 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthesizing Proton-Density Fat Fraction and $R_2^*$ from 2-point Dixon MRI with Generative Machine Learning
Oct 15, 2024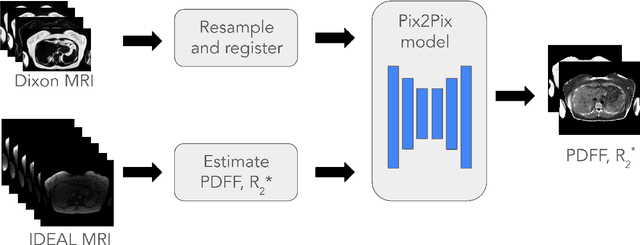



Magnetic Resonance Imaging (MRI) is the gold standard for measuring fat and iron content non-invasively in the body via measures known as Proton Density Fat Fraction (PDFF) and $R_2^*$, respectively. However, conventional PDFF and $R_2^*$ quantification methods operate on MR images voxel-wise and require at least three measurements to estimate three quantities: water, fat, and $R_2^*$. Alternatively, the two-point Dixon MRI protocol is widely used and fast because it acquires only two measurements; however, these cannot be used to estimate three quantities voxel-wise. Leveraging the fact that neighboring voxels have similar values, we propose using a generative machine learning approach to learn PDFF and $R_2^*$ from Dixon MRI. We use paired Dixon-IDEAL data from UK Biobank in the liver and a Pix2Pix conditional GAN to demonstrate the first large-scale $R_2^*$ imputation from two-point Dixon MRIs. Using our proposed approach, we synthesize PDFF and $R_2^*$ maps that show significantly greater correlation with ground-truth than conventional voxel-wise baselines.
Assessment of Differentially Private Synthetic Data for Utility and Fairness in End-to-End Machine Learning Pipelines for Tabular Data
Oct 30, 2023



Differentially private (DP) synthetic data sets are a solution for sharing data while preserving the privacy of individual data providers. Understanding the effects of utilizing DP synthetic data in end-to-end machine learning pipelines impacts areas such as health care and humanitarian action, where data is scarce and regulated by restrictive privacy laws. In this work, we investigate the extent to which synthetic data can replace real, tabular data in machine learning pipelines and identify the most effective synthetic data generation techniques for training and evaluating machine learning models. We investigate the impacts of differentially private synthetic data on downstream classification tasks from the point of view of utility as well as fairness. Our analysis is comprehensive and includes representatives of the two main types of synthetic data generation algorithms: marginal-based and GAN-based. To the best of our knowledge, our work is the first that: (i) proposes a training and evaluation framework that does not assume that real data is available for testing the utility and fairness of machine learning models trained on synthetic data; (ii) presents the most extensive analysis of synthetic data set generation algorithms in terms of utility and fairness when used for training machine learning models; and (iii) encompasses several different definitions of fairness. Our findings demonstrate that marginal-based synthetic data generators surpass GAN-based ones regarding model training utility for tabular data. Indeed, we show that models trained using data generated by marginal-based algorithms can exhibit similar utility to models trained using real data. Our analysis also reveals that the marginal-based synthetic data generator MWEM PGM can train models that simultaneously achieve utility and fairness characteristics close to those obtained by models trained with real data.
A Mean Field Approach to Empirical Bayes Estimation in High-dimensional Linear Regression
Sep 28, 2023We study empirical Bayes estimation in high-dimensional linear regression. To facilitate computationally efficient estimation of the underlying prior, we adopt a variational empirical Bayes approach, introduced originally in Carbonetto and Stephens (2012) and Kim et al. (2022). We establish asymptotic consistency of the nonparametric maximum likelihood estimator (NPMLE) and its (computable) naive mean field variational surrogate under mild assumptions on the design and the prior. Assuming, in addition, that the naive mean field approximation has a dominant optimizer, we develop a computationally efficient approximation to the oracle posterior distribution, and establish its accuracy under the 1-Wasserstein metric. This enables computationally feasible Bayesian inference; e.g., construction of posterior credible intervals with an average coverage guarantee, Bayes optimal estimation for the regression coefficients, estimation of the proportion of non-nulls, etc. Our analysis covers both deterministic and random designs, and accommodates correlations among the features. To the best of our knowledge, this provides the first rigorous nonparametric empirical Bayes method in a high-dimensional regression setting without sparsity.
An Analysis of the Deployment of Models Trained on Private Tabular Synthetic Data: Unexpected Surprises
Jun 15, 2021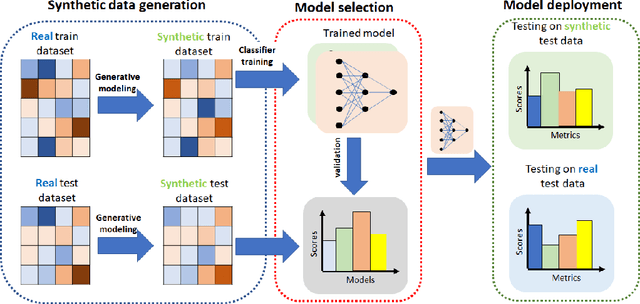
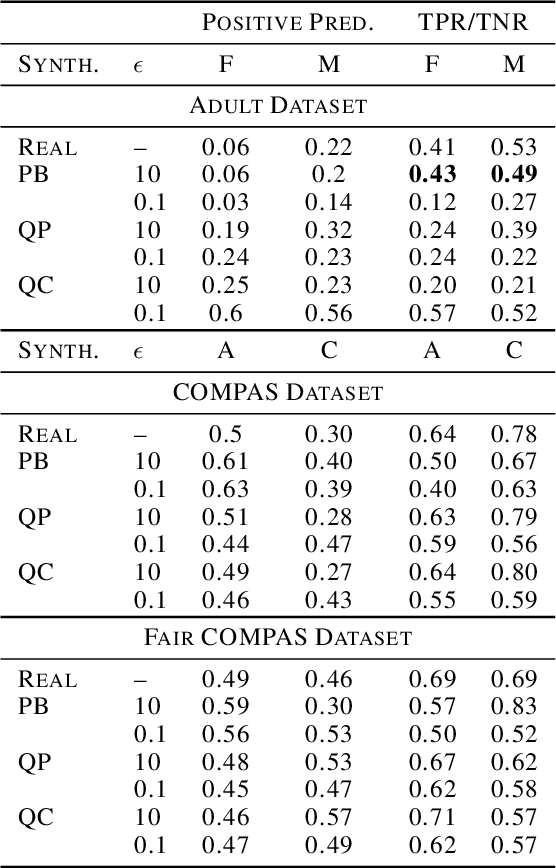
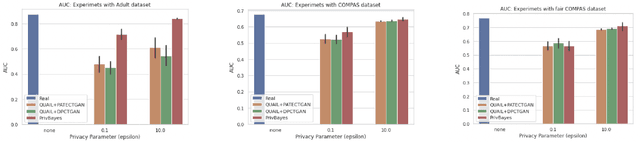
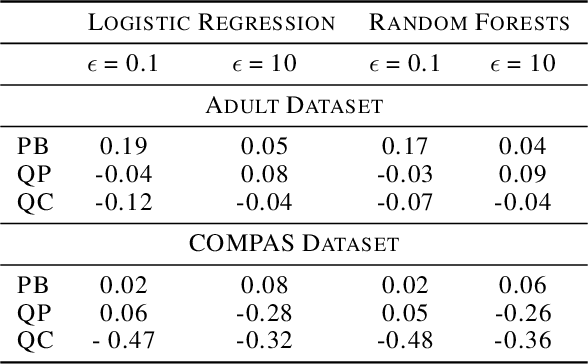
Diferentially private (DP) synthetic datasets are a powerful approach for training machine learning models while respecting the privacy of individual data providers. The effect of DP on the fairness of the resulting trained models is not yet well understood. In this contribution, we systematically study the effects of differentially private synthetic data generation on classification. We analyze disparities in model utility and bias caused by the synthetic dataset, measured through algorithmic fairness metrics. Our first set of results show that although there seems to be a clear negative correlation between privacy and utility (the more private, the less accurate) across all data synthesizers we evaluated, more privacy does not necessarily imply more bias. Additionally, we assess the effects of utilizing synthetic datasets for model training and model evaluation. We show that results obtained on synthetic data can misestimate the actual model performance when it is deployed on real data. We hence advocate on the need for defining proper testing protocols in scenarios where differentially private synthetic datasets are utilized for model training and evaluation.
A machine learning pipeline for aiding school identification from child trafficking images
Jun 09, 2021
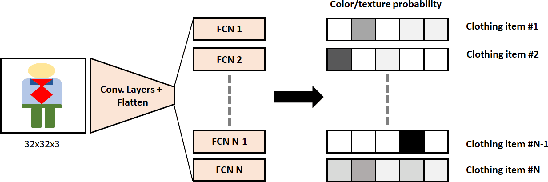
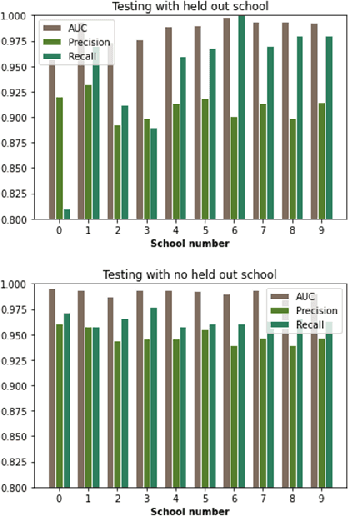
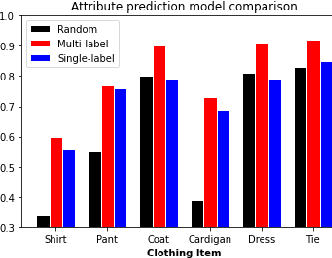
Child trafficking in a serious problem around the world. Every year there are more than 4 million victims of child trafficking around the world, many of them for the purposes of child sexual exploitation. In collaboration with UK Police and a non-profit focused on child abuse prevention, Global Emancipation Network, we developed a proof-of-concept machine learning pipeline to aid the identification of children from intercepted images. In this work, we focus on images that contain children wearing school uniforms to identify the school of origin. In the absence of a machine learning pipeline, this hugely time consuming and labor intensive task is manually conducted by law enforcement personnel. Thus, by automating aspects of the school identification process, we hope to significantly impact the speed of this portion of child identification. Our proposed pipeline consists of two machine learning models: i) to identify whether an image of a child contains a school uniform in it, and ii) identification of attributes of different school uniform items (such as color/texture of shirts, sweaters, blazers etc.). We describe the data collection, labeling, model development and validation process, along with strategies for efficient searching of schools using the model predictions.
Variational Inference in high-dimensional linear regression
Apr 25, 2021We study high-dimensional Bayesian linear regression with product priors. Using the nascent theory of non-linear large deviations (Chatterjee and Dembo,2016), we derive sufficient conditions for the leading-order correctness of the naive mean-field approximation to the log-normalizing constant of the posterior distribution. Subsequently, assuming a true linear model for the observed data, we derive a limiting infinite dimensional variational formula for the log normalizing constant of the posterior. Furthermore, we establish that under an additional "separation" condition, the variational problem has a unique optimizer, and this optimizer governs the probabilistic properties of the posterior distribution. We provide intuitive sufficient conditions for the validity of this "separation" condition. Finally, we illustrate our results on concrete examples with specific design matrices.
Reducing bias and increasing utility by federated generative modeling of medical images using a centralized adversary
Jan 18, 2021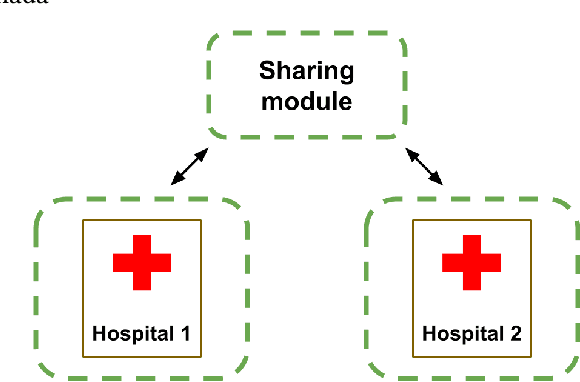


We introduce FELICIA (FEderated LearnIng with a CentralIzed Adversary) a generative mechanism enabling collaborative learning. In particular, we show how a data owner with limited and biased data could benefit from other data owners while keeping data from all the sources private. This is a common scenario in medical image analysis where privacy legislation prevents data from being shared outside local premises. FELICIA works for a large family of Generative Adversarial Networks (GAN) architectures including vanilla and conditional GANs as demonstrated in this work. We show that by using the FELICIA mechanism, a data owner with limited image samples can generate high-quality synthetic images with high utility while neither data owners has to provide access to its data. The sharing happens solely through a central discriminator that has access limited to synthetic data. Here, utility is defined as classification performance on a real test set. We demonstrate these benefits on several realistic healthcare scenarions using benchmark image datasets (MNIST, CIFAR-10) as well as on medical images for the task of skin lesion classification. With multiple experiments, we show that even in the worst cases, combining FELICIA with real data gracefully achieves performance on par with real data while most results significantly improves the utility.
MACE: A Flexible Framework for Membership Privacy Estimation in Generative Models
Sep 11, 2020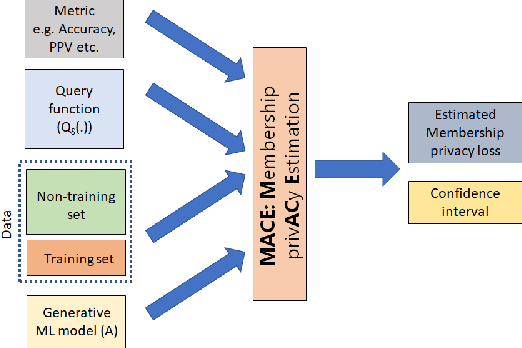
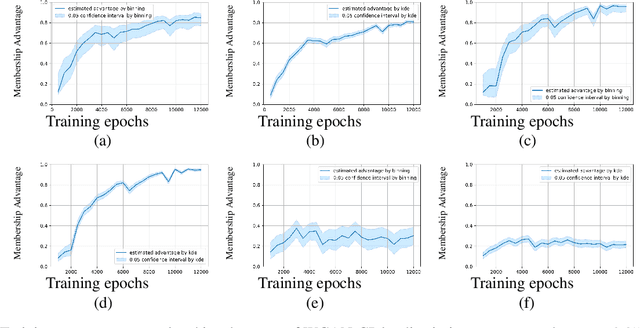
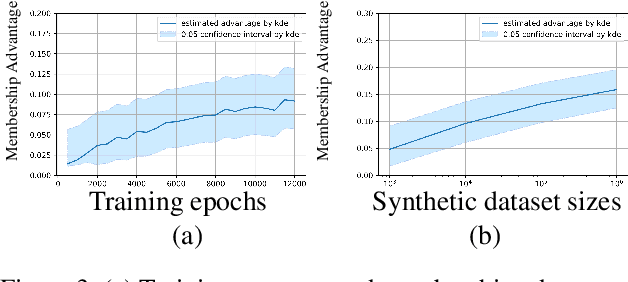
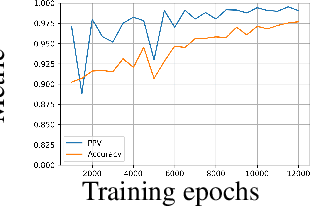
Generative models are widely used for publishing synthetic datasets. Despite practical successes, recent works have shown some generative models may leak privacy of the data that have been used during training. Membership inference attacks aim to determine whether a sample has been used in the training set given query access to the model API. Despite recent work in this area, many of the attacks designed against generative models require very specific attributes from the learned models (e.g. discriminator scores, generated images, etc.). Furthermore, many of these attacks are heuristic and do not provide effective bounds for privacy loss. In this work, we formally study the membership privacy leakage risk of generative models. Specifically, we formulate membership privacy as a statistical divergence between training samples and hold-out samples, and propose sample-based methods to estimate this divergence. Unlike previous works, our proposed metric and estimators make realistic and flexible assumptions. First, we use a generalizable metric as an alternative to accuracy, since practical model training often leads to imbalanced train/hold-out splits. Second, our estimators are capable of estimating statistical divergence using any scalar or vector valued attributes from the learned model instead of very specific attributes. Furthermore, we show a connection to differential privacy. This allows our proposed estimators to provide a data-driven certificate to understand the privacy budget needed for differentially private generative models. We demonstrate the utility of our framework through experimental demonstrations on different generative models using various model attributes yielding some new insights about membership leakage and vulnerabilities of models.
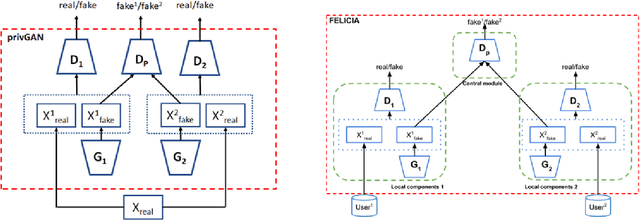
Protecting GANs against privacy attacks by preventing overfitting
Jan 03, 2020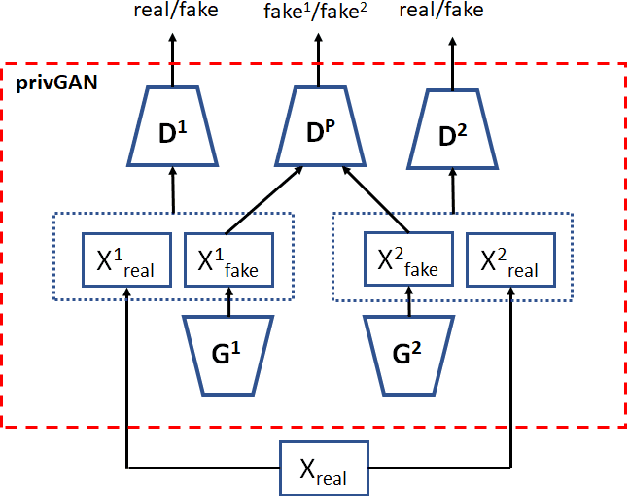


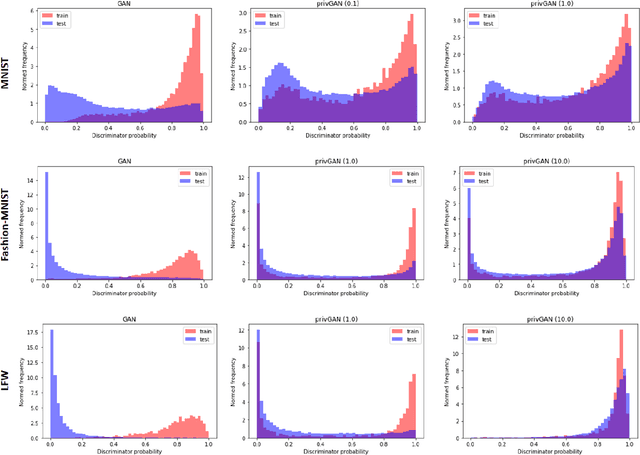
Generative Adversarial Networks (GANs) have made releasing of synthetic images a viable approach to share data without releasing the original dataset. It has been shown that such synthetic data can be used for a variety of downstream tasks such as training classifiers that would otherwise require the original dataset to be shared. However, recent work has shown that the GAN models and their synthetically generated data can be used to infer the training set membership by an adversary who has access to the entire dataset and some auxiliary information. Here we develop a new GAN architecture (privGAN) which provides protection against this mode of attack while leading to negligible loss in downstream performances. Our architecture explicitly prevents overfitting to the training set thereby providing implicit protection against white-box attacks. The main contributions of this paper are: i) we propose a novel GAN architecture that can generate synthetic data in a privacy preserving manner and demonstrate the effectiveness of our model against white--box attacks on several benchmark datasets, ii) we provide a theoretical understanding of the optimal solution of the GAN loss function, iii) we demonstrate on two common benchmark datasets that synthetic images generated by privGAN lead to negligible loss in downstream performance when compared against non--private GANs. While we have focosued on benchmarking privGAN exclusively of image datasets, the architecture of privGAN is not exclusive to image datasets and can be easily extended to other types of datasets.
Risks of Using Non-verified Open Data: A case study on using Machine Learning techniques for predicting Pregnancy Outcomes in India
Oct 21, 2019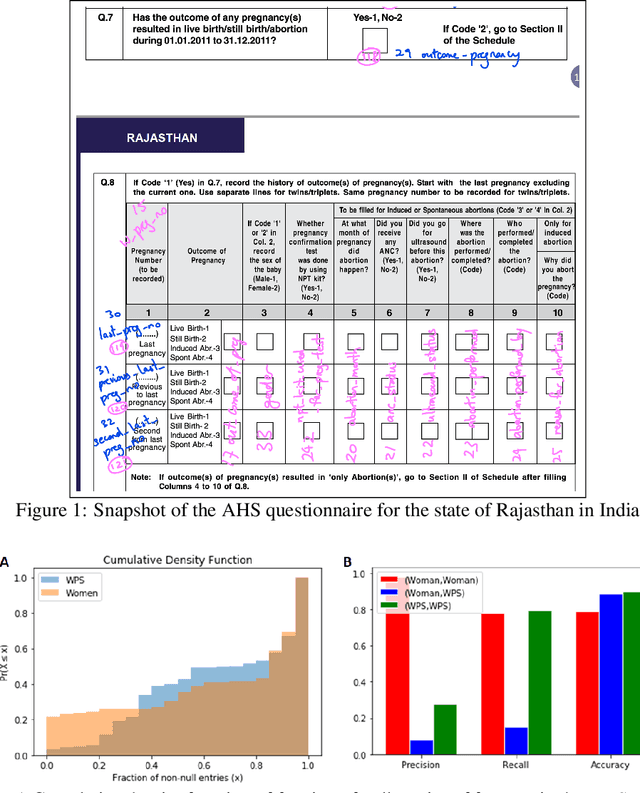
Artificial intelligence (AI) has evolved considerably in the last few years. While applications of AI is now becoming more common in fields like retail and marketing, application of AI in solving problems related to developing countries is still an emerging topic. Specially, AI applications in resource-poor settings remains relatively nascent. There is a huge scope of AI being used in such settings. For example, researchers have started exploring AI applications to reduce poverty and deliver a broad range of critical public services. However, despite many promising use cases, there are many dataset related challenges that one has to overcome in such projects. These challenges often take the form of missing data, incorrectly collected data and improperly labeled variables, among other factors. As a result, we can often end up using data that is not representative of the problem we are trying to solve. In this case study, we explore the challenges of using such an open dataset from India, to predict an important health outcome. We highlight how the use of AI without proper understanding of reporting metrics can lead to erroneous conclusions.