 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepPERF: A Deep Learning-Based Approach For Improving Software Performance
Jun 27, 2022

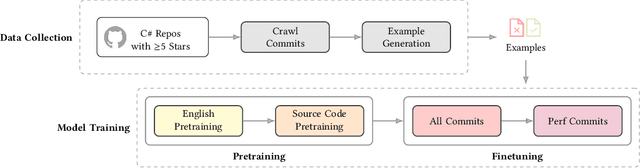

Improving software performance is an important yet challenging part of the software development cycle. Today, the majority of performance inefficiencies are identified and patched by performance experts. Recent advancements in deep learning approaches and the wide-spread availability of open source data creates a great opportunity to automate the identification and patching of performance problems. In this paper, we present DeepPERF, a transformer-based approach to suggest performance improvements for C# applications. We pretrain DeepPERF on English and Source code corpora and followed by finetuning for the task of generating performance improvement patches for C# applications. Our evaluation shows that our model can generate the same performance improvement suggestion as the developer fix in ~53% of the cases, getting ~34% of them verbatim in our expert-verified dataset of performance changes made by C# developers. Additionally, we evaluate DeepPERF on 50 open source C# repositories on GitHub using both benchmark and unit tests and find that our model is able to suggest valid performance improvements that can improve both CPU usage and Memory allocations. So far we've submitted 19 pull-requests with 28 different performance optimizations and 11 of these PRs have been approved by the project owners.
Generating Examples From CLI Usage: Can Transformers Help?
Apr 27, 2022
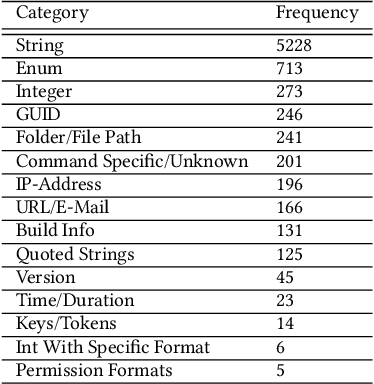
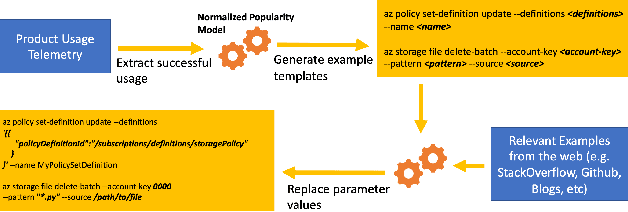
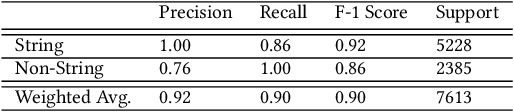
Continuous evolution in modern software often causes documentation, tutorials, and examples to be out of sync with changing interfaces and frameworks. Relying on outdated documentation and examples can lead programs to fail or be less efficient or even less secure. In response, programmers need to regularly turn to other resources on the web such as StackOverflow for examples to guide them in writing software. We recognize that this inconvenient, error-prone, and expensive process can be improved by using machine learning applied to software usage data. In this paper, we present our practical system which uses machine learning on large-scale telemetry data and documentation corpora, generating appropriate and complex examples that can be used to improve documentation. We discuss both feature-based and transformer-based machine learning approaches and demonstrate that our system achieves 100% coverage for the used functionalities in the product, providing up-to-date examples upon every release and reduces the numbers of PRs submitted by software owners writing and editing documentation by >68%. We also share valuable lessons learnt during the 3 years that our production quality system has been deployed for Azure Cloud Command Line Interface (Azure CLI).
Training and Evaluating a Jupyter Notebook Data Science Assistant
Jan 30, 2022

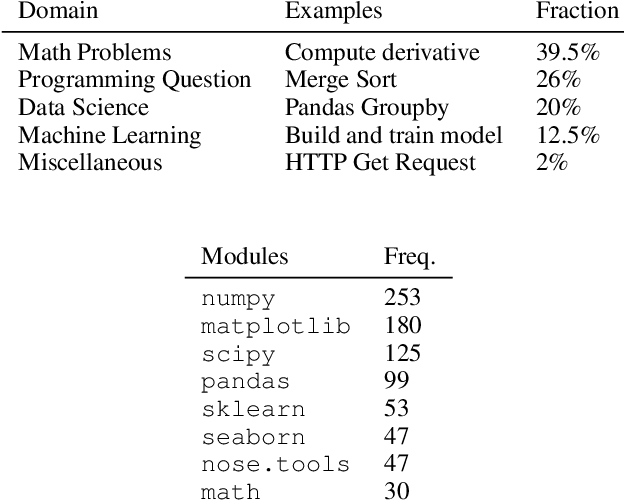

We study the feasibility of a Data Science assistant powered by a sequence-to-sequence transformer by training a new model JuPyT5 on all publicly available Jupyter Notebook GitHub repositories and developing a new metric: Data Science Problems (DSP). DSP is a collection of 1119 problems curated from 306 pedagogical notebooks with 92 dataset dependencies, natural language and Markdown problem descriptions, and assert-based unit tests. These notebooks were designed to test university students' mastery of various Python implementations of Math and Data Science, and we now leverage them to study the ability of JuPyT5 to understand and pass the tests. We analyze the content of DSP, validate its quality, and we find that given 100 sampling attempts JuPyT5 is able to solve 77.5\% of the DSP problems. We further present various ablation and statistical analyses and compare DSP to other recent natural language to code benchmarks.
Long-Range Modeling of Source Code Files with eWASH: Extended Window Access by Syntax Hierarchy
Sep 17, 2021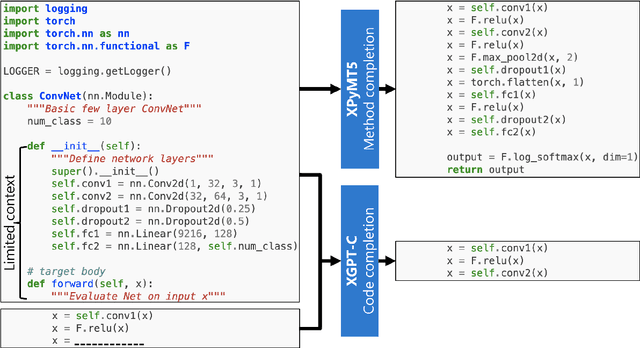
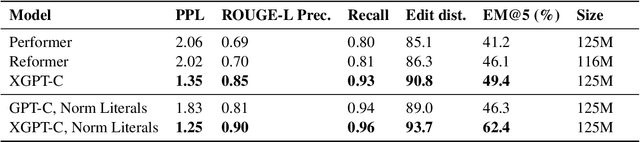

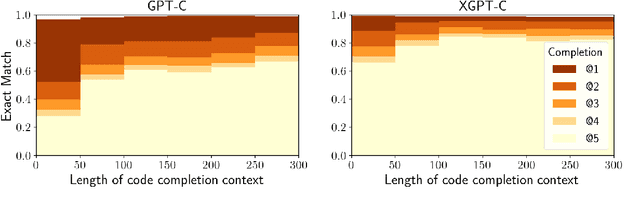
Statistical language modeling and translation with transformers have found many successful applications in program understanding and generation tasks, setting high benchmarks for tools in modern software development environments. The finite context window of these neural models means, however, that they will be unable to leverage the entire relevant context of large files and packages for any given task. While there are many efforts to extend the context window, we introduce an architecture-independent approach for leveraging the syntactic hierarchies of source code for incorporating entire file-level context into a fixed-length window. Using concrete syntax trees of each source file we extract syntactic hierarchies and integrate them into context window by selectively removing from view more specific, less relevant scopes for a given task. We evaluate this approach on code generation tasks and joint translation of natural language and source code in Python programming language, achieving a new state-of-the-art in code completion and summarization for Python in the CodeXGLUE benchmark. We also introduce new CodeXGLUE benchmarks for user-experience-motivated tasks: code completion with normalized literals, method body completion/code summarization conditioned on file-level context.
Distilling Transformers for Neural Cross-Domain Search
Aug 06, 2021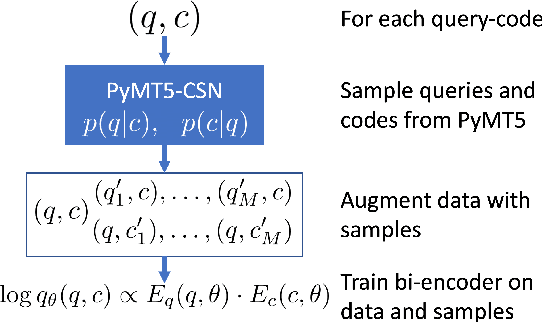


Pre-trained transformers have recently clinched top spots in the gamut of natural language tasks and pioneered solutions to software engineering tasks. Even information retrieval has not been immune to the charm of the transformer, though their large size and cost is generally a barrier to deployment. While there has been much work in streamlining, caching, and modifying transformer architectures for production, here we explore a new direction: distilling a large pre-trained translation model into a lightweight bi-encoder which can be efficiently cached and queried. We argue from a probabilistic perspective that sequence-to-sequence models are a conceptually ideal---albeit highly impractical---retriever. We derive a new distillation objective, implementing it as a data augmentation scheme. Using natural language source code search as a case study for cross-domain search, we demonstrate the validity of this idea by significantly improving upon the current leader of the CodeSearchNet challenge, a recent natural language code search benchmark.
DeepDebug: Fixing Python Bugs Using Stack Traces, Backtranslation, and Code Skeletons
May 19, 2021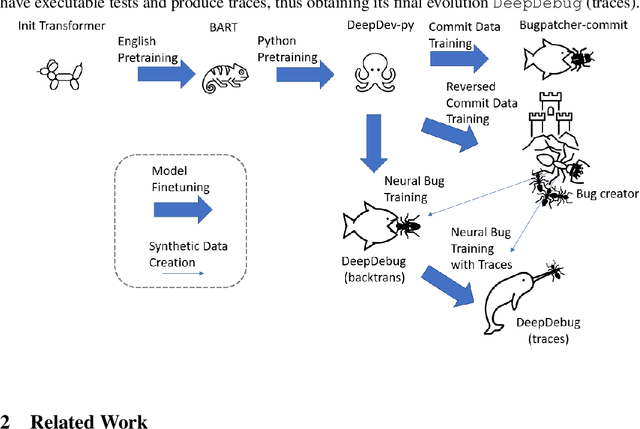
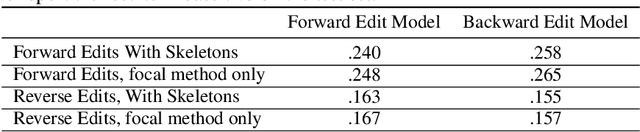
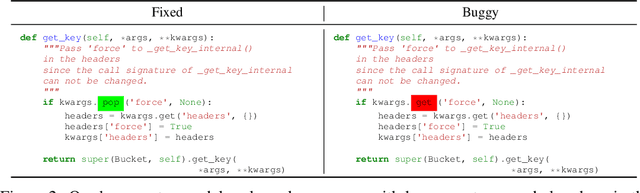

The joint task of bug localization and program repair is an integral part of the software development process. In this work we present DeepDebug, an approach to automated debugging using large, pretrained transformers. We begin by training a bug-creation model on reversed commit data for the purpose of generating synthetic bugs. We apply these synthetic bugs toward two ends. First, we directly train a backtranslation model on all functions from 200K repositories. Next, we focus on 10K repositories for which we can execute tests, and create buggy versions of all functions in those repositories that are covered by passing tests. This provides us with rich debugging information such as stack traces and print statements, which we use to finetune our model which was pretrained on raw source code. Finally, we strengthen all our models by expanding the context window beyond the buggy function itself, and adding a skeleton consisting of that function's parent class, imports, signatures, docstrings, and method bodies, in order of priority. On the QuixBugs benchmark, we increase the total number of fixes found by over 50%, while also decreasing the false positive rate from 35% to 5% and decreasing the timeout from six hours to one minute. On our own benchmark of executable tests, our model fixes 68% of all bugs on its first attempt without using traces, and after adding traces it fixes 75% on first attempt. We will open-source our framework and validation set for evaluating on executable tests.
PyMT5: multi-mode translation of natural language and Python code with transformers
Oct 07, 2020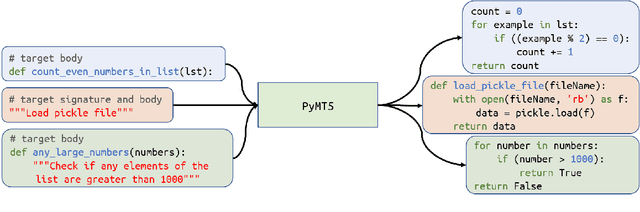
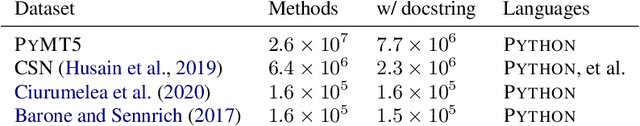
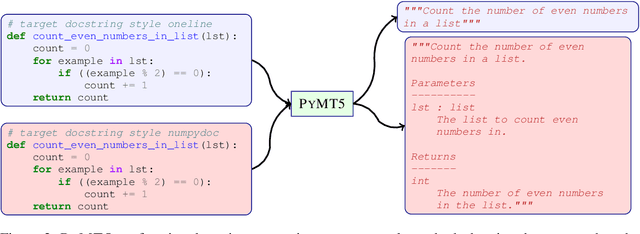
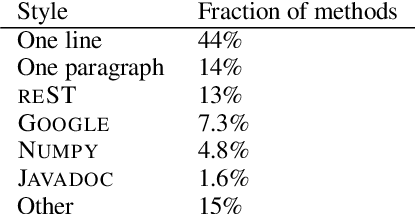
Simultaneously modeling source code and natural language has many exciting applications in automated software development and understanding. Pursuant to achieving such technology, we introduce PyMT5, the Python method text-to-text transfer transformer, which is trained to translate between all pairs of Python method feature combinations: a single model that can both predict whole methods from natural language documentation strings (docstrings) and summarize code into docstrings of any common style. We present an analysis and modeling effort of a large-scale parallel corpus of 26 million Python methods and 7.7 million method-docstring pairs, demonstrating that for docstring and method generation, PyMT5 outperforms similarly-sized auto-regressive language models (GPT2) which were English pre-trained or randomly initialized. On the CodeSearchNet test set, our best model predicts 92.1% syntactically correct method bodies, achieved a BLEU score of 8.59 for method generation and 16.3 for docstring generation (summarization), and achieved a ROUGE-L F-score of 24.8 for method generation and 36.7 for docstring generation.
On the Use of ArXiv as a Dataset
Apr 30, 2019

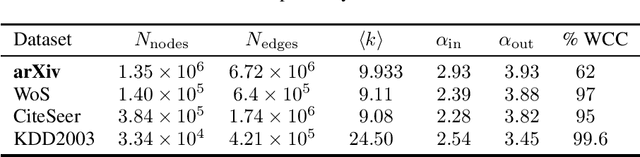
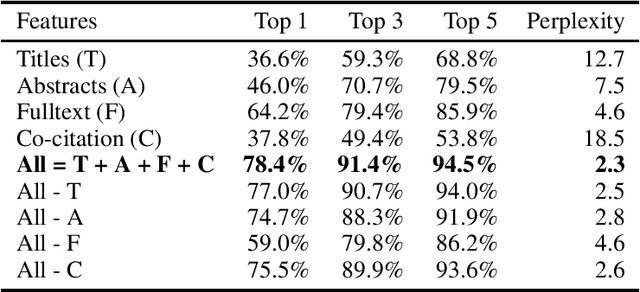
The arXiv has collected 1.5 million pre-print articles over 28 years, hosting literature from scientific fields including Physics, Mathematics, and Computer Science. Each pre-print features text, figures, authors, citations, categories, and other metadata. These rich, multi-modal features, combined with the natural graph structure---created by citation, affiliation, and co-authorship---makes the arXiv an exciting candidate for benchmarking next-generation models. Here we take the first necessary steps toward this goal, by providing a pipeline which standardizes and simplifies access to the arXiv's publicly available data. We use this pipeline to extract and analyze a 6.7 million edge citation graph, with an 11 billion word corpus of full-text research articles. We present some baseline classification results, and motivate application of more exciting generative graph models.