 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining and Evaluating a Jupyter Notebook Data Science Assistant
Paper and Code


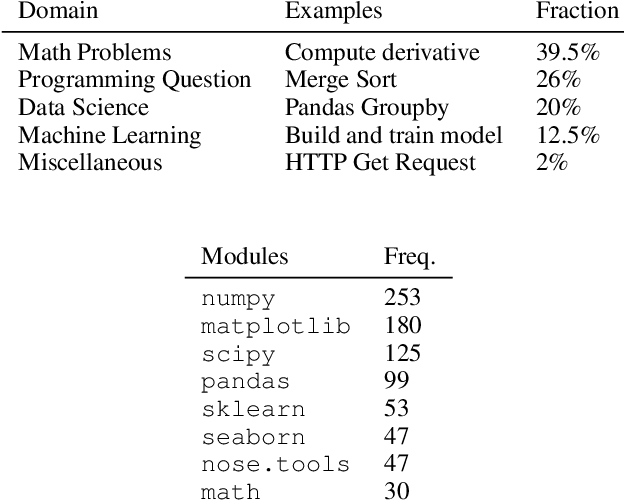

We study the feasibility of a Data Science assistant powered by a sequence-to-sequence transformer by training a new model JuPyT5 on all publicly available Jupyter Notebook GitHub repositories and developing a new metric: Data Science Problems (DSP). DSP is a collection of 1119 problems curated from 306 pedagogical notebooks with 92 dataset dependencies, natural language and Markdown problem descriptions, and assert-based unit tests. These notebooks were designed to test university students' mastery of various Python implementations of Math and Data Science, and we now leverage them to study the ability of JuPyT5 to understand and pass the tests. We analyze the content of DSP, validate its quality, and we find that given 100 sampling attempts JuPyT5 is able to solve 77.5\% of the DSP problems. We further present various ablation and statistical analyses and compare DSP to other recent natural language to code benchmarks.