 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoK: Reconstruction Attacks on Synthetic Tabular Data (Insights from Winning the NIST CRC)
Jun 06, 2026Synthetic data is increasingly promoted as a privacy-preserving substitute for releasing sensitive tabular records, yet its central adversarial threat ("reconstruction", the recovery of an individual's hidden attribute values from a synthetic release and a handful of known quasi-identifiers) has been studied only in scattered, hard-to-compare settings. We present the first systematization of reconstruction (equivalently, attribute inference) attacks on de-identified and synthetic tabular data. We contribute a taxonomy that organizes attacks by the structure they exploit; the most systematic empirical evaluation to date, pitting fourteen attacks against nine synthetic data generation (SDG) methods across five benchmark datasets; and a set of new attacks that fill gaps in the taxonomy, one of which (CoBP-RA) is the strongest attack we measure. Crucially, we introduce a methodology for interpreting what attack success means: a memorization test that distinguishes reconstruction of the population distribution from memorization of training records, and a reduction that places reconstruction and membership inference on a single comparable scale. Our findings: the choice of SDG method governs risk far more than the choice of attack; differential privacy protects mainly at small budgets ($\varepsilon\lesssim1$), above which protection plateaus, bounded by the synthesizer's capacity rather than its noise; de-identification methods are the most exposed; and most reconstruction reflects distributional structure rather than memorization, concentrating individual risk on atypical records. The attacks and infrastructure are externally validated by our first-place finish among all red teams in the 2025 \textit{National Institute of Standards and Technology} (NIST) Collaborative Research Cycle.
FHAIM: Fully Homomorphic AIM For Private Synthetic Data Generation
Feb 05, 2026Data is the lifeblood of AI, yet much of the most valuable data remains locked in silos due to privacy and regulations. As a result, AI remains heavily underutilized in many of the most important domains, including healthcare, education, and finance. Synthetic data generation (SDG), i.e. the generation of artificial data with a synthesizer trained on real data, offers an appealing solution to make data available while mitigating privacy concerns, however existing SDG-as-a-service workflow require data holders to trust providers with access to private data.We propose FHAIM, the first fully homomorphic encryption (FHE) framework for training a marginal-based synthetic data generator on encrypted tabular data. FHAIM adapts the widely used AIM algorithm to the FHE setting using novel FHE protocols, ensuring that the private data remains encrypted throughout and is released only with differential privacy guarantees. Our empirical analysis show that FHAIM preserves the performance of AIM while maintaining feasible runtimes.
End to End Collaborative Synthetic Data Generation
Dec 04, 2024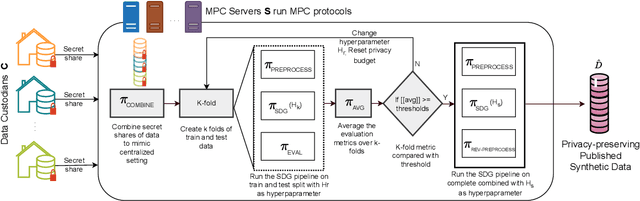


The success of AI is based on the availability of data to train models. While in some cases a single data custodian may have sufficient data to enable AI, often multiple custodians need to collaborate to reach a cumulative size required for meaningful AI research. The latter is, for example, often the case for rare diseases, with each clinical site having data for only a small number of patients. Recent algorithms for federated synthetic data generation are an important step towards collaborative, privacy-preserving data sharing. Existing techniques, however, focus exclusively on synthesizer training, assuming that the training data is already preprocessed and that the desired synthetic data can be delivered in one shot, without any hyperparameter tuning. In this paper, we propose an end-to-end collaborative framework for publishing of synthetic data that accounts for privacy-preserving preprocessing as well as evaluation. We instantiate this framework with Secure Multiparty Computation (MPC) protocols and evaluate it in a use case for privacy-preserving publishing of synthetic genomic data for leukemia.
Privacy Vulnerabilities in Marginals-based Synthetic Data
Oct 07, 2024When acting as a privacy-enhancing technology, synthetic data generation (SDG) aims to maintain a resemblance to the real data while excluding personally-identifiable information. Many SDG algorithms provide robust differential privacy (DP) guarantees to this end. However, we show that the strongest class of SDG algorithms--those that preserve \textit{marginal probabilities}, or similar statistics, from the underlying data--leak information about individuals that can be recovered more efficiently than previously understood. We demonstrate this by presenting a novel membership inference attack, MAMA-MIA, and evaluate it against three seminal DP SDG algorithms: MST, PrivBayes, and Private-GSD. MAMA-MIA leverages knowledge of which SDG algorithm was used, allowing it to learn information about the hidden data more accurately, and orders-of-magnitude faster, than other leading attacks. We use MAMA-MIA to lend insight into existing SDG vulnerabilities. Our approach went on to win the first SNAKE (SaNitization Algorithm under attacK ... $\varepsilon$) competition.
Privacy-Preserving Algorithmic Recourse
Nov 23, 2023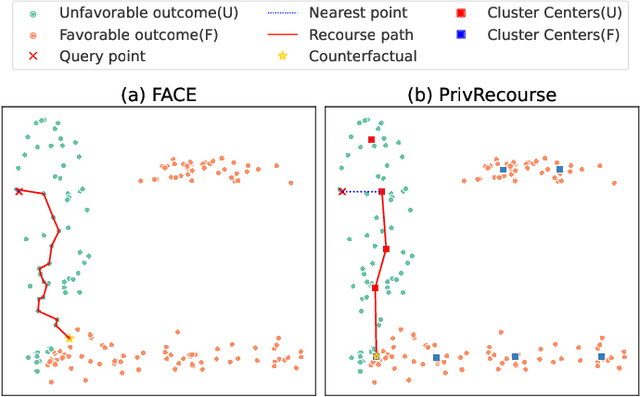

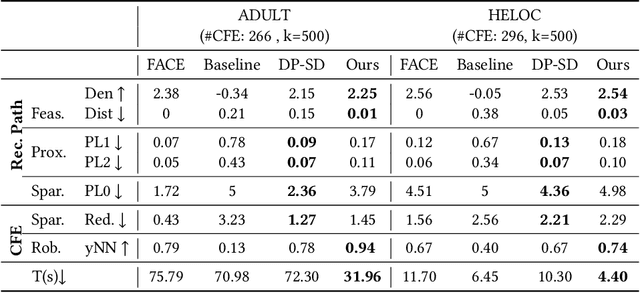
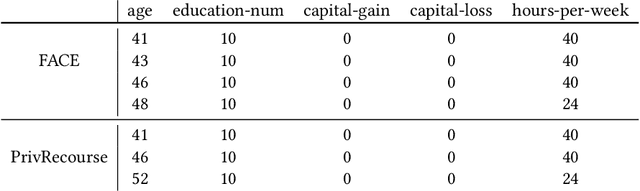
When individuals are subject to adverse outcomes from machine learning models, providing a recourse path to help achieve a positive outcome is desirable. Recent work has shown that counterfactual explanations - which can be used as a means of single-step recourse - are vulnerable to privacy issues, putting an individuals' privacy at risk. Providing a sequential multi-step path for recourse can amplify this risk. Furthermore, simply adding noise to recourse paths found from existing methods can impact the realism and actionability of the path for an end-user. In this work, we address privacy issues when generating realistic recourse paths based on instance-based counterfactual explanations, and provide PrivRecourse: an end-to-end privacy preserving pipeline that can provide realistic recourse paths. PrivRecourse uses differentially private (DP) clustering to represent non-overlapping subsets of the private dataset. These DP cluster centers are then used to generate recourse paths by forming a graph with cluster centers as the nodes, so that we can generate realistic - feasible and actionable - recourse paths. We empirically evaluate our approach on finance datasets and compare it to simply adding noise to data instances, and to using DP synthetic data, to generate the graph. We observe that PrivRecourse can provide paths that are private and realistic.
Privacy-Preserving Fair Item Ranking
Mar 06, 2023Users worldwide access massive amounts of curated data in the form of rankings on a daily basis. The societal impact of this ease of access has been studied and work has been done to propose and enforce various notions of fairness in rankings. Current computational methods for fair item ranking rely on disclosing user data to a centralized server, which gives rise to privacy concerns for the users. This work is the first to advance research at the conjunction of producer (item) fairness and consumer (user) privacy in rankings by exploring the incorporation of privacy-preserving techniques; specifically, differential privacy and secure multi-party computation. Our work extends the equity of amortized attention ranking mechanism to be privacy-preserving, and we evaluate its effects with respect to privacy, fairness, and ranking quality. Our results using real-world datasets show that we are able to effectively preserve the privacy of users and mitigate unfairness of items without making additional sacrifices to the quality of rankings in comparison to the ranking mechanism in the clear.
Secure Multiparty Computation for Synthetic Data Generation from Distributed Data
Oct 13, 2022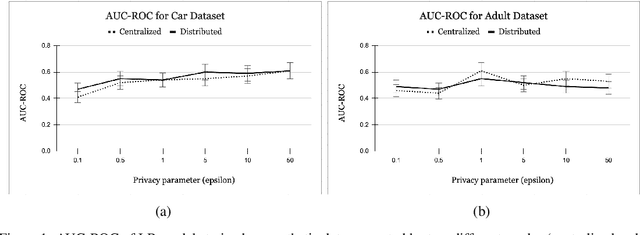
Legal and ethical restrictions on accessing relevant data inhibit data science research in critical domains such as health, finance, and education. Synthetic data generation algorithms with privacy guarantees are emerging as a paradigm to break this data logjam. Existing approaches, however, assume that the data holders supply their raw data to a trusted curator, who uses it as fuel for synthetic data generation. This severely limits the applicability, as much of the valuable data in the world is locked up in silos, controlled by entities who cannot show their data to each other or a central aggregator without raising privacy concerns. To overcome this roadblock, we propose the first solution in which data holders only share encrypted data for differentially private synthetic data generation. Data holders send shares to servers who perform Secure Multiparty Computation (MPC) computations while the original data stays encrypted. We instantiate this idea in an MPC protocol for the Multiplicative Weights with Exponential Mechanism (MWEM) algorithm to generate synthetic data based on real data originating from many data holders without reliance on a single point of failure.
PrivFairFL: Privacy-Preserving Group Fairness in Federated Learning
May 23, 2022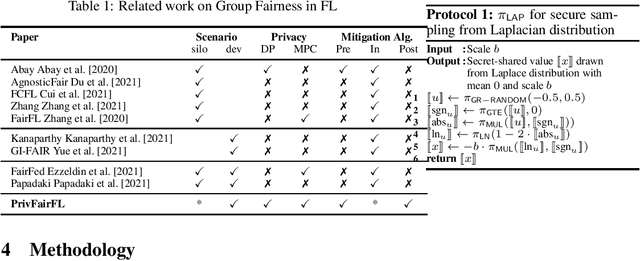
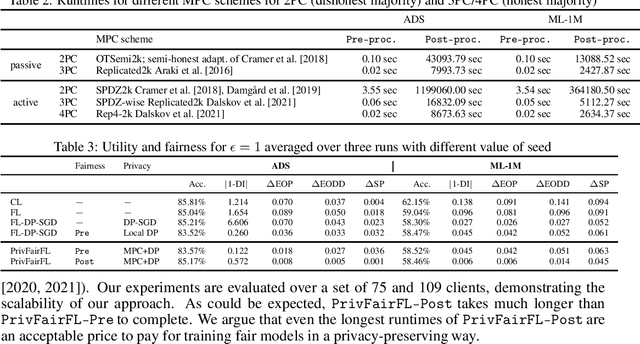
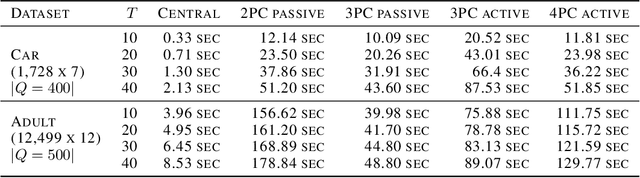
Group fairness ensures that the outcome of machine learning (ML) based decision making systems are not biased towards a certain group of people defined by a sensitive attribute such as gender or ethnicity. Achieving group fairness in Federated Learning (FL) is challenging because mitigating bias inherently requires using the sensitive attribute values of all clients, while FL is aimed precisely at protecting privacy by not giving access to the clients' data. As we show in this paper, this conflict between fairness and privacy in FL can be resolved by combining FL with Secure Multiparty Computation (MPC) and Differential Privacy (DP). In doing so, we propose a method for training group-fair ML models in cross-device FL under complete and formal privacy guarantees, without requiring the clients to disclose their sensitive attribute values.
PrivFair: a Library for Privacy-Preserving Fairness Auditing
Feb 09, 2022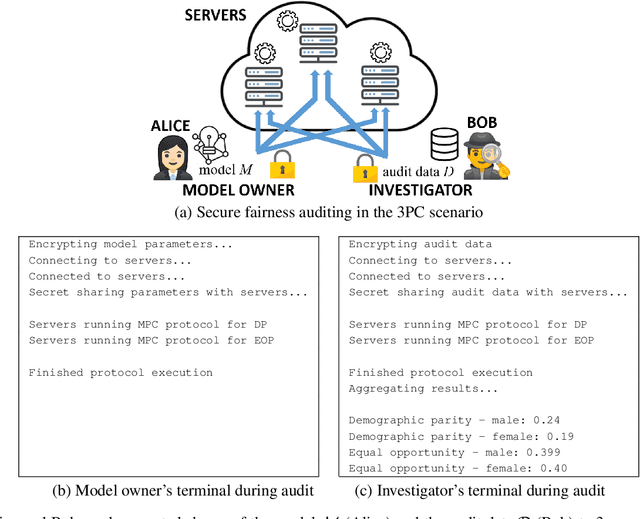

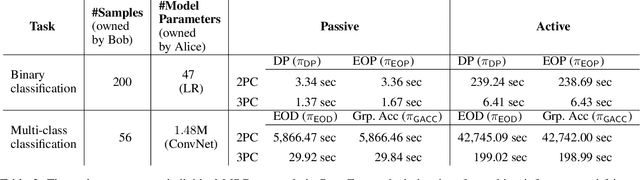
Machine learning (ML) has become prominent in applications that directly affect people's quality of life, including in healthcare, justice, and finance. ML models have been found to exhibit discrimination based on sensitive attributes such as gender, race, or disability. Assessing if an ML model is free of bias remains challenging to date, and by definition has to be done with sensitive user characteristics that are subject of anti-discrimination and data protection law. Existing libraries for fairness auditing of ML models offer no mechanism to protect the privacy of the audit data. We present PrivFair, a library for privacy-preserving fairness audits of ML models. Through the use of Secure Multiparty Computation (MPC), PrivFair protects the confidentiality of the model under audit and the sensitive data used for the audit, hence it supports scenarios in which a proprietary classifier owned by a company is audited using sensitive audit data from an external investigator. We demonstrate the use of PrivFair for group fairness auditing with tabular data or image data, without requiring the investigator to disclose their data to anyone in an unencrypted manner, or the model owner to reveal their model parameters to anyone in plaintext.
Training Differentially Private Models with Secure Multiparty Computation
Feb 05, 2022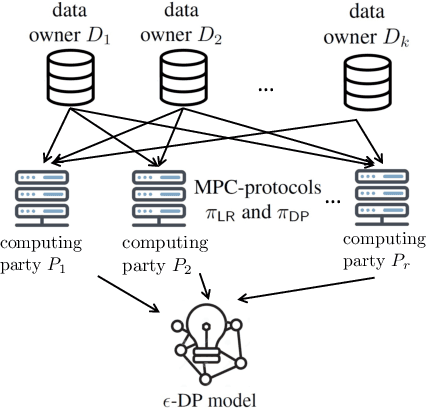

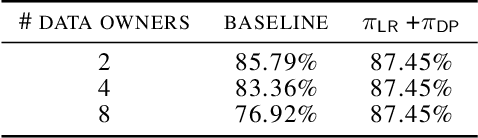

We address the problem of learning a machine learning model from training data that originates at multiple data owners while providing formal privacy guarantees regarding the protection of each owner's data. Existing solutions based on Differential Privacy (DP) achieve this at the cost of a drop in accuracy. Solutions based on Secure Multiparty Computation (MPC) do not incur such accuracy loss but leak information when the trained model is made publicly available. We propose an MPC solution for training DP models. Our solution relies on an MPC protocol for model training, and an MPC protocol for perturbing the trained model coefficients with Laplace noise in a privacy-preserving manner. The resulting MPC+DP approach achieves higher accuracy than a pure DP approach while providing the same formal privacy guarantees. Our work obtained first place in the iDASH2021 Track III competition on confidential computing for secure genome analysis.