 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy-Preserving Training of Tree Ensembles over Continuous Data
Jun 05, 2021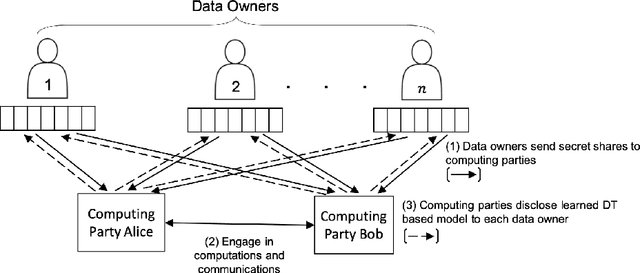
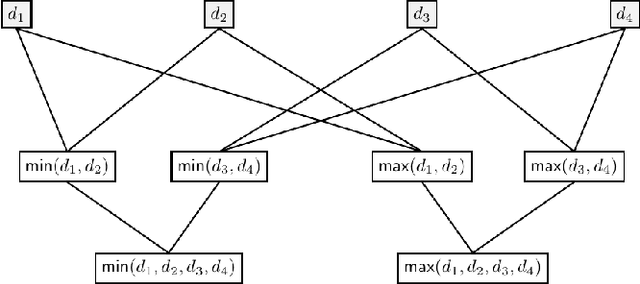
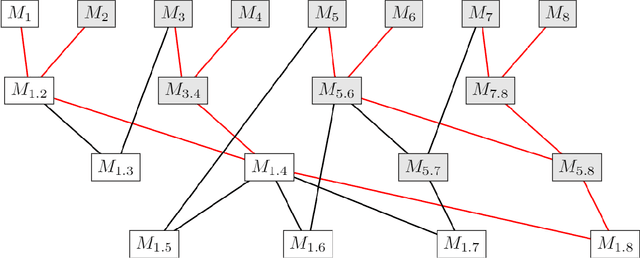
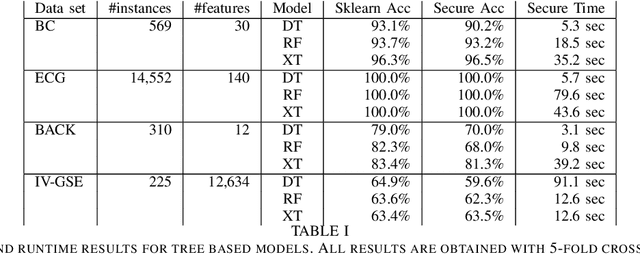
Most existing Secure Multi-Party Computation (MPC) protocols for privacy-preserving training of decision trees over distributed data assume that the features are categorical. In real-life applications, features are often numerical. The standard ``in the clear'' algorithm to grow decision trees on data with continuous values requires sorting of training examples for each feature in the quest for an optimal cut-point in the range of feature values in each node. Sorting is an expensive operation in MPC, hence finding secure protocols that avoid such an expensive step is a relevant problem in privacy-preserving machine learning. In this paper we propose three more efficient alternatives for secure training of decision tree based models on data with continuous features, namely: (1) secure discretization of the data, followed by secure training of a decision tree over the discretized data; (2) secure discretization of the data, followed by secure training of a random forest over the discretized data; and (3) secure training of extremely randomized trees (``extra-trees'') on the original data. Approaches (2) and (3) both involve randomizing feature choices. In addition, in approach (3) cut-points are chosen randomly as well, thereby alleviating the need to sort or to discretize the data up front. We implemented all proposed solutions in the semi-honest setting with additive secret sharing based MPC. In addition to mathematically proving that all proposed approaches are correct and secure, we experimentally evaluated and compared them in terms of classification accuracy and runtime. We privately train tree ensembles over data sets with 1000s of instances or features in a few minutes, with accuracies that are at par with those obtained in the clear. This makes our solution orders of magnitude more efficient than the existing approaches, which are based on oblivious sorting.