 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecure and Privacy-Preserving Vertical Federated Learning
Apr 15, 2026We propose a novel end-to-end privacy-preserving framework, instantiated by three efficient protocols for different deployment scenarios, covering both input and output privacy, for the vertically split scenario in federated learning (FL), where features are split across clients and labels are not shared by all parties. We do so by distributing the role of the aggregator in FL into multiple servers and having them run secure multiparty computation (MPC) protocols to perform model and feature aggregation and apply differential privacy (DP) to the final released model. While a naive solution would have the clients delegating the entirety of training to run in MPC between the servers, our optimized solution, which supports purely global and also global-local models updates with privacy-preserving, drastically reduces the amount of computation and communication performed using multiparty computation. The experimental results also show the effectiveness of our protocols.
Privacy-Preserving Training of Tree Ensembles over Continuous Data
Jun 05, 2021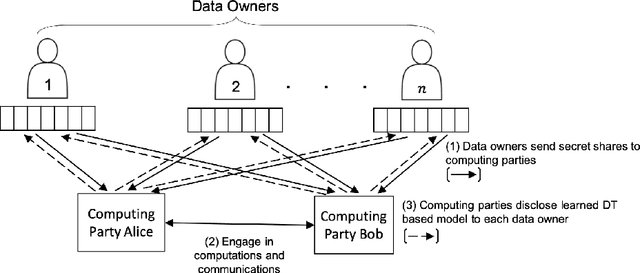
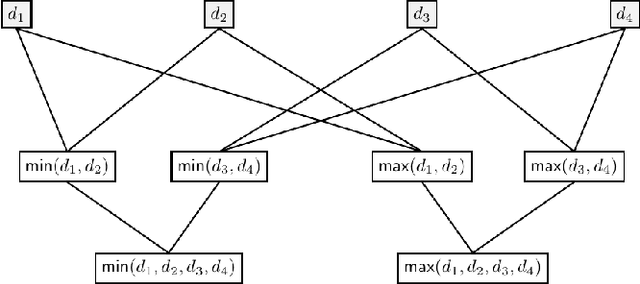
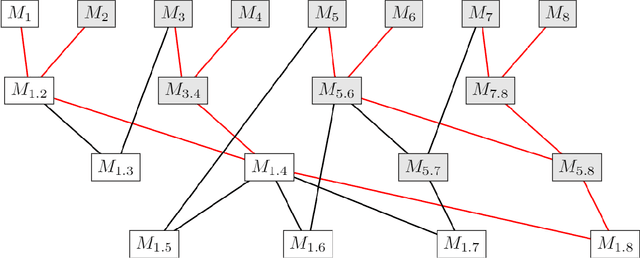
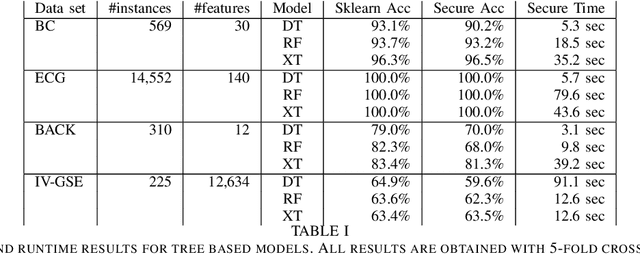
Most existing Secure Multi-Party Computation (MPC) protocols for privacy-preserving training of decision trees over distributed data assume that the features are categorical. In real-life applications, features are often numerical. The standard ``in the clear'' algorithm to grow decision trees on data with continuous values requires sorting of training examples for each feature in the quest for an optimal cut-point in the range of feature values in each node. Sorting is an expensive operation in MPC, hence finding secure protocols that avoid such an expensive step is a relevant problem in privacy-preserving machine learning. In this paper we propose three more efficient alternatives for secure training of decision tree based models on data with continuous features, namely: (1) secure discretization of the data, followed by secure training of a decision tree over the discretized data; (2) secure discretization of the data, followed by secure training of a random forest over the discretized data; and (3) secure training of extremely randomized trees (``extra-trees'') on the original data. Approaches (2) and (3) both involve randomizing feature choices. In addition, in approach (3) cut-points are chosen randomly as well, thereby alleviating the need to sort or to discretize the data up front. We implemented all proposed solutions in the semi-honest setting with additive secret sharing based MPC. In addition to mathematically proving that all proposed approaches are correct and secure, we experimentally evaluated and compared them in terms of classification accuracy and runtime. We privately train tree ensembles over data sets with 1000s of instances or features in a few minutes, with accuracies that are at par with those obtained in the clear. This makes our solution orders of magnitude more efficient than the existing approaches, which are based on oblivious sorting.
Round and Communication Balanced Protocols for Oblivious Evaluation of Finite State Machines
Mar 20, 2021We propose protocols for obliviously evaluating finite-state machines, i.e., the evaluation is shared between the provider of the finite-state machine and the provider of the input string in such a manner that neither party learns the other's input, and the states being visited are hidden from both. For alphabet size $|\Sigma|$, number of states $|Q|$, and input length $n$, previous solutions have either required a number of rounds linear in $n$ or communication $\Omega(n|\Sigma||Q|\log|Q|)$. Our solutions require 2 rounds with communication $O(n(|\Sigma|+|Q|\log|Q|))$. We present two different solutions to this problem, a two-party one and a setting with an untrusted but non-colluding helper.
Fast Privacy-Preserving Text Classification based on Secure Multiparty Computation
Jan 18, 2021

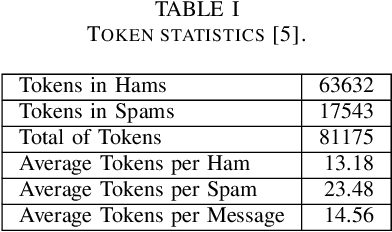
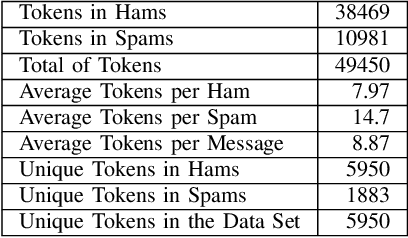
We propose a privacy-preserving Naive Bayes classifier and apply it to the problem of private text classification. In this setting, a party (Alice) holds a text message, while another party (Bob) holds a classifier. At the end of the protocol, Alice will only learn the result of the classifier applied to her text input and Bob learns nothing. Our solution is based on Secure Multiparty Computation (SMC). Our Rust implementation provides a fast and secure solution for the classification of unstructured text. Applying our solution to the case of spam detection (the solution is generic, and can be used in any other scenario in which the Naive Bayes classifier can be employed), we can classify an SMS as spam or ham in less than 340ms in the case where the dictionary size of Bob's model includes all words (n = 5200) and Alice's SMS has at most m = 160 unigrams. In the case with n = 369 and m = 8 (the average of a spam SMS in the database), our solution takes only 21ms.
High Performance Logistic Regression for Privacy-Preserving Genome Analysis
Mar 03, 2020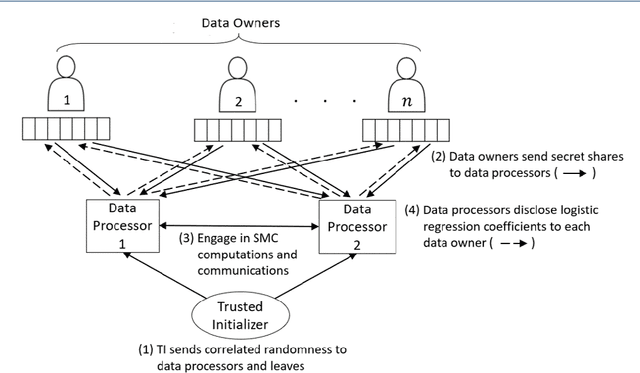
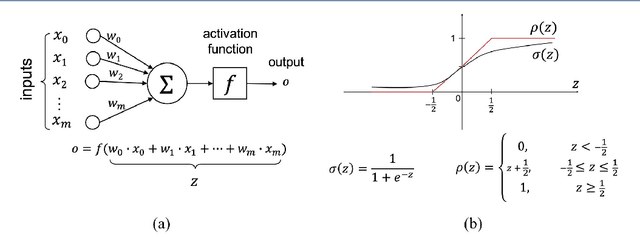
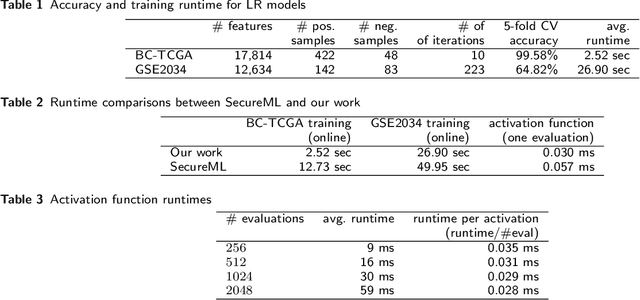
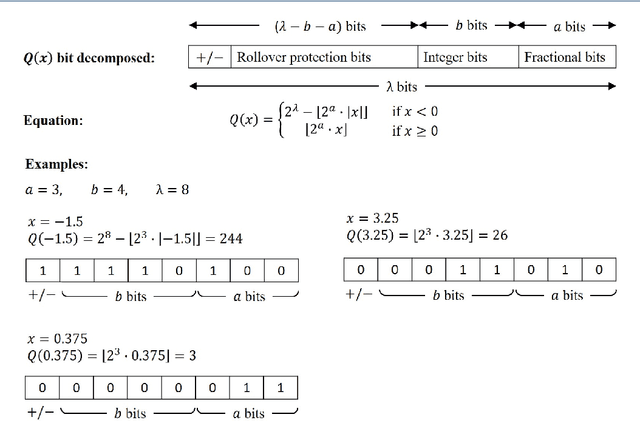
In this paper, we present a secure logistic regression training protocol and its implementation, with a new subprotocol to securely compute the activation function. To the best of our knowledge, we present the fastest existing secure Multi-Party Computation implementation for training logistic regression models on high dimensional genome data distributed across a local area network.
Protecting Privacy of Users in Brain-Computer Interface Applications
Jul 02, 2019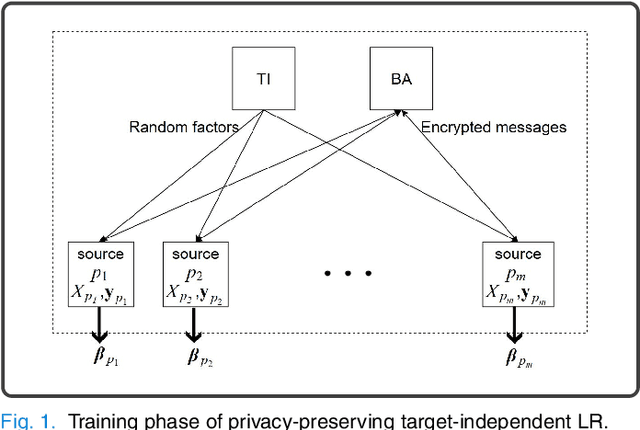
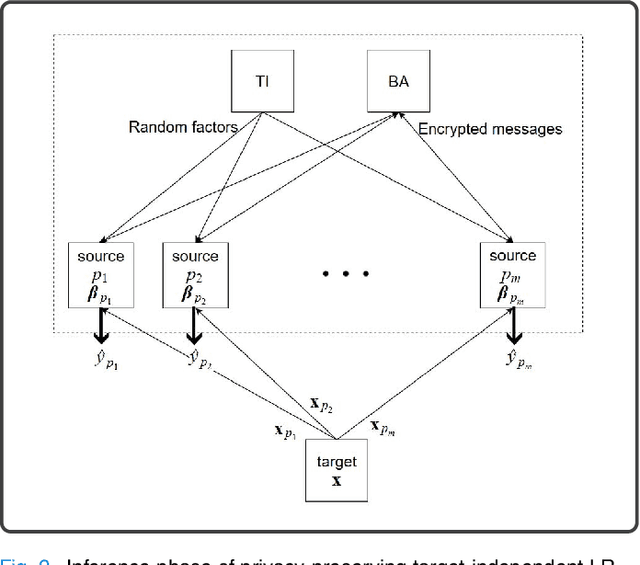
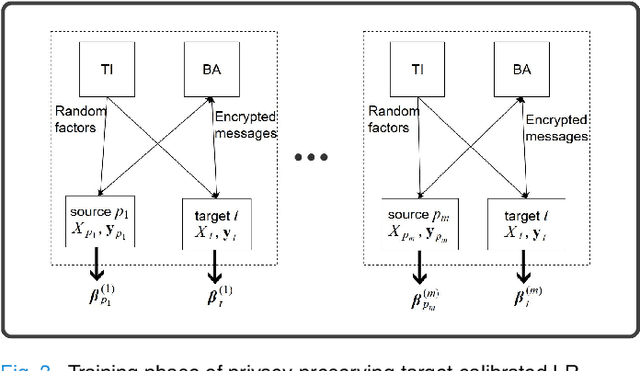
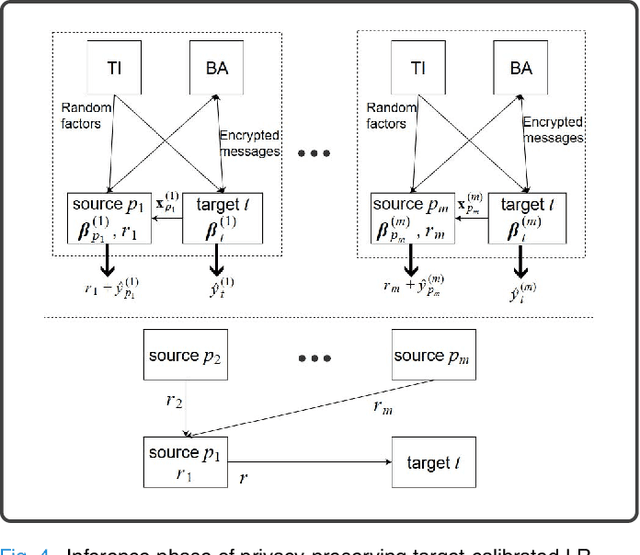
Machine learning (ML) is revolutionizing research and industry. Many ML applications rely on the use of large amounts of personal data for training and inference. Among the most intimate exploited data sources is electroencephalogram (EEG) data, a kind of data that is so rich with information that application developers can easily gain knowledge beyond the professed scope from unprotected EEG signals, including passwords, ATM PINs, and other intimate data. The challenge we address is how to engage in meaningful ML with EEG data while protecting the privacy of users. Hence, we propose cryptographic protocols based on Secure Multiparty Computation (SMC) to perform linear regression over EEG signals from many users in a fully privacy-preserving (PP) fashion, i.e.~such that each individual's EEG signals are not revealed to anyone else. To illustrate the potential of our secure framework, we show how it allows estimating the drowsiness of drivers from their EEG signals as would be possible in the unencrypted case, and at a very reasonable computational cost. Our solution is the first application of commodity-based SMC to EEG data, as well as the largest documented experiment of secret sharing based SMC in general, namely with 15 players involved in all the computations.
Privacy-Preserving Classification of Personal Text Messages with Secure Multi-Party Computation: An Application to Hate-Speech Detection
Jun 05, 2019


Classification of personal text messages has many useful applications in surveillance, e-commerce, and mental health care, to name a few. Giving applications access to personal texts can easily lead to (un)intentional privacy violations. We propose the first privacy-preserving solution for text classification that is provably secure. Our method, which is based on Secure Multiparty Computation (SMC), encompasses both feature extraction from texts, and subsequent classification with logistic regression and tree ensembles. We prove that when using our secure text classification method, the application does not learn anything about the text, and the author of the text does not learn anything about the text classification model used by the application beyond what is given by the classification result itself. We perform end-to-end experiments with an application for detecting hate speech against women and immigrants, demonstrating excellent runtime results without loss of accuracy.
VirtualIdentity: Privacy-Preserving User Profiling
Aug 30, 2018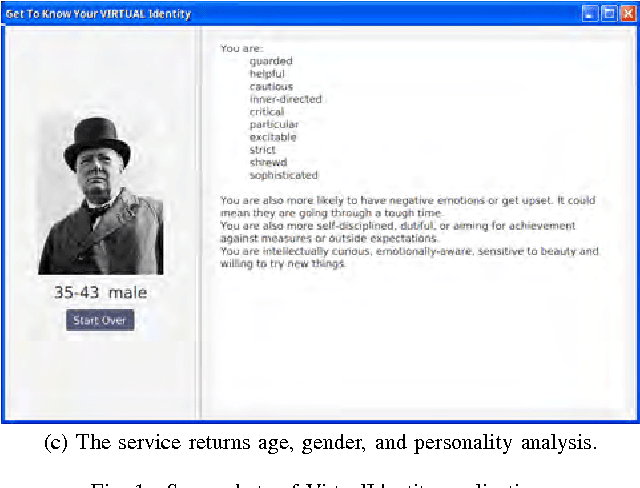
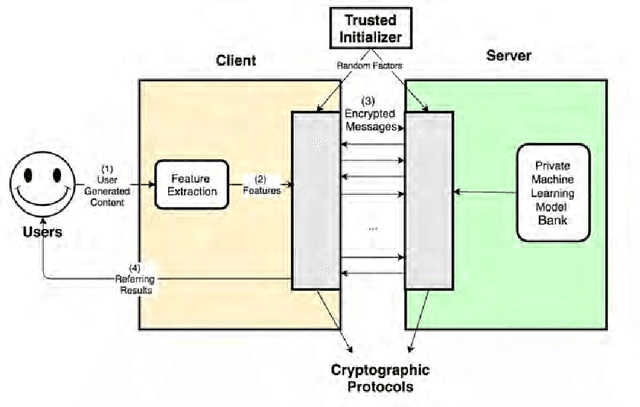
User profiling from user generated content (UGC) is a common practice that supports the business models of many social media companies. Existing systems require that the UGC is fully exposed to the module that constructs the user profiles. In this paper we show that it is possible to build user profiles without ever accessing the user's original data, and without exposing the trained machine learning models for user profiling -- which are the intellectual property of the company -- to the users of the social media site. We present VirtualIdentity, an application that uses secure multi-party cryptographic protocols to detect the age, gender and personality traits of users by classifying their user-generated text and personal pictures with trained support vector machine models in a privacy-preserving manner.