 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivFair: a Library for Privacy-Preserving Fairness Auditing
Feb 09, 2022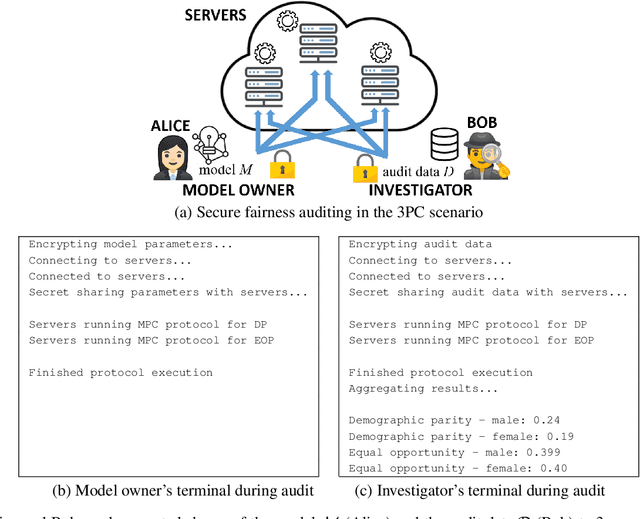

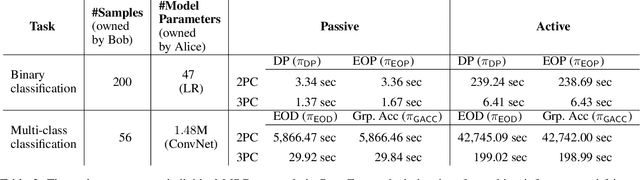
Machine learning (ML) has become prominent in applications that directly affect people's quality of life, including in healthcare, justice, and finance. ML models have been found to exhibit discrimination based on sensitive attributes such as gender, race, or disability. Assessing if an ML model is free of bias remains challenging to date, and by definition has to be done with sensitive user characteristics that are subject of anti-discrimination and data protection law. Existing libraries for fairness auditing of ML models offer no mechanism to protect the privacy of the audit data. We present PrivFair, a library for privacy-preserving fairness audits of ML models. Through the use of Secure Multiparty Computation (MPC), PrivFair protects the confidentiality of the model under audit and the sensitive data used for the audit, hence it supports scenarios in which a proprietary classifier owned by a company is audited using sensitive audit data from an external investigator. We demonstrate the use of PrivFair for group fairness auditing with tabular data or image data, without requiring the investigator to disclose their data to anyone in an unencrypted manner, or the model owner to reveal their model parameters to anyone in plaintext.
Training Differentially Private Models with Secure Multiparty Computation
Feb 05, 2022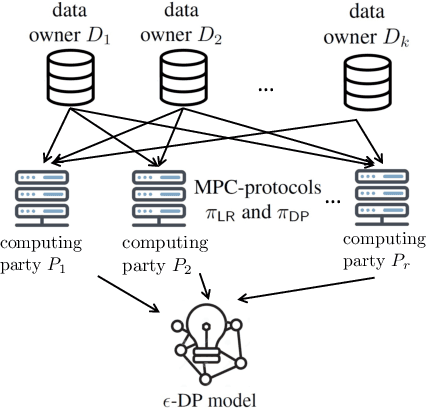

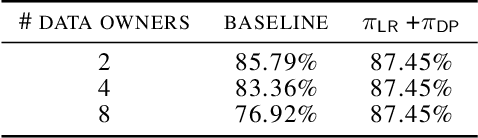

We address the problem of learning a machine learning model from training data that originates at multiple data owners while providing formal privacy guarantees regarding the protection of each owner's data. Existing solutions based on Differential Privacy (DP) achieve this at the cost of a drop in accuracy. Solutions based on Secure Multiparty Computation (MPC) do not incur such accuracy loss but leak information when the trained model is made publicly available. We propose an MPC solution for training DP models. Our solution relies on an MPC protocol for model training, and an MPC protocol for perturbing the trained model coefficients with Laplace noise in a privacy-preserving manner. The resulting MPC+DP approach achieves higher accuracy than a pure DP approach while providing the same formal privacy guarantees. Our work obtained first place in the iDASH2021 Track III competition on confidential computing for secure genome analysis.
Privacy-Preserving Training of Tree Ensembles over Continuous Data
Jun 05, 2021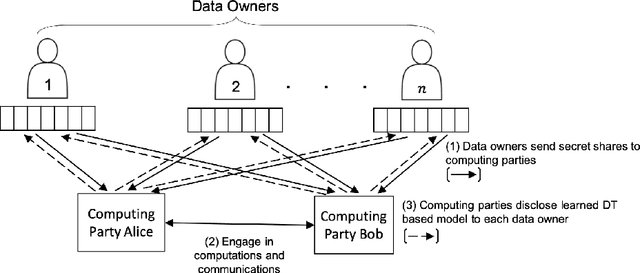
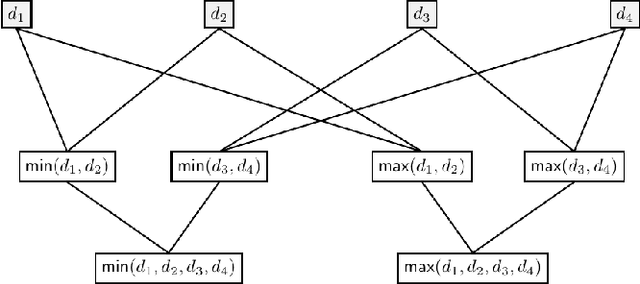
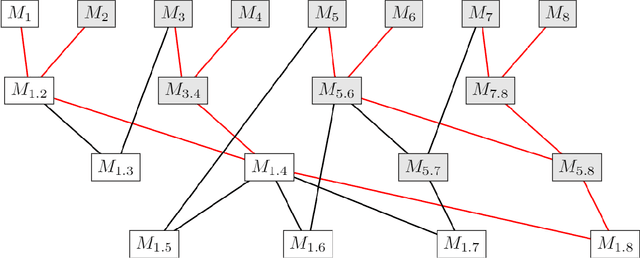
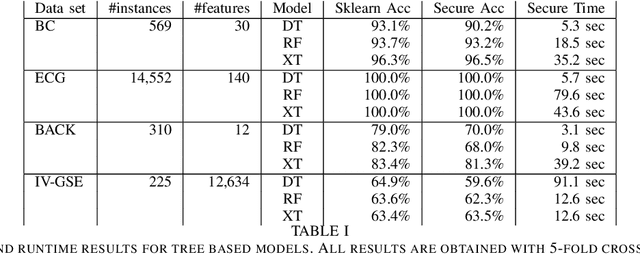
Most existing Secure Multi-Party Computation (MPC) protocols for privacy-preserving training of decision trees over distributed data assume that the features are categorical. In real-life applications, features are often numerical. The standard ``in the clear'' algorithm to grow decision trees on data with continuous values requires sorting of training examples for each feature in the quest for an optimal cut-point in the range of feature values in each node. Sorting is an expensive operation in MPC, hence finding secure protocols that avoid such an expensive step is a relevant problem in privacy-preserving machine learning. In this paper we propose three more efficient alternatives for secure training of decision tree based models on data with continuous features, namely: (1) secure discretization of the data, followed by secure training of a decision tree over the discretized data; (2) secure discretization of the data, followed by secure training of a random forest over the discretized data; and (3) secure training of extremely randomized trees (``extra-trees'') on the original data. Approaches (2) and (3) both involve randomizing feature choices. In addition, in approach (3) cut-points are chosen randomly as well, thereby alleviating the need to sort or to discretize the data up front. We implemented all proposed solutions in the semi-honest setting with additive secret sharing based MPC. In addition to mathematically proving that all proposed approaches are correct and secure, we experimentally evaluated and compared them in terms of classification accuracy and runtime. We privately train tree ensembles over data sets with 1000s of instances or features in a few minutes, with accuracies that are at par with those obtained in the clear. This makes our solution orders of magnitude more efficient than the existing approaches, which are based on oblivious sorting.