 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining and Evaluating a Jupyter Notebook Data Science Assistant
Jan 30, 2022

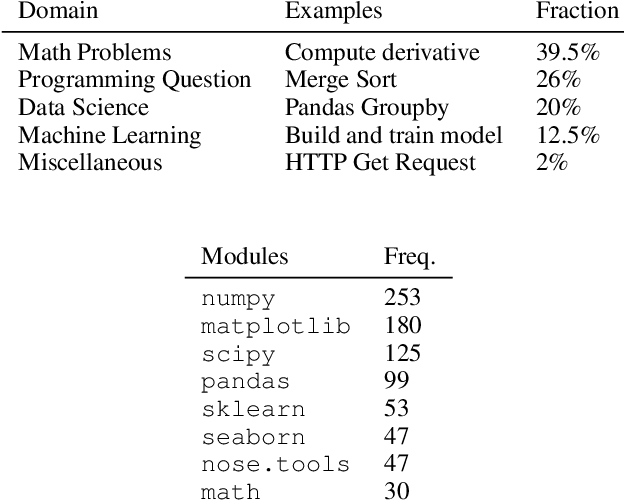

We study the feasibility of a Data Science assistant powered by a sequence-to-sequence transformer by training a new model JuPyT5 on all publicly available Jupyter Notebook GitHub repositories and developing a new metric: Data Science Problems (DSP). DSP is a collection of 1119 problems curated from 306 pedagogical notebooks with 92 dataset dependencies, natural language and Markdown problem descriptions, and assert-based unit tests. These notebooks were designed to test university students' mastery of various Python implementations of Math and Data Science, and we now leverage them to study the ability of JuPyT5 to understand and pass the tests. We analyze the content of DSP, validate its quality, and we find that given 100 sampling attempts JuPyT5 is able to solve 77.5\% of the DSP problems. We further present various ablation and statistical analyses and compare DSP to other recent natural language to code benchmarks.
DeepDebug: Fixing Python Bugs Using Stack Traces, Backtranslation, and Code Skeletons
May 19, 2021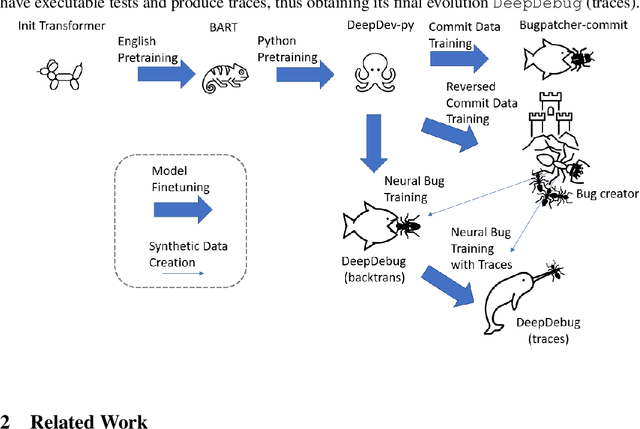
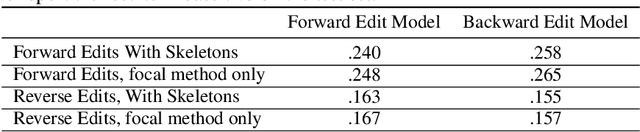
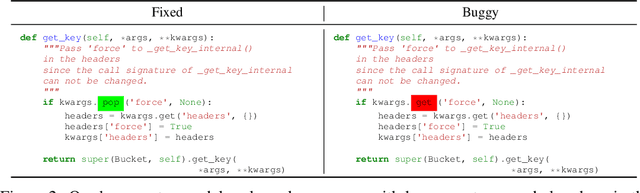

The joint task of bug localization and program repair is an integral part of the software development process. In this work we present DeepDebug, an approach to automated debugging using large, pretrained transformers. We begin by training a bug-creation model on reversed commit data for the purpose of generating synthetic bugs. We apply these synthetic bugs toward two ends. First, we directly train a backtranslation model on all functions from 200K repositories. Next, we focus on 10K repositories for which we can execute tests, and create buggy versions of all functions in those repositories that are covered by passing tests. This provides us with rich debugging information such as stack traces and print statements, which we use to finetune our model which was pretrained on raw source code. Finally, we strengthen all our models by expanding the context window beyond the buggy function itself, and adding a skeleton consisting of that function's parent class, imports, signatures, docstrings, and method bodies, in order of priority. On the QuixBugs benchmark, we increase the total number of fixes found by over 50%, while also decreasing the false positive rate from 35% to 5% and decreasing the timeout from six hours to one minute. On our own benchmark of executable tests, our model fixes 68% of all bugs on its first attempt without using traces, and after adding traces it fixes 75% on first attempt. We will open-source our framework and validation set for evaluating on executable tests.