 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoDev: Automated AI-Driven Development
Mar 13, 2024The landscape of software development has witnessed a paradigm shift with the advent of AI-powered assistants, exemplified by GitHub Copilot. However, existing solutions are not leveraging all the potential capabilities available in an IDE such as building, testing, executing code, git operations, etc. Therefore, they are constrained by their limited capabilities, primarily focusing on suggesting code snippets and file manipulation within a chat-based interface. To fill this gap, we present AutoDev, a fully automated AI-driven software development framework, designed for autonomous planning and execution of intricate software engineering tasks. AutoDev enables users to define complex software engineering objectives, which are assigned to AutoDev's autonomous AI Agents to achieve. These AI agents can perform diverse operations on a codebase, including file editing, retrieval, build processes, execution, testing, and git operations. They also have access to files, compiler output, build and testing logs, static analysis tools, and more. This enables the AI Agents to execute tasks in a fully automated manner with a comprehensive understanding of the contextual information required. Furthermore, AutoDev establishes a secure development environment by confining all operations within Docker containers. This framework incorporates guardrails to ensure user privacy and file security, allowing users to define specific permitted or restricted commands and operations within AutoDev. In our evaluation, we tested AutoDev on the HumanEval dataset, obtaining promising results with 91.5% and 87.8% of Pass@1 for code generation and test generation respectively, demonstrating its effectiveness in automating software engineering tasks while maintaining a secure and user-controlled development environment.
Copilot Evaluation Harness: Evaluating LLM-Guided Software Programming
Feb 22, 2024The integration of Large Language Models (LLMs) into Development Environments (IDEs) has become a focal point in modern software development. LLMs such as OpenAI GPT-3.5/4 and Code Llama offer the potential to significantly augment developer productivity by serving as intelligent, chat-driven programming assistants. However, utilizing LLMs out of the box is unlikely to be optimal for any given scenario. Rather, each system requires the LLM to be honed to its set of heuristics to ensure the best performance. In this paper, we introduce the Copilot evaluation harness: a set of data and tools for evaluating LLM-guided IDE interactions, covering various programming scenarios and languages. We propose our metrics as a more robust and information-dense evaluation than previous state of the art evaluation systems. We design and compute both static and execution based success metrics for scenarios encompassing a wide range of developer tasks, including code generation from natural language (generate), documentation generation from code (doc), test case generation (test), bug-fixing (fix), and workspace understanding and query resolution (workspace). These success metrics are designed to evaluate the performance of LLMs within a given IDE and its respective parameter space. Our learnings from evaluating three common LLMs using these metrics can inform the development and validation of future scenarios in LLM guided IDEs.
Predicting Code Coverage without Execution
Jul 25, 2023



Code coverage is a widely used metric for quantifying the extent to which program elements, such as statements or branches, are executed during testing. Calculating code coverage is resource-intensive, requiring code building and execution with additional overhead for the instrumentation. Furthermore, computing coverage of any snippet of code requires the whole program context. Using Machine Learning to amortize this expensive process could lower the cost of code coverage by requiring only the source code context, and the task of code coverage prediction can be a novel benchmark for judging the ability of models to understand code. We propose a novel benchmark task called Code Coverage Prediction for Large Language Models (LLMs). We formalize this task to evaluate the capability of LLMs in understanding code execution by determining which lines of a method are executed by a given test case and inputs. We curate and release a dataset we call COVERAGEEVAL by executing tests and code from the HumanEval dataset and collecting code coverage information. We report the performance of four state-of-the-art LLMs used for code-related tasks, including OpenAI's GPT-4 and GPT-3.5-Turbo, Google's BARD, and Anthropic's Claude, on the Code Coverage Prediction task. Finally, we argue that code coverage as a metric and pre-training data source are valuable for overall LLM performance on software engineering tasks.
Protecting Privacy of Users in Brain-Computer Interface Applications
Jul 02, 2019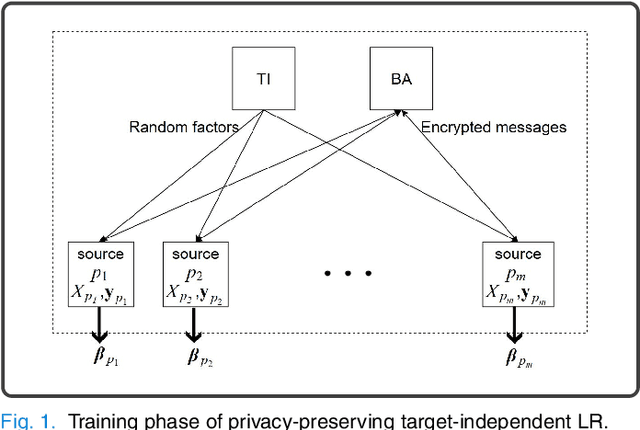
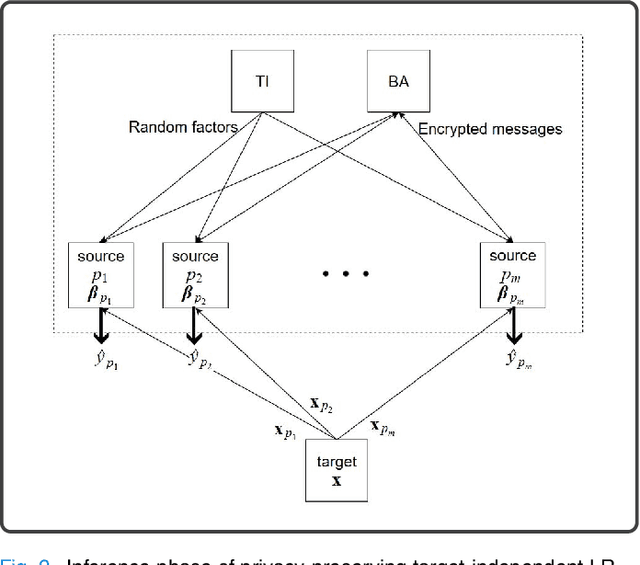
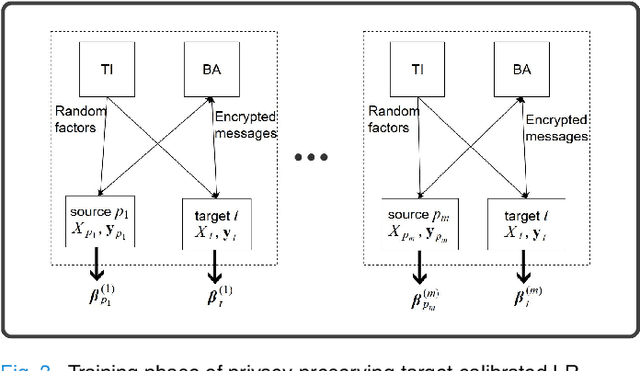
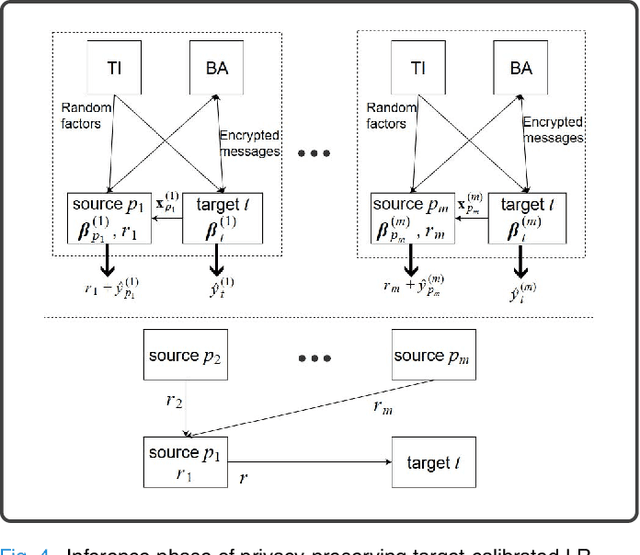
Machine learning (ML) is revolutionizing research and industry. Many ML applications rely on the use of large amounts of personal data for training and inference. Among the most intimate exploited data sources is electroencephalogram (EEG) data, a kind of data that is so rich with information that application developers can easily gain knowledge beyond the professed scope from unprotected EEG signals, including passwords, ATM PINs, and other intimate data. The challenge we address is how to engage in meaningful ML with EEG data while protecting the privacy of users. Hence, we propose cryptographic protocols based on Secure Multiparty Computation (SMC) to perform linear regression over EEG signals from many users in a fully privacy-preserving (PP) fashion, i.e.~such that each individual's EEG signals are not revealed to anyone else. To illustrate the potential of our secure framework, we show how it allows estimating the drowsiness of drivers from their EEG signals as would be possible in the unencrypted case, and at a very reasonable computational cost. Our solution is the first application of commodity-based SMC to EEG data, as well as the largest documented experiment of secret sharing based SMC in general, namely with 15 players involved in all the computations.