 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Language Feedback via Variational Policy Distillation
May 14, 2026Reinforcement learning from verifiable rewards (RLVR) suffers from sparse outcome signals, creating severe exploration bottlenecks on complex reasoning tasks. Recent on-policy self-distillation methods attempt to address this by utilizing language feedback to generate dense, token-level supervision. However, these approaches rely on a fixed, passive teacher to interpret the feedback. As the student policy improves, the teacher's zero-shot assessment capabilities plateau, ultimately halting further learning. To overcome this, we propose Variational Policy Distillation (VPD), a framework that formalizes learning from language feedback as a Variational Expectation-Maximization (EM) problem. VPD co-evolves both policies: in the E-step, the teacher is actively refined on trajectory outcomes via an adaptive trust-region update, translating textual feedback into a dynamically improved target token distribution. In the M-step, the student internalizes this dense distributional guidance on its own on-policy rollouts. By continuously improving the teacher's ability to extract actionable signals from textual critique, VPD overcomes the limitations of passive distillation. Evaluated across diverse sources of diagnostic feedback on scientific reasoning and code generation tasks, VPD consistently outperforms both standard RLVR and existing self-distillation baselines. Finally, by stress-testing our framework on rigid mathematical reasoning and cold-start regimes, we illuminate the fundamental bounds of feedback-driven self-distillation compared to pure environment-driven RL.
Topic Segmentation and Labeling in Asynchronous Conversations
Feb 04, 2014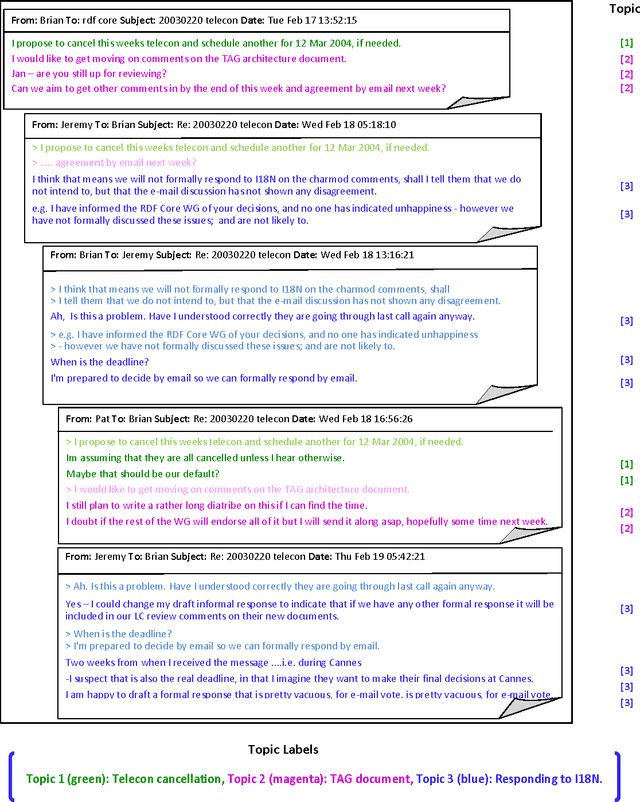
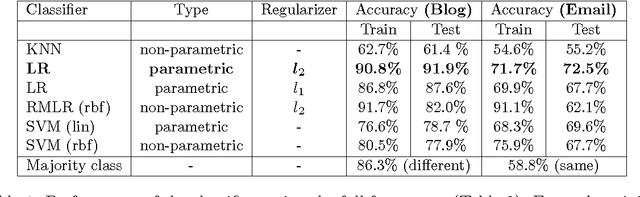
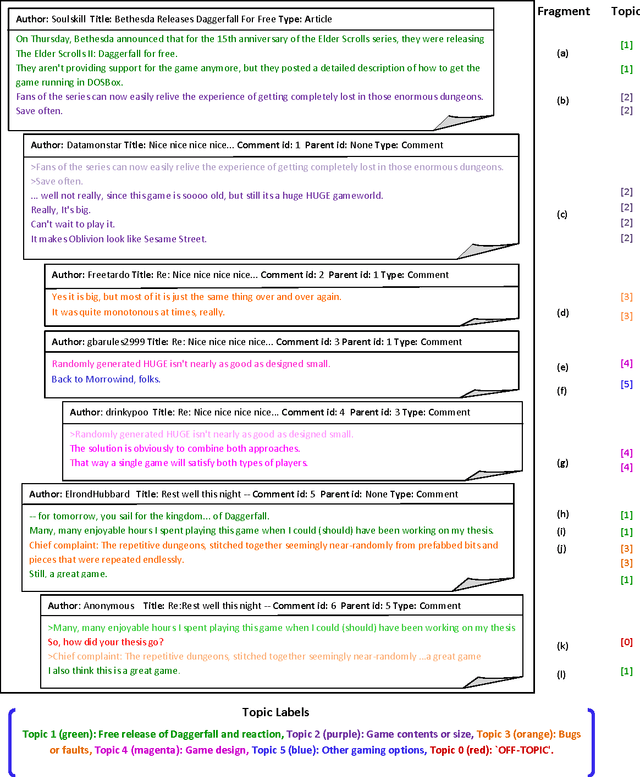
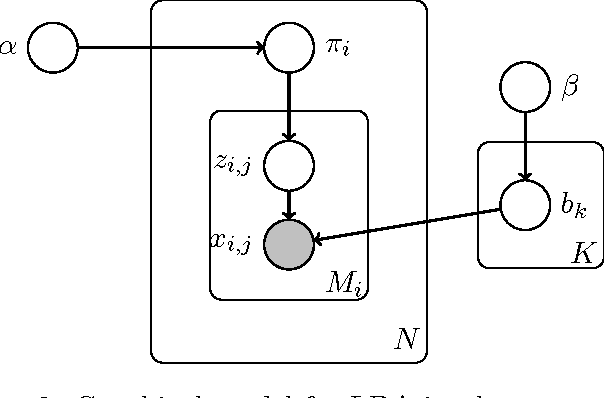
Topic segmentation and labeling is often considered a prerequisite for higher-level conversation analysis and has been shown to be useful in many Natural Language Processing (NLP) applications. We present two new corpora of email and blog conversations annotated with topics, and evaluate annotator reliability for the segmentation and labeling tasks in these asynchronous conversations. We propose a complete computational framework for topic segmentation and labeling in asynchronous conversations. Our approach extends state-of-the-art methods by considering a fine-grained structure of an asynchronous conversation, along with other conversational features by applying recent graph-based methods for NLP. For topic segmentation, we propose two novel unsupervised models that exploit the fine-grained conversational structure, and a novel graph-theoretic supervised model that combines lexical, conversational and topic features. For topic labeling, we propose two novel (unsupervised) random walk models that respectively capture conversation specific clues from two different sources: the leading sentences and the fine-grained conversational structure. Empirical evaluation shows that the segmentation and the labeling performed by our best models beat the state-of-the-art, and are highly correlated with human annotations.
Complex Question Answering: Unsupervised Learning Approaches and Experiments
Jan 15, 2014


Complex questions that require inferencing and synthesizing information from multiple documents can be seen as a kind of topic-oriented, informative multi-document summarization where the goal is to produce a single text as a compressed version of a set of documents with a minimum loss of relevant information. In this paper, we experiment with one empirical method and two unsupervised statistical machine learning techniques: K-means and Expectation Maximization (EM), for computing relative importance of the sentences. We compare the results of these approaches. Our experiments show that the empirical approach outperforms the other two techniques and EM performs better than K-means. However, the performance of these approaches depends entirely on the feature set used and the weighting of these features. In order to measure the importance and relevance to the user query we extract different kinds of features (i.e. lexical, lexical semantic, cosine similarity, basic element, tree kernel based syntactic and shallow-semantic) for each of the document sentences. We use a local search technique to learn the weights of the features. To the best of our knowledge, no study has used tree kernel functions to encode syntactic/semantic information for more complex tasks such as computing the relatedness between the query sentences and the document sentences in order to generate query-focused summaries (or answers to complex questions). For each of our methods of generating summaries (i.e. empirical, K-means and EM) we show the effects of syntactic and shallow-semantic features over the bag-of-words (BOW) features.