing software. We recognize that this inconvenient, error-prone, and expensive process can be improved by using machine learning applied to software usage data. In this paper, we present our practical system which uses machine learning on large-scale telemetry data and documentation corpora, generating appropriate and complex examples that can be used to improve documentation. We discuss both feature-based and transformer-based machine learning approaches and demonstrate that our system achieves 100% coverage for the used functionalities in the product, providing up-to-date examples upon every release and reduces the numbers of PRs submitted by software owners writing and editing documentation by >68%. We also share valuable lessons learnt during the 3 years that our production quality system has been deployed for Azure Cloud Command Line Interface (Azure CLI).