 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClosing the Gap: A User Study on the Real-world Usefulness of AI-powered Vulnerability Detection & Repair in the IDE
Dec 18, 2024This paper presents the first empirical study of a vulnerability detection and fix tool with professional software developers on real projects that they own. We implemented DeepVulGuard, an IDE-integrated tool based on state-of-the-art detection and fix models, and show that it has promising performance on benchmarks of historic vulnerability data. DeepVulGuard scans code for vulnerabilities (including identifying the vulnerability type and vulnerable region of code), suggests fixes, provides natural-language explanations for alerts and fixes, leveraging chat interfaces. We recruited 17 professional software developers at Microsoft, observed their usage of the tool on their code, and conducted interviews to assess the tool's usefulness, speed, trust, relevance, and workflow integration. We also gathered detailed qualitative feedback on users' perceptions and their desired features. Study participants scanned a total of 24 projects, 6.9k files, and over 1.7 million lines of source code, and generated 170 alerts and 50 fix suggestions. We find that although state-of-the-art AI-powered detection and fix tools show promise, they are not yet practical for real-world use due to a high rate of false positives and non-applicable fixes. User feedback reveals several actionable pain points, ranging from incomplete context to lack of customization for the user's codebase. Additionally, we explore how AI features, including confidence scores, explanations, and chat interaction, can apply to vulnerability detection and fixing. Based on these insights, we offer practical recommendations for evaluating and deploying AI detection and fix models. Our code and data are available at https://doi.org/10.6084/m9.figshare.26367139.
Copilot Evaluation Harness: Evaluating LLM-Guided Software Programming
Feb 22, 2024The integration of Large Language Models (LLMs) into Development Environments (IDEs) has become a focal point in modern software development. LLMs such as OpenAI GPT-3.5/4 and Code Llama offer the potential to significantly augment developer productivity by serving as intelligent, chat-driven programming assistants. However, utilizing LLMs out of the box is unlikely to be optimal for any given scenario. Rather, each system requires the LLM to be honed to its set of heuristics to ensure the best performance. In this paper, we introduce the Copilot evaluation harness: a set of data and tools for evaluating LLM-guided IDE interactions, covering various programming scenarios and languages. We propose our metrics as a more robust and information-dense evaluation than previous state of the art evaluation systems. We design and compute both static and execution based success metrics for scenarios encompassing a wide range of developer tasks, including code generation from natural language (generate), documentation generation from code (doc), test case generation (test), bug-fixing (fix), and workspace understanding and query resolution (workspace). These success metrics are designed to evaluate the performance of LLMs within a given IDE and its respective parameter space. Our learnings from evaluating three common LLMs using these metrics can inform the development and validation of future scenarios in LLM guided IDEs.
Generating Examples From CLI Usage: Can Transformers Help?
Apr 27, 2022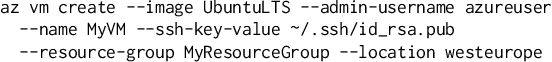
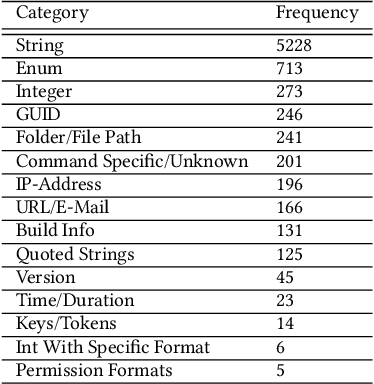
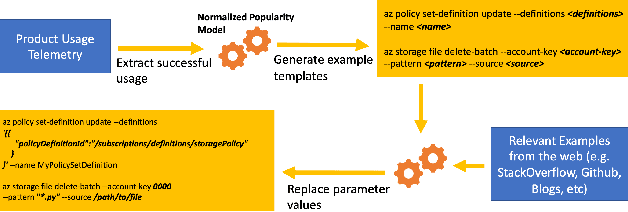
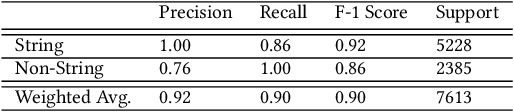
Continuous evolution in modern software often causes documentation, tutorials, and examples to be out of sync with changing interfaces and frameworks. Relying on outdated documentation and examples can lead programs to fail or be less efficient or even less secure. In response, programmers need to regularly turn to other resources on the web such as StackOverflow for examples to guide them in writing software. We recognize that this inconvenient, error-prone, and expensive process can be improved by using machine learning applied to software usage data. In this paper, we present our practical system which uses machine learning on large-scale telemetry data and documentation corpora, generating appropriate and complex examples that can be used to improve documentation. We discuss both feature-based and transformer-based machine learning approaches and demonstrate that our system achieves 100% coverage for the used functionalities in the product, providing up-to-date examples upon every release and reduces the numbers of PRs submitted by software owners writing and editing documentation by >68%. We also share valuable lessons learnt during the 3 years that our production quality system has been deployed for Azure Cloud Command Line Interface (Azure CLI).