 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBYOL: Bring Your Own Language Into LLMs
Jan 15, 2026Large Language Models (LLMs) exhibit strong multilingual capabilities, yet remain fundamentally constrained by the severe imbalance in global language resources. While over 7,000 languages are spoken worldwide, only a small subset (fewer than 100) has sufficient digital presence to meaningfully influence modern LLM training. This disparity leads to systematic underperformance, cultural misalignment, and limited accessibility for speakers of low-resource and extreme-low-resource languages. To address this gap, we introduce Bring Your Own Language (BYOL), a unified framework for scalable, language-aware LLM development tailored to each language's digital footprint. BYOL begins with a language resource classification that maps languages into four tiers (Extreme-Low, Low, Mid, High) using curated web-scale corpora, and uses this classification to select the appropriate integration pathway. For low-resource languages, we propose a full-stack data refinement and expansion pipeline that combines corpus cleaning, synthetic text generation, continual pretraining, and supervised finetuning. Applied to Chichewa and Maori, this pipeline yields language-specific LLMs that achieve approximately 12 percent average improvement over strong multilingual baselines across 12 benchmarks, while preserving English and multilingual capabilities via weight-space model merging. For extreme-low-resource languages, we introduce a translation-mediated inclusion pathway, and show on Inuktitut that a tailored machine translation system improves over a commercial baseline by 4 BLEU, enabling high-accuracy LLM access when direct language modeling is infeasible. Finally, we release human-translated versions of the Global MMLU-Lite benchmark in Chichewa, Maori, and Inuktitut, and make our codebase and models publicly available at https://github.com/microsoft/byol .
Multimodal Foundation Models for Zero-shot Animal Species Recognition in Camera Trap Images
Nov 02, 2023



Due to deteriorating environmental conditions and increasing human activity, conservation efforts directed towards wildlife is crucial. Motion-activated camera traps constitute an efficient tool for tracking and monitoring wildlife populations across the globe. Supervised learning techniques have been successfully deployed to analyze such imagery, however training such techniques requires annotations from experts. Reducing the reliance on costly labelled data therefore has immense potential in developing large-scale wildlife tracking solutions with markedly less human labor. In this work we propose WildMatch, a novel zero-shot species classification framework that leverages multimodal foundation models. In particular, we instruction tune vision-language models to generate detailed visual descriptions of camera trap images using similar terminology to experts. Then, we match the generated caption to an external knowledge base of descriptions in order to determine the species in a zero-shot manner. We investigate techniques to build instruction tuning datasets for detailed animal description generation and propose a novel knowledge augmentation technique to enhance caption quality. We demonstrate the performance of WildMatch on a new camera trap dataset collected in the Magdalena Medio region of Colombia.
Assessment of Differentially Private Synthetic Data for Utility and Fairness in End-to-End Machine Learning Pipelines for Tabular Data
Oct 30, 2023



Differentially private (DP) synthetic data sets are a solution for sharing data while preserving the privacy of individual data providers. Understanding the effects of utilizing DP synthetic data in end-to-end machine learning pipelines impacts areas such as health care and humanitarian action, where data is scarce and regulated by restrictive privacy laws. In this work, we investigate the extent to which synthetic data can replace real, tabular data in machine learning pipelines and identify the most effective synthetic data generation techniques for training and evaluating machine learning models. We investigate the impacts of differentially private synthetic data on downstream classification tasks from the point of view of utility as well as fairness. Our analysis is comprehensive and includes representatives of the two main types of synthetic data generation algorithms: marginal-based and GAN-based. To the best of our knowledge, our work is the first that: (i) proposes a training and evaluation framework that does not assume that real data is available for testing the utility and fairness of machine learning models trained on synthetic data; (ii) presents the most extensive analysis of synthetic data set generation algorithms in terms of utility and fairness when used for training machine learning models; and (iii) encompasses several different definitions of fairness. Our findings demonstrate that marginal-based synthetic data generators surpass GAN-based ones regarding model training utility for tabular data. Indeed, we show that models trained using data generated by marginal-based algorithms can exhibit similar utility to models trained using real data. Our analysis also reveals that the marginal-based synthetic data generator MWEM PGM can train models that simultaneously achieve utility and fairness characteristics close to those obtained by models trained with real data.
Poverty rate prediction using multi-modal survey and earth observation data
Jul 21, 2023



This work presents an approach for combining household demographic and living standards survey questions with features derived from satellite imagery to predict the poverty rate of a region. Our approach utilizes visual features obtained from a single-step featurization method applied to freely available 10m/px Sentinel-2 surface reflectance satellite imagery. These visual features are combined with ten survey questions in a proxy means test (PMT) to estimate whether a household is below the poverty line. We show that the inclusion of visual features reduces the mean error in poverty rate estimates from 4.09% to 3.88% over a nationally representative out-of-sample test set. In addition to including satellite imagery features in proxy means tests, we propose an approach for selecting a subset of survey questions that are complementary to the visual features extracted from satellite imagery. Specifically, we design a survey variable selection approach guided by the full survey and image features and use the approach to determine the most relevant set of small survey questions to include in a PMT. We validate the choice of small survey questions in a downstream task of predicting the poverty rate using the small set of questions. This approach results in the best performance -- errors in poverty rate decrease from 4.09% to 3.71%. We show that extracted visual features encode geographic and urbanization differences between regions.
Dwelling Type Classification for Disaster Risk Assessment Using Satellite Imagery
Nov 16, 2022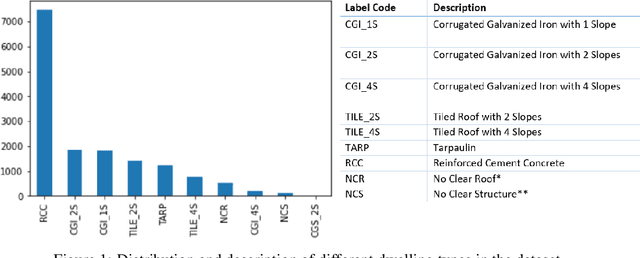
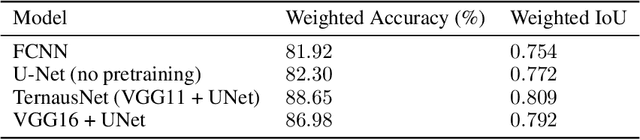

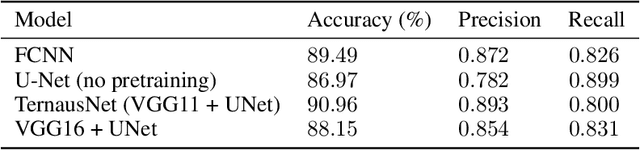
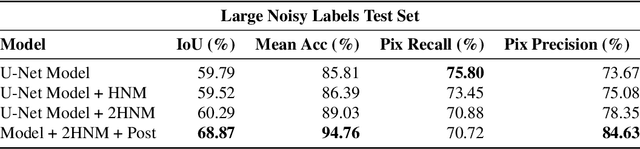
Vulnerability and risk assessment of neighborhoods is essential for effective disaster preparedness. Existing traditional systems, due to dependency on time-consuming and cost-intensive field surveying, do not provide a scalable way to decipher warnings and assess the precise extent of the risk at a hyper-local level. In this work, machine learning was used to automate the process of identifying dwellings and their type to build a potentially more effective disaster vulnerability assessment system. First, satellite imageries of low-income settlements and vulnerable areas in India were used to identify 7 different dwelling types. Specifically, we formulated the dwelling type classification as a semantic segmentation task and trained a U-net based neural network model, namely TernausNet, with the data we collected. Then a risk score assessment model was employed, using the determined dwelling type along with an inundation model of the regions. The entire pipeline was deployed to multiple locations prior to natural hazards in India in 2020. Post hoc ground-truth data from those regions was collected to validate the efficacy of this model which showed promising performance. This work can aid disaster response organizations and communities at risk by providing household-level risk information that can inform preemptive actions.
BankNote-Net: Open dataset for assistive universal currency recognition
Apr 07, 2022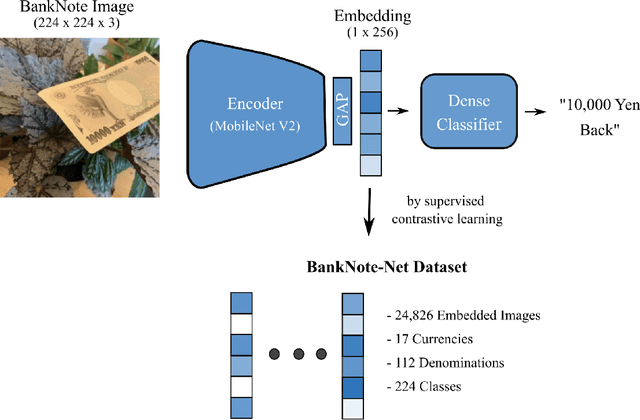

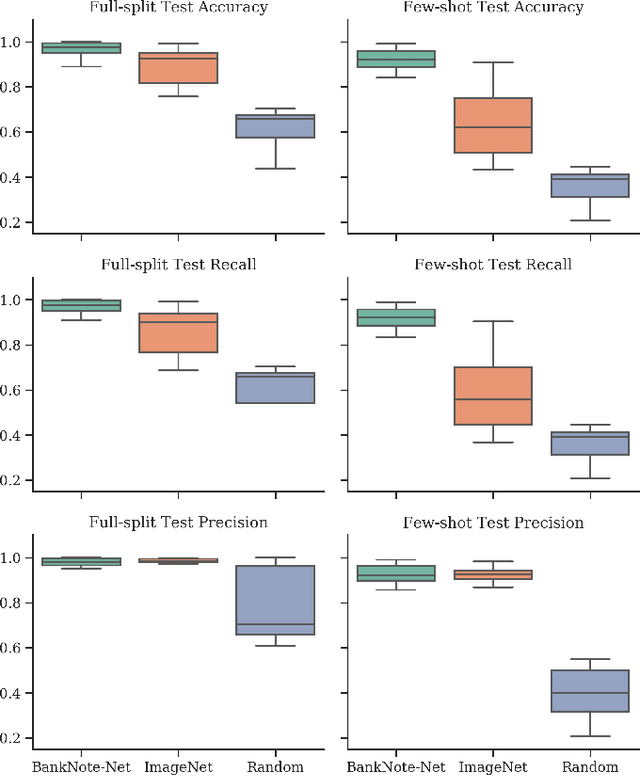
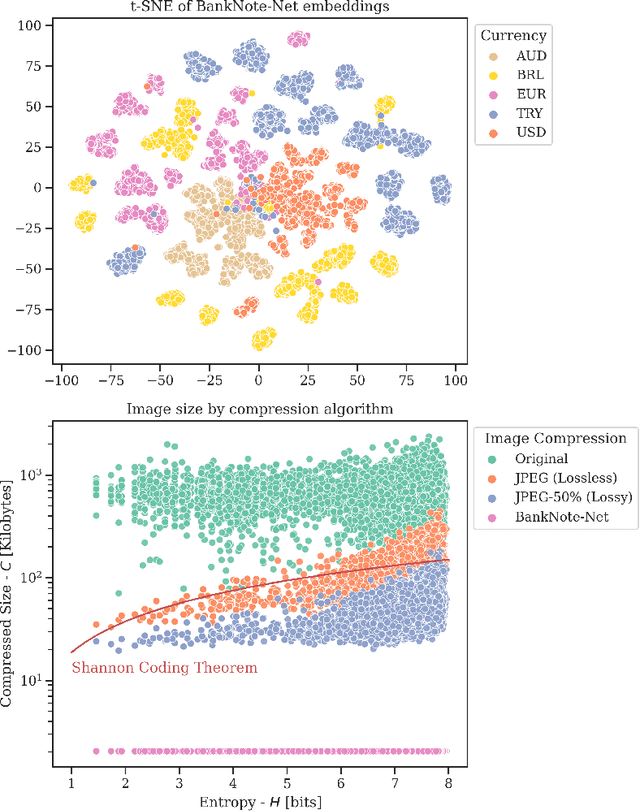
Millions of people around the world have low or no vision. Assistive software applications have been developed for a variety of day-to-day tasks, including optical character recognition, scene identification, person recognition, and currency recognition. This last task, the recognition of banknotes from different denominations, has been addressed by the use of computer vision models for image recognition. However, the datasets and models available for this task are limited, both in terms of dataset size and in variety of currencies covered. In this work, we collect a total of 24,826 images of banknotes in variety of assistive settings, spanning 17 currencies and 112 denominations. Using supervised contrastive learning, we develop a machine learning model for universal currency recognition. This model learns compliant embeddings of banknote images in a variety of contexts, which can be shared publicly (as a compressed vector representation), and can be used to train and test specialized downstream models for any currency, including those not covered by our dataset or for which only a few real images per denomination are available (few-shot learning). We deploy a variation of this model for public use in the last version of the Seeing AI app developed by Microsoft. We share our encoder model and the embeddings as an open dataset in our BankNote-Net repository.
An Artificial Intelligence Dataset for Solar Energy Locations in India
Jan 31, 2022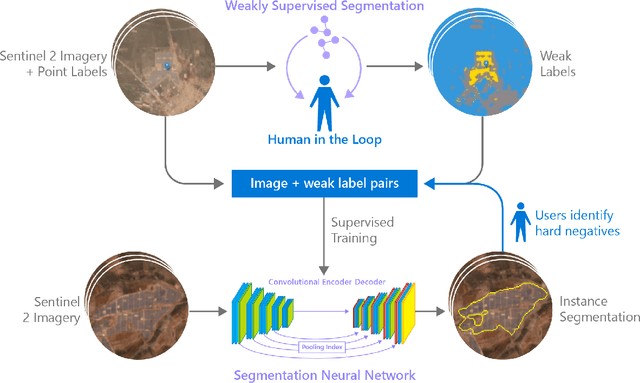


Rapid development of renewable energy sources, particularly solar photovoltaics, is critical to mitigate climate change. As a result, India has set ambitious goals to install 300 gigawatts of solar energy capacity by 2030. Given the large footprint projected to meet these renewable energy targets the potential for land use conflicts over environmental and social values is high. To expedite development of solar energy, land use planners will need access to up-to-date and accurate geo-spatial information of PV infrastructure. The majority of recent studies use either predictions of resource suitability or databases that are either developed thru crowdsourcing that often have significant sampling biases or have time lags between when projects are permitted and when location data becomes available. Here, we address this shortcoming by developing a spatially explicit machine learning model to map utility-scale solar projects across India. Using these outputs, we provide a cumulative measure of the solar footprint across India and quantified the degree of land modification associated with land cover types that may cause conflicts. Our analysis indicates that over 74\% of solar development In India was built on landcover types that have natural ecosystem preservation, and agricultural values. Thus, with a mean accuracy of 92\% this method permits the identification of the factors driving land suitability for solar projects and will be of widespread interest for studies seeking to assess trade-offs associated with the global decarbonization of green-energy systems. In the same way, our model increases the feasibility of remote sensing and long-term monitoring of renewable energy deployment targets.
Interpretable and Explainable Machine Learning for Materials Science and Chemistry
Nov 03, 2021
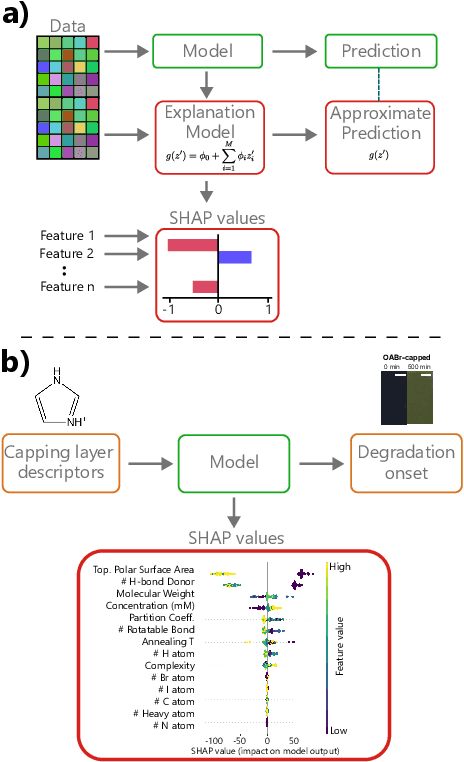
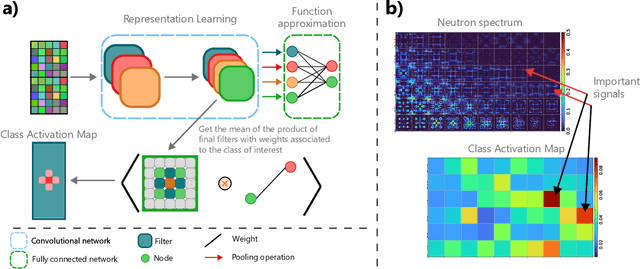
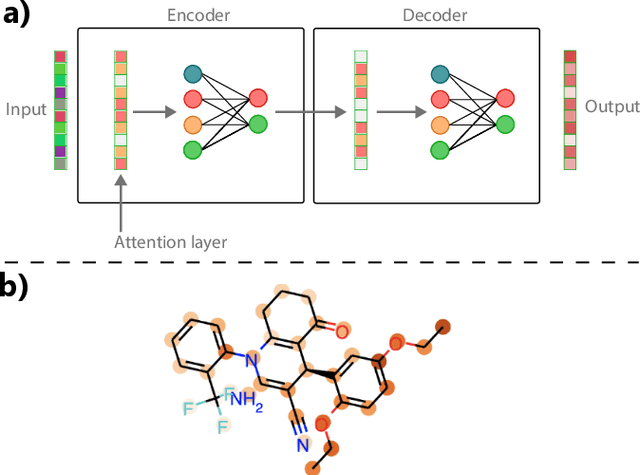
While the uptake of data-driven approaches for materials science and chemistry is at an exciting, early stage, to realise the true potential of machine learning models for successful scientific discovery, they must have qualities beyond purely predictive power. The predictions and inner workings of models should provide a certain degree of explainability by human experts, permitting the identification of potential model issues or limitations, building trust on model predictions and unveiling unexpected correlations that may lead to scientific insights. In this work, we summarize applications of interpretability and explainability techniques for materials science and chemistry and discuss how these techniques can improve the outcome of scientific studies. We discuss various challenges for interpretable machine learning in materials science and, more broadly, in scientific settings. In particular, we emphasize the risks of inferring causation or reaching generalization by purely interpreting machine learning models and the need of uncertainty estimates for model explanations. Finally, we showcase a number of exciting developments in other fields that could benefit interpretability in material science and chemistry problems.
Retinal Microvasculature as Biomarker for Diabetes and Cardiovascular Diseases
Jul 28, 2021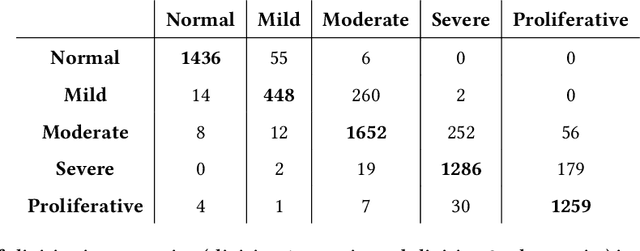
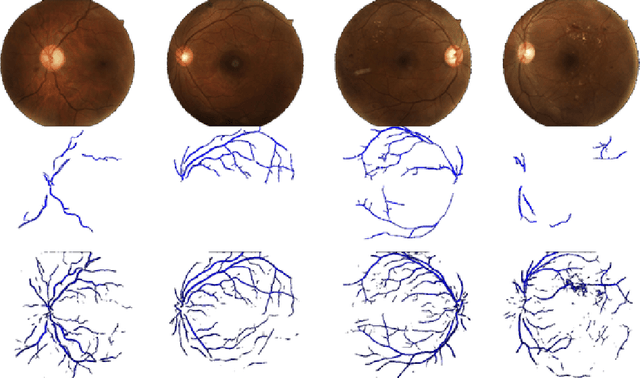
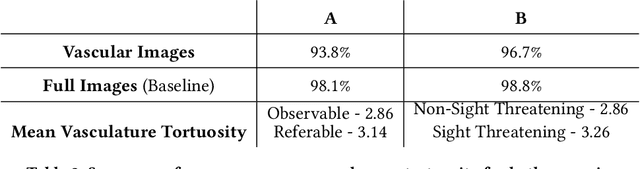
Purpose: To demonstrate that retinal microvasculature per se is a reliable biomarker for Diabetic Retinopathy (DR) and, by extension, cardiovascular diseases. Methods: Deep Learning Convolutional Neural Networks (CNN) applied to color fundus images for semantic segmentation of the blood vessels and severity classification on both vascular and full images. Vessel reconstruction through harmonic descriptors is also used as a smoothing and de-noising tool. The mathematical background of the theory is also outlined. Results: For diabetic patients, at least 93.8% of DR No-Refer vs. Refer classification can be related to vasculature defects. As for the Non-Sight Threatening vs. Sight Threatening case, the ratio is as high as 96.7%. Conclusion: In the case of DR, most of the disease biomarkers are related topologically to the vasculature. Translational Relevance: Experiments conducted on eye blood vasculature reconstruction as a biomarker shows a strong correlation between vasculature shape and later stages of DR.
An Analysis of the Deployment of Models Trained on Private Tabular Synthetic Data: Unexpected Surprises
Jun 15, 2021
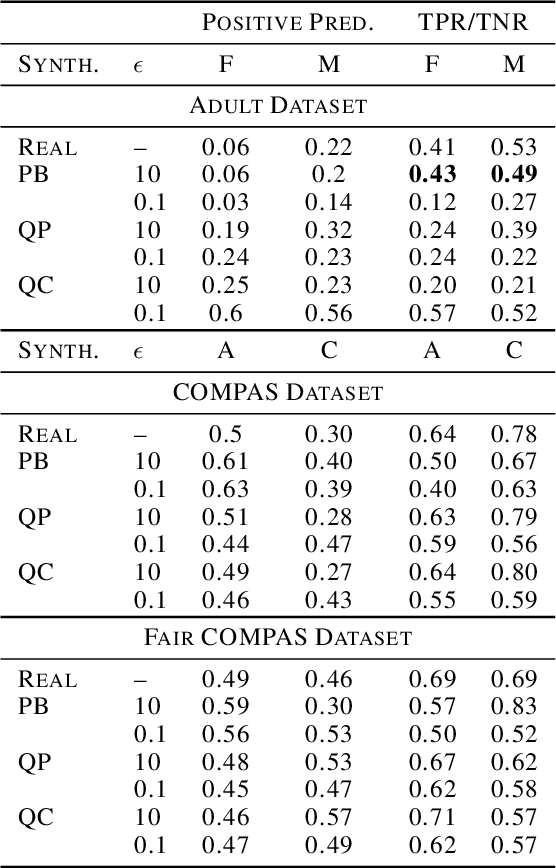
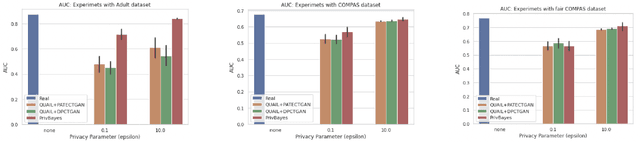
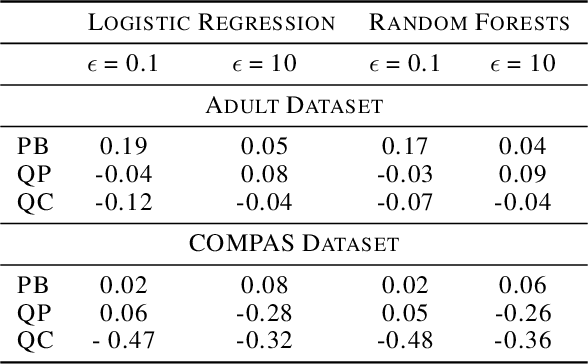
Diferentially private (DP) synthetic datasets are a powerful approach for training machine learning models while respecting the privacy of individual data providers. The effect of DP on the fairness of the resulting trained models is not yet well understood. In this contribution, we systematically study the effects of differentially private synthetic data generation on classification. We analyze disparities in model utility and bias caused by the synthetic dataset, measured through algorithmic fairness metrics. Our first set of results show that although there seems to be a clear negative correlation between privacy and utility (the more private, the less accurate) across all data synthesizers we evaluated, more privacy does not necessarily imply more bias. Additionally, we assess the effects of utilizing synthetic datasets for model training and model evaluation. We show that results obtained on synthetic data can misestimate the actual model performance when it is deployed on real data. We hence advocate on the need for defining proper testing protocols in scenarios where differentially private synthetic datasets are utilized for model training and evaluation.