 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecure Multiparty Computation for Synthetic Data Generation from Distributed Data
Oct 13, 2022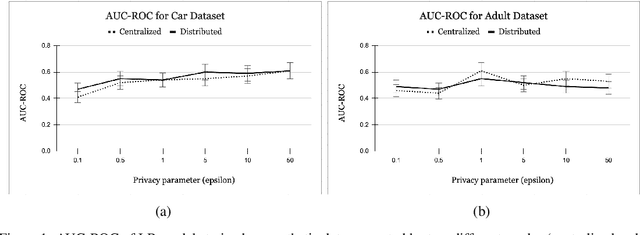
Legal and ethical restrictions on accessing relevant data inhibit data science research in critical domains such as health, finance, and education. Synthetic data generation algorithms with privacy guarantees are emerging as a paradigm to break this data logjam. Existing approaches, however, assume that the data holders supply their raw data to a trusted curator, who uses it as fuel for synthetic data generation. This severely limits the applicability, as much of the valuable data in the world is locked up in silos, controlled by entities who cannot show their data to each other or a central aggregator without raising privacy concerns. To overcome this roadblock, we propose the first solution in which data holders only share encrypted data for differentially private synthetic data generation. Data holders send shares to servers who perform Secure Multiparty Computation (MPC) computations while the original data stays encrypted. We instantiate this idea in an MPC protocol for the Multiplicative Weights with Exponential Mechanism (MWEM) algorithm to generate synthetic data based on real data originating from many data holders without reliance on a single point of failure.
PrivFairFL: Privacy-Preserving Group Fairness in Federated Learning
May 23, 2022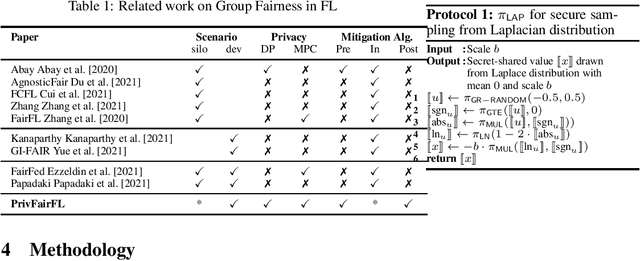
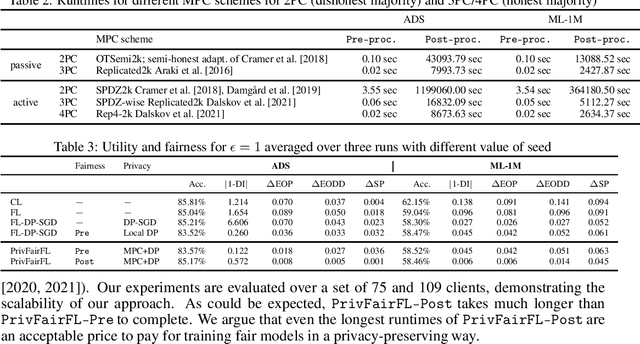
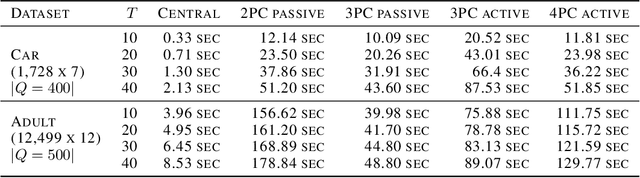
Group fairness ensures that the outcome of machine learning (ML) based decision making systems are not biased towards a certain group of people defined by a sensitive attribute such as gender or ethnicity. Achieving group fairness in Federated Learning (FL) is challenging because mitigating bias inherently requires using the sensitive attribute values of all clients, while FL is aimed precisely at protecting privacy by not giving access to the clients' data. As we show in this paper, this conflict between fairness and privacy in FL can be resolved by combining FL with Secure Multiparty Computation (MPC) and Differential Privacy (DP). In doing so, we propose a method for training group-fair ML models in cross-device FL under complete and formal privacy guarantees, without requiring the clients to disclose their sensitive attribute values.
Training Differentially Private Models with Secure Multiparty Computation
Feb 05, 2022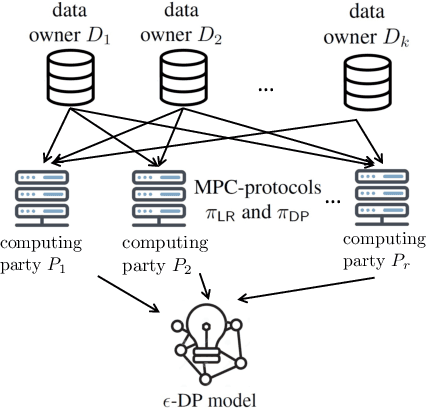

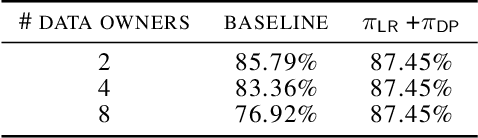

We address the problem of learning a machine learning model from training data that originates at multiple data owners while providing formal privacy guarantees regarding the protection of each owner's data. Existing solutions based on Differential Privacy (DP) achieve this at the cost of a drop in accuracy. Solutions based on Secure Multiparty Computation (MPC) do not incur such accuracy loss but leak information when the trained model is made publicly available. We propose an MPC solution for training DP models. Our solution relies on an MPC protocol for model training, and an MPC protocol for perturbing the trained model coefficients with Laplace noise in a privacy-preserving manner. The resulting MPC+DP approach achieves higher accuracy than a pure DP approach while providing the same formal privacy guarantees. Our work obtained first place in the iDASH2021 Track III competition on confidential computing for secure genome analysis.
Inline Detection of DGA Domains Using Side Information
Mar 12, 2020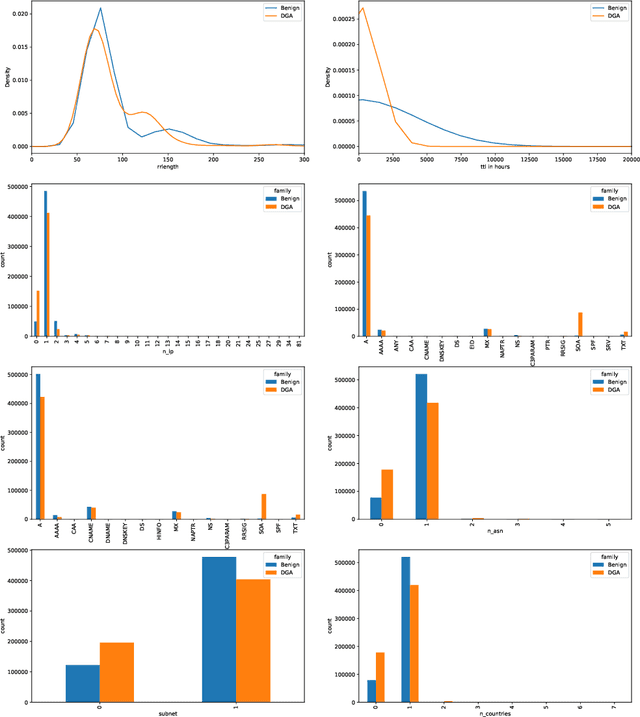

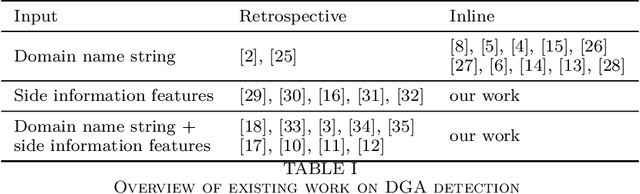

Malware applications typically use a command and control (C&C) server to manage bots to perform malicious activities. Domain Generation Algorithms (DGAs) are popular methods for generating pseudo-random domain names that can be used to establish a communication between an infected bot and the C&C server. In recent years, machine learning based systems have been widely used to detect DGAs. There are several well known state-of-the-art classifiers in the literature that can detect DGA domain names in real-time applications with high predictive performance. However, these DGA classifiers are highly vulnerable to adversarial attacks in which adversaries purposely craft domain names to evade DGA detection classifiers. In our work, we focus on hardening DGA classifiers against adversarial attacks. To this end, we train and evaluate state-of-the-art deep learning and random forest (RF) classifiers for DGA detection using side information that is harder for adversaries to manipulate than the domain name itself. Additionally, the side information features are selected such that they are easily obtainable in practice to perform inline DGA detection. The performance and robustness of these models is assessed by exposing them to one day of real-traffic data as well as domains generated by adversarial attack algorithms. We found that the DGA classifiers that rely on both the domain name and side information have high performance and are more robust against adversaries.
CharBot: A Simple and Effective Method for Evading DGA Classifiers
May 30, 2019
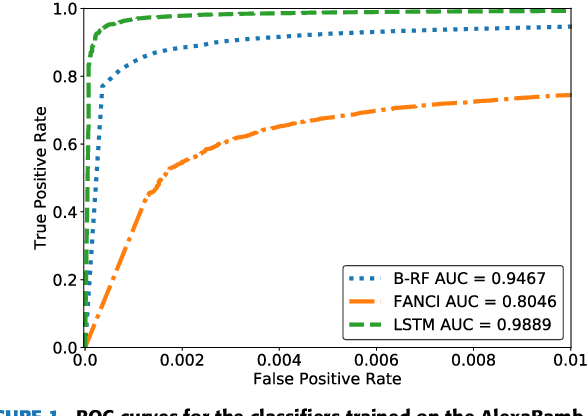

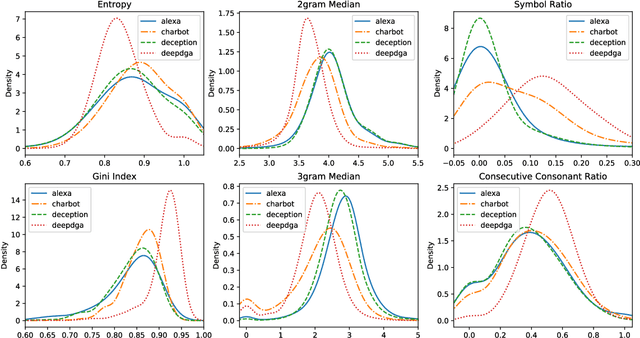
Domain generation algorithms (DGAs) are commonly leveraged by malware to create lists of domain names which can be used for command and control (C&C) purposes. Approaches based on machine learning have recently been developed to automatically detect generated domain names in real-time. In this work, we present a novel DGA called CharBot which is capable of producing large numbers of unregistered domain names that are not detected by state-of-the-art classifiers for real-time detection of DGAs, including the recently published methods FANCI (a random forest based on human-engineered features) and LSTM.MI (a deep learning approach). CharBot is very simple, effective and requires no knowledge of the targeted DGA classifiers. We show that retraining the classifiers on CharBot samples is not a viable defense strategy. We believe these findings show that DGA classifiers are inherently vulnerable to adversarial attacks if they rely only on the domain name string to make a decision. Designing a robust DGA classifier may, therefore, necessitate the use of additional information besides the domain name alone. To the best of our knowledge, CharBot is the simplest and most efficient black-box adversarial attack against DGA classifiers proposed to date.