 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupling Identity from Utility: Privacy-by-Design Frameworks for Financial Ecosystems
Apr 16, 2026Financial institutions face tension between maximizing data utility and mitigating the re-identification risks inherent in traditional anonymization methods. This paper explores Differentially Private (DP) synthetic data as a robust "Privacy by Design" framework to resolve this conflict, ensuring output privacy while satisfying stringent regulatory obligations. We examine two distinct generative paradigms: Direct Tabular Synthesis, which reconstructs high-fidelity joint distributions from raw data, and DP-Seeded Agent-Based Modeling (ABM), which uses DP-protected aggregates to parameterize complex, stateful simulations. While tabular synthesis excels at reflecting static historical correlations for QA testing and business analytics, the DP-Seeded ABM offers a forward-looking "counterfactual laboratory" capable of modeling dynamic market behaviors and black swan events. By decoupling individual identities from data utility, these methodologies eliminate traditional data-clearing bottlenecks, enabling seamless cross-institutional research and compliant decision-making in an evolving regulatory landscape.
Assessment of Differentially Private Synthetic Data for Utility and Fairness in End-to-End Machine Learning Pipelines for Tabular Data
Oct 30, 2023



Differentially private (DP) synthetic data sets are a solution for sharing data while preserving the privacy of individual data providers. Understanding the effects of utilizing DP synthetic data in end-to-end machine learning pipelines impacts areas such as health care and humanitarian action, where data is scarce and regulated by restrictive privacy laws. In this work, we investigate the extent to which synthetic data can replace real, tabular data in machine learning pipelines and identify the most effective synthetic data generation techniques for training and evaluating machine learning models. We investigate the impacts of differentially private synthetic data on downstream classification tasks from the point of view of utility as well as fairness. Our analysis is comprehensive and includes representatives of the two main types of synthetic data generation algorithms: marginal-based and GAN-based. To the best of our knowledge, our work is the first that: (i) proposes a training and evaluation framework that does not assume that real data is available for testing the utility and fairness of machine learning models trained on synthetic data; (ii) presents the most extensive analysis of synthetic data set generation algorithms in terms of utility and fairness when used for training machine learning models; and (iii) encompasses several different definitions of fairness. Our findings demonstrate that marginal-based synthetic data generators surpass GAN-based ones regarding model training utility for tabular data. Indeed, we show that models trained using data generated by marginal-based algorithms can exhibit similar utility to models trained using real data. Our analysis also reveals that the marginal-based synthetic data generator MWEM PGM can train models that simultaneously achieve utility and fairness characteristics close to those obtained by models trained with real data.
Secure Multiparty Computation for Synthetic Data Generation from Distributed Data
Oct 13, 2022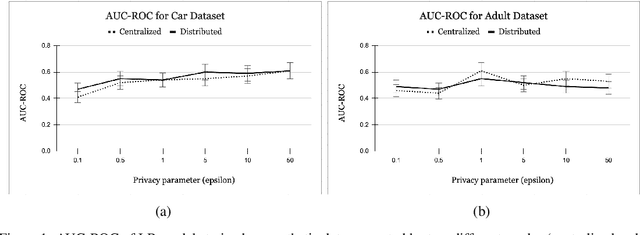
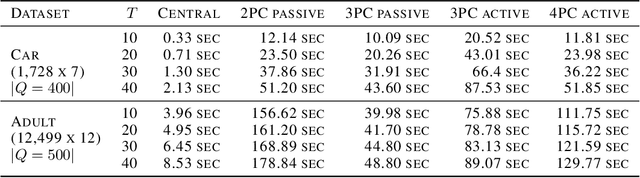
Legal and ethical restrictions on accessing relevant data inhibit data science research in critical domains such as health, finance, and education. Synthetic data generation algorithms with privacy guarantees are emerging as a paradigm to break this data logjam. Existing approaches, however, assume that the data holders supply their raw data to a trusted curator, who uses it as fuel for synthetic data generation. This severely limits the applicability, as much of the valuable data in the world is locked up in silos, controlled by entities who cannot show their data to each other or a central aggregator without raising privacy concerns. To overcome this roadblock, we propose the first solution in which data holders only share encrypted data for differentially private synthetic data generation. Data holders send shares to servers who perform Secure Multiparty Computation (MPC) computations while the original data stays encrypted. We instantiate this idea in an MPC protocol for the Multiplicative Weights with Exponential Mechanism (MWEM) algorithm to generate synthetic data based on real data originating from many data holders without reliance on a single point of failure.
An Analysis of the Deployment of Models Trained on Private Tabular Synthetic Data: Unexpected Surprises
Jun 15, 2021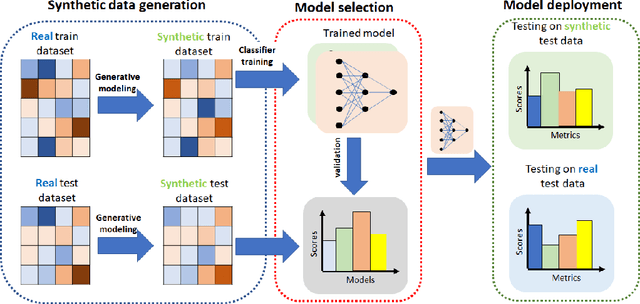
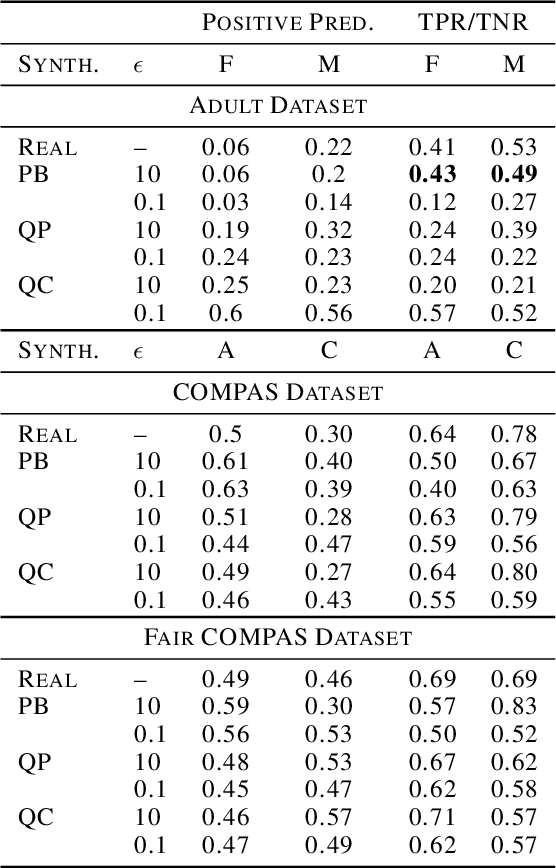
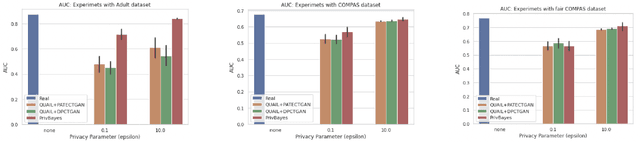
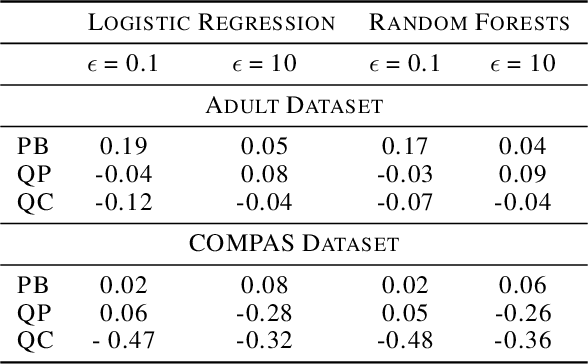
Diferentially private (DP) synthetic datasets are a powerful approach for training machine learning models while respecting the privacy of individual data providers. The effect of DP on the fairness of the resulting trained models is not yet well understood. In this contribution, we systematically study the effects of differentially private synthetic data generation on classification. We analyze disparities in model utility and bias caused by the synthetic dataset, measured through algorithmic fairness metrics. Our first set of results show that although there seems to be a clear negative correlation between privacy and utility (the more private, the less accurate) across all data synthesizers we evaluated, more privacy does not necessarily imply more bias. Additionally, we assess the effects of utilizing synthetic datasets for model training and model evaluation. We show that results obtained on synthetic data can misestimate the actual model performance when it is deployed on real data. We hence advocate on the need for defining proper testing protocols in scenarios where differentially private synthetic datasets are utilized for model training and evaluation.
Metadata-Based Detection of Child Sexual Abuse Material
Oct 05, 2020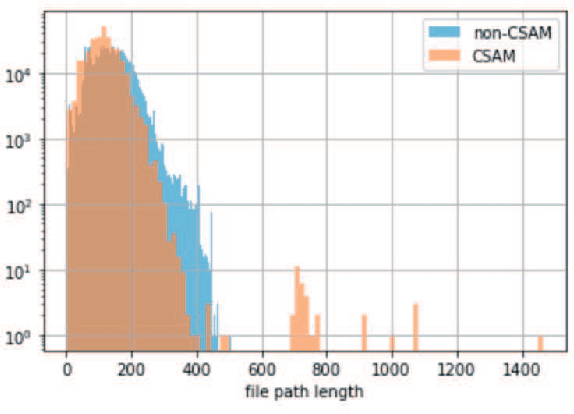
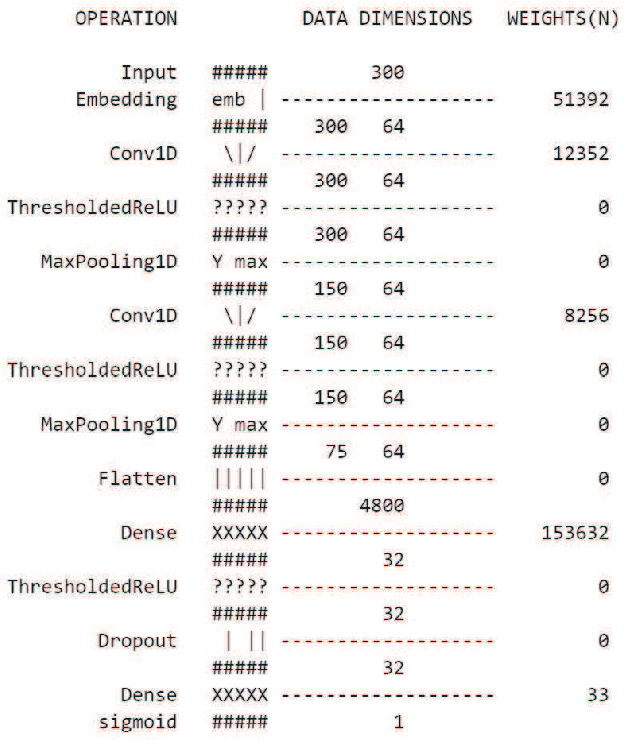

In the last decade, the scale of creation and distribution of child sexual abuse medias (CSAM) has exponentially increased. Technologies that aid law enforcement agencies worldwide to identify such crimes rapidly can potentially result in the mitigation of child victimization, and the apprehending of offenders. Machine learning presents the potential to help law enforcement rapidly identify such material, and even block such content from being distributed digitally. However, collecting and storing CSAM files to train machine learning models has many ethical and legal constraints, creating a barrier to the development of accurate computer vision-based models. With such restrictions in place, the development of accurate machine learning classifiers for CSAM identification based on file metadata becomes crucial. In this work, we propose a system for CSAM identification on file storage systems based solely on metadata - file paths. Our aim is to provide a tool that is material type agnostic (image, video, PDF), and can potentially scans thousands of file storage systems in a short time. Our approach uses convolutional neural networks, and achieves an accuracy of 97% and recall of 94%. Additionally, we address the potential problem of offenders trying to evade detection by this model by evaluating the robustness of our model against adversarial modifications in the file paths.