 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe SWE-Bench Illusion: When State-of-the-Art LLMs Remember Instead of Reason
Jun 14, 2025As large language models (LLMs) become increasingly capable and widely adopted, benchmarks play a central role in assessing their practical utility. For example, SWE-Bench Verified has emerged as a critical benchmark for evaluating LLMs' software engineering abilities, particularly their aptitude for resolving real-world GitHub issues. Recent LLMs show impressive performance on SWE-Bench, leading to optimism about their capacity for complex coding tasks. However, current evaluation protocols may overstate these models' true capabilities. It is crucial to distinguish LLMs' generalizable problem-solving ability and other learned artifacts. In this work, we introduce a diagnostic task: file path identification from issue descriptions alone, to probe models' underlying knowledge. We present empirical evidence that performance gains on SWE-Bench-Verified may be partially driven by memorization rather than genuine problem-solving. We show that state-of-the-art models achieve up to 76% accuracy in identifying buggy file paths using only issue descriptions, without access to repository structure. This performance is merely up to 53% on tasks from repositories not included in SWE-Bench, pointing to possible data contamination or memorization. These findings raise concerns about the validity of existing results and underscore the need for more robust, contamination-resistant benchmarks to reliably evaluate LLMs' coding abilities.
RefactorBench: Evaluating Stateful Reasoning in Language Agents Through Code
Mar 10, 2025Recent advances in language model (LM) agents and function calling have enabled autonomous, feedback-driven systems to solve problems across various digital domains. To better understand the unique limitations of LM agents, we introduce RefactorBench, a benchmark consisting of 100 large handcrafted multi-file refactoring tasks in popular open-source repositories. Solving tasks within RefactorBench requires thorough exploration of dependencies across multiple files and strong adherence to relevant instructions. Every task is defined by 3 natural language instructions of varying specificity and is mutually exclusive, allowing for the creation of longer combined tasks on the same repository. Baselines on RefactorBench reveal that current LM agents struggle with simple compositional tasks, solving only 22% of tasks with base instructions, in contrast to a human developer with short time constraints solving 87%. Through trajectory analysis, we identify various unique failure modes of LM agents, and further explore the failure mode of tracking past actions. By adapting a baseline agent to condition on representations of state, we achieve a 43.9% improvement in solving RefactorBench tasks. We further extend our state-aware approach to encompass entire digital environments and outline potential directions for future research. RefactorBench aims to support the study of LM agents by providing a set of real-world, multi-hop tasks within the realm of code.
Closing the Gap: A User Study on the Real-world Usefulness of AI-powered Vulnerability Detection & Repair in the IDE
Dec 18, 2024This paper presents the first empirical study of a vulnerability detection and fix tool with professional software developers on real projects that they own. We implemented DeepVulGuard, an IDE-integrated tool based on state-of-the-art detection and fix models, and show that it has promising performance on benchmarks of historic vulnerability data. DeepVulGuard scans code for vulnerabilities (including identifying the vulnerability type and vulnerable region of code), suggests fixes, provides natural-language explanations for alerts and fixes, leveraging chat interfaces. We recruited 17 professional software developers at Microsoft, observed their usage of the tool on their code, and conducted interviews to assess the tool's usefulness, speed, trust, relevance, and workflow integration. We also gathered detailed qualitative feedback on users' perceptions and their desired features. Study participants scanned a total of 24 projects, 6.9k files, and over 1.7 million lines of source code, and generated 170 alerts and 50 fix suggestions. We find that although state-of-the-art AI-powered detection and fix tools show promise, they are not yet practical for real-world use due to a high rate of false positives and non-applicable fixes. User feedback reveals several actionable pain points, ranging from incomplete context to lack of customization for the user's codebase. Additionally, we explore how AI features, including confidence scores, explanations, and chat interaction, can apply to vulnerability detection and fixing. Based on these insights, we offer practical recommendations for evaluating and deploying AI detection and fix models. Our code and data are available at https://doi.org/10.6084/m9.figshare.26367139.
AutoDev: Automated AI-Driven Development
Mar 13, 2024The landscape of software development has witnessed a paradigm shift with the advent of AI-powered assistants, exemplified by GitHub Copilot. However, existing solutions are not leveraging all the potential capabilities available in an IDE such as building, testing, executing code, git operations, etc. Therefore, they are constrained by their limited capabilities, primarily focusing on suggesting code snippets and file manipulation within a chat-based interface. To fill this gap, we present AutoDev, a fully automated AI-driven software development framework, designed for autonomous planning and execution of intricate software engineering tasks. AutoDev enables users to define complex software engineering objectives, which are assigned to AutoDev's autonomous AI Agents to achieve. These AI agents can perform diverse operations on a codebase, including file editing, retrieval, build processes, execution, testing, and git operations. They also have access to files, compiler output, build and testing logs, static analysis tools, and more. This enables the AI Agents to execute tasks in a fully automated manner with a comprehensive understanding of the contextual information required. Furthermore, AutoDev establishes a secure development environment by confining all operations within Docker containers. This framework incorporates guardrails to ensure user privacy and file security, allowing users to define specific permitted or restricted commands and operations within AutoDev. In our evaluation, we tested AutoDev on the HumanEval dataset, obtaining promising results with 91.5% and 87.8% of Pass@1 for code generation and test generation respectively, demonstrating its effectiveness in automating software engineering tasks while maintaining a secure and user-controlled development environment.
Copilot Evaluation Harness: Evaluating LLM-Guided Software Programming
Feb 22, 2024The integration of Large Language Models (LLMs) into Development Environments (IDEs) has become a focal point in modern software development. LLMs such as OpenAI GPT-3.5/4 and Code Llama offer the potential to significantly augment developer productivity by serving as intelligent, chat-driven programming assistants. However, utilizing LLMs out of the box is unlikely to be optimal for any given scenario. Rather, each system requires the LLM to be honed to its set of heuristics to ensure the best performance. In this paper, we introduce the Copilot evaluation harness: a set of data and tools for evaluating LLM-guided IDE interactions, covering various programming scenarios and languages. We propose our metrics as a more robust and information-dense evaluation than previous state of the art evaluation systems. We design and compute both static and execution based success metrics for scenarios encompassing a wide range of developer tasks, including code generation from natural language (generate), documentation generation from code (doc), test case generation (test), bug-fixing (fix), and workspace understanding and query resolution (workspace). These success metrics are designed to evaluate the performance of LLMs within a given IDE and its respective parameter space. Our learnings from evaluating three common LLMs using these metrics can inform the development and validation of future scenarios in LLM guided IDEs.
RAPGen: An Approach for Fixing Code Inefficiencies in Zero-Shot
Jun 29, 2023


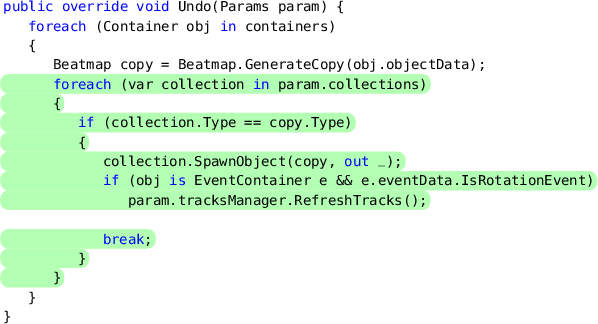
Performance bugs are non-functional bugs that can even manifest in well-tested commercial products. Fixing these performance bugs is an important yet challenging problem. In this work, we address this challenge and present a new approach called Retrieval-Augmented Prompt Generation (RAPGen). Given a code snippet with a performance issue, RAPGen first retrieves a prompt instruction from a pre-constructed knowledge-base of previous performance bug fixes and then generates a prompt using the retrieved instruction. It then uses this prompt on a Large Language Model (such as Codex) in zero-shot to generate a fix. We compare our approach with the various prompt variations and state of the art methods in the task of performance bug fixing. Our evaluation shows that RAPGen can generate performance improvement suggestions equivalent or better than a developer in ~60% of the cases, getting ~39% of them verbatim, in an expert-verified dataset of past performance changes made by C# developers.
DeepPERF: A Deep Learning-Based Approach For Improving Software Performance
Jun 27, 2022

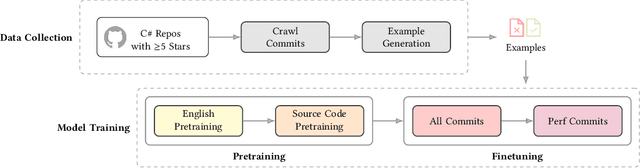

Improving software performance is an important yet challenging part of the software development cycle. Today, the majority of performance inefficiencies are identified and patched by performance experts. Recent advancements in deep learning approaches and the wide-spread availability of open source data creates a great opportunity to automate the identification and patching of performance problems. In this paper, we present DeepPERF, a transformer-based approach to suggest performance improvements for C# applications. We pretrain DeepPERF on English and Source code corpora and followed by finetuning for the task of generating performance improvement patches for C# applications. Our evaluation shows that our model can generate the same performance improvement suggestion as the developer fix in ~53% of the cases, getting ~34% of them verbatim in our expert-verified dataset of performance changes made by C# developers. Additionally, we evaluate DeepPERF on 50 open source C# repositories on GitHub using both benchmark and unit tests and find that our model is able to suggest valid performance improvements that can improve both CPU usage and Memory allocations. So far we've submitted 19 pull-requests with 28 different performance optimizations and 11 of these PRs have been approved by the project owners.
Generating Examples From CLI Usage: Can Transformers Help?
Apr 27, 2022
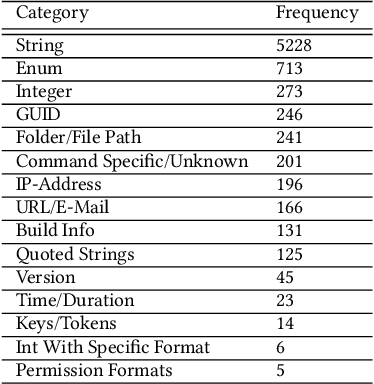
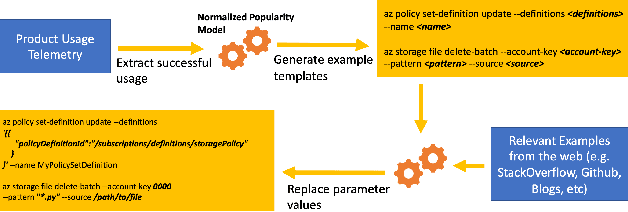
Continuous evolution in modern software often causes documentation, tutorials, and examples to be out of sync with changing interfaces and frameworks. Relying on outdated documentation and examples can lead programs to fail or be less efficient or even less secure. In response, programmers need to regularly turn to other resources on the web such as StackOverflow for examples to guide them in writing software. We recognize that this inconvenient, error-prone, and expensive process can be improved by using machine learning applied to software usage data. In this paper, we present our practical system which uses machine learning on large-scale telemetry data and documentation corpora, generating appropriate and complex examples that can be used to improve documentation. We discuss both feature-based and transformer-based machine learning approaches and demonstrate that our system achieves 100% coverage for the used functionalities in the product, providing up-to-date examples upon every release and reduces the numbers of PRs submitted by software owners writing and editing documentation by >68%. We also share valuable lessons learnt during the 3 years that our production quality system has been deployed for Azure Cloud Command Line Interface (Azure CLI).
Learning to Reduce False Positives in Analytic Bug Detectors
Mar 08, 2022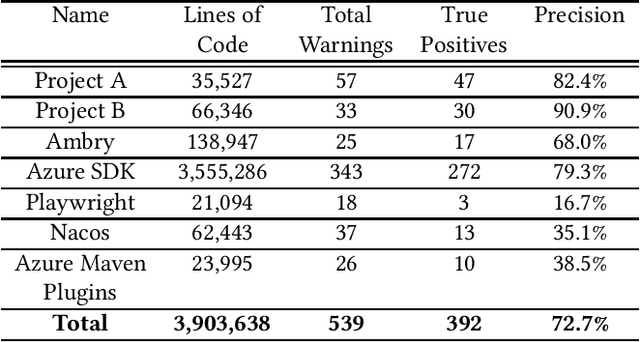
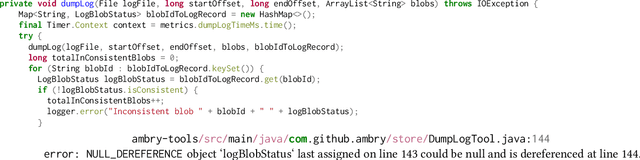
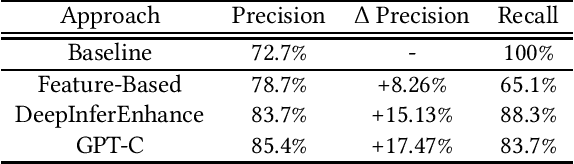
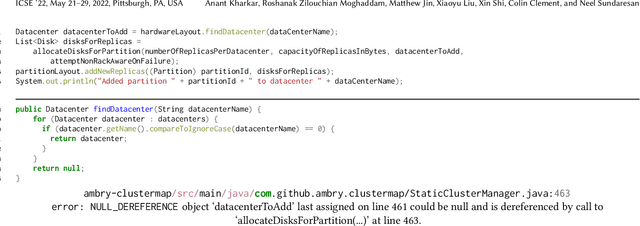
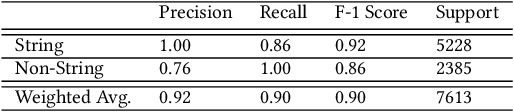
Due to increasingly complex software design and rapid iterative development, code defects and security vulnerabilities are prevalent in modern software. In response, programmers rely on static analysis tools to regularly scan their codebases and find potential bugs. In order to maximize coverage, however, these tools generally tend to report a significant number of false positives, requiring developers to manually verify each warning. To address this problem, we propose a Transformer-based learning approach to identify false positive bug warnings. We demonstrate that our models can improve the precision of static analysis by 17.5%. In addition, we validated the generalizability of this approach across two major bug types: null dereference and resource leak.