 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReducing bias and increasing utility by federated generative modeling of medical images using a centralized adversary
Jan 18, 2021

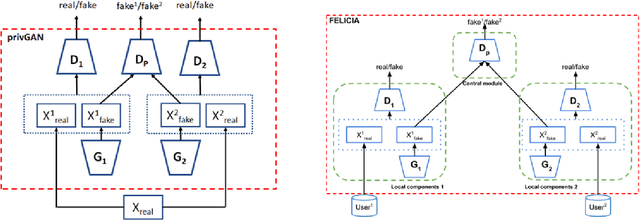

We introduce FELICIA (FEderated LearnIng with a CentralIzed Adversary) a generative mechanism enabling collaborative learning. In particular, we show how a data owner with limited and biased data could benefit from other data owners while keeping data from all the sources private. This is a common scenario in medical image analysis where privacy legislation prevents data from being shared outside local premises. FELICIA works for a large family of Generative Adversarial Networks (GAN) architectures including vanilla and conditional GANs as demonstrated in this work. We show that by using the FELICIA mechanism, a data owner with limited image samples can generate high-quality synthetic images with high utility while neither data owners has to provide access to its data. The sharing happens solely through a central discriminator that has access limited to synthetic data. Here, utility is defined as classification performance on a real test set. We demonstrate these benefits on several realistic healthcare scenarions using benchmark image datasets (MNIST, CIFAR-10) as well as on medical images for the task of skin lesion classification. With multiple experiments, we show that even in the worst cases, combining FELICIA with real data gracefully achieves performance on par with real data while most results significantly improves the utility.
Private data sharing between decentralized users through the privGAN architecture
Sep 14, 2020



More data is almost always beneficial for analysis and machine learning tasks. In many realistic situations however, an enterprise cannot share its data, either to keep a competitive advantage or to protect the privacy of the data sources, the enterprise's clients for example. We propose a method for data owners to share synthetic or fake versions of their data without sharing the actual data, nor the parameters of models that have direct access to the data. The method proposed is based on the privGAN architecture where local GANs are trained on their respective data subsets with an extra penalty from a central discriminator aiming to discriminate the origin of a given fake sample. We demonstrate that this approach, when applied to subsets of various sizes, leads to better utility for the owners than the utility from their real small datasets. The only shared pieces of information are the parameter updates of the central discriminator. The privacy is demonstrated with white-box attacks on the most vulnerable elments of the architecture and the results are close to random guessing. This method would apply naturally in a federated learning setting.
Topic Segmentation and Labeling in Asynchronous Conversations
Feb 04, 2014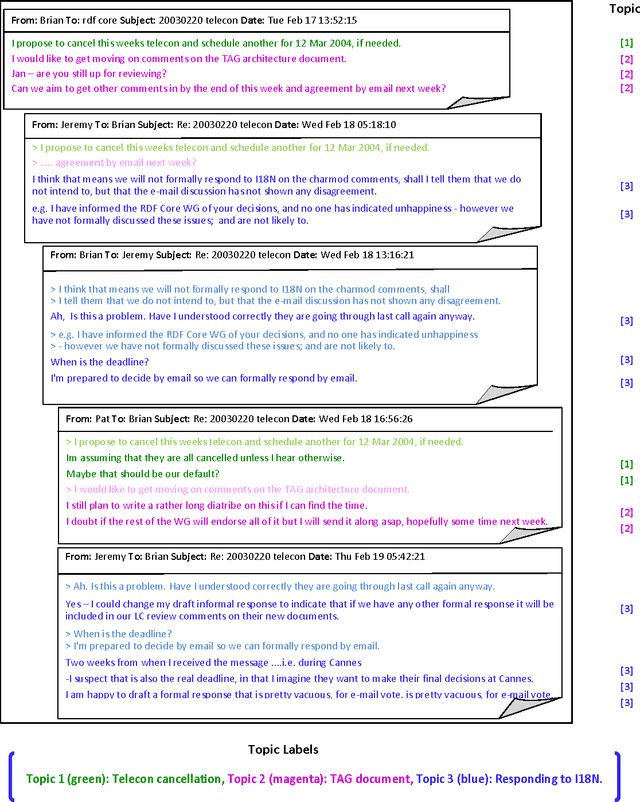
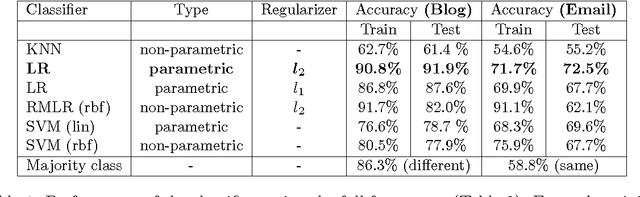
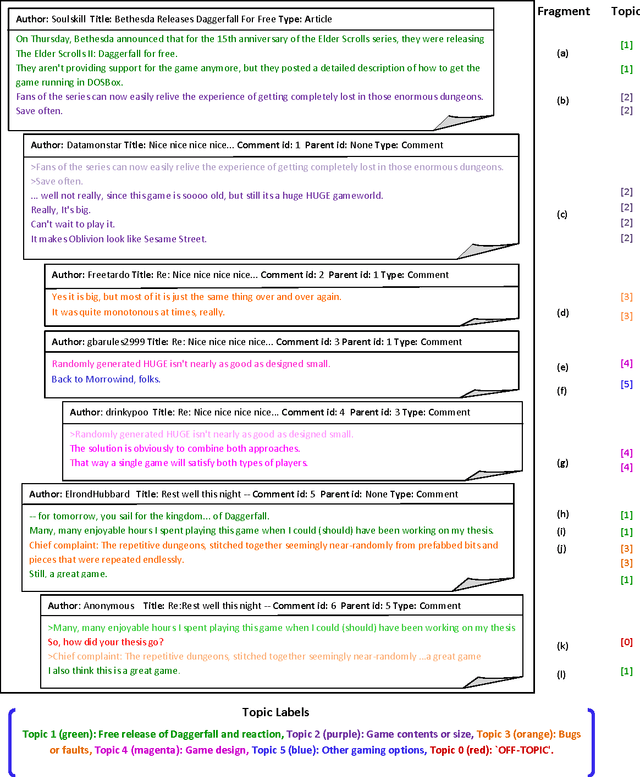
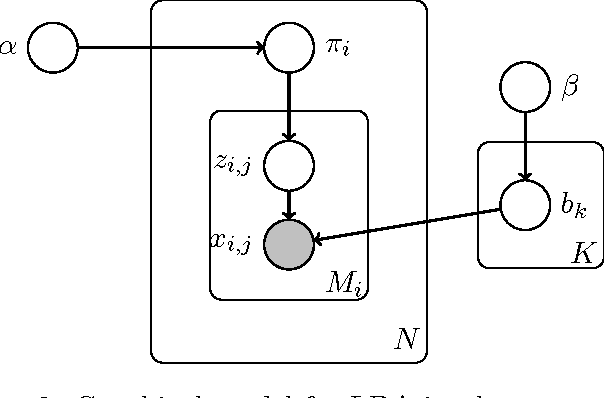
Topic segmentation and labeling is often considered a prerequisite for higher-level conversation analysis and has been shown to be useful in many Natural Language Processing (NLP) applications. We present two new corpora of email and blog conversations annotated with topics, and evaluate annotator reliability for the segmentation and labeling tasks in these asynchronous conversations. We propose a complete computational framework for topic segmentation and labeling in asynchronous conversations. Our approach extends state-of-the-art methods by considering a fine-grained structure of an asynchronous conversation, along with other conversational features by applying recent graph-based methods for NLP. For topic segmentation, we propose two novel unsupervised models that exploit the fine-grained conversational structure, and a novel graph-theoretic supervised model that combines lexical, conversational and topic features. For topic labeling, we propose two novel (unsupervised) random walk models that respectively capture conversation specific clues from two different sources: the leading sentences and the fine-grained conversational structure. Empirical evaluation shows that the segmentation and the labeling performed by our best models beat the state-of-the-art, and are highly correlated with human annotations.