 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText Summarization With Graph Attention Networks
Apr 04, 2026This study aimed to leverage graph information, particularly Rhetorical Structure Theory (RST) and Co-reference (Coref) graphs, to enhance the performance of our baseline summarization models. Specifically, we experimented with a Graph Attention Network architecture to incorporate graph information. However, this architecture did not enhance the performance. Subsequently, we used a simple Multi-layer Perceptron architecture, which improved the results in our proposed model on our primary dataset, CNN/DM. Additionally, we annotated XSum dataset with RST graph information, establishing a benchmark for future graph-based summarization models. This secondary dataset posed multiple challenges, revealing both the merits and limitations of our models.
* Published in Proceedings of the 4th NeurIPS Efficient Natural Language and Speech Processing Workshop (ENLSP-IV), Vancouver, Canada, 2024. 14 pages, 8 figures
Generating Query Focused Summaries without Fine-tuning the Transformer-based Pre-trained Models
Mar 10, 2023



Fine-tuning the Natural Language Processing (NLP) models for each new data set requires higher computational time associated with increased carbon footprint and cost. However, fine-tuning helps the pre-trained models adapt to the latest data sets; what if we avoid the fine-tuning steps and attempt to generate summaries using just the pre-trained models to reduce computational time and cost. In this paper, we tried to omit the fine-tuning steps and investigate whether the Marginal Maximum Relevance (MMR)-based approach can help the pre-trained models to obtain query-focused summaries directly from a new data set that was not used to pre-train the models. First, we used topic modelling on Wikipedia Current Events Portal (WCEP) and Debatepedia datasets to generate queries for summarization tasks. Then, using MMR, we ranked the sentences of the documents according to the queries. Next, we passed the ranked sentences to seven transformer-based pre-trained models to perform the summarization tasks. Finally, we used the MMR approach again to select the query relevant sentences from the generated summaries of individual pre-trained models and constructed the final summary. As indicated by the experimental results, our MMR-based approach successfully ranked and selected the most relevant sentences as summaries and showed better performance than the individual pre-trained models.
Combining State-of-the-Art Models with Maximal Marginal Relevance for Few-Shot and Zero-Shot Multi-Document Summarization
Nov 19, 2022



In Natural Language Processing, multi-document summarization (MDS) poses many challenges to researchers above those posed by single-document summarization (SDS). These challenges include the increased search space and greater potential for the inclusion of redundant information. While advancements in deep learning approaches have led to the development of several advanced language models capable of summarization, the variety of training data specific to the problem of MDS remains relatively limited. Therefore, MDS approaches which require little to no pretraining, known as few-shot or zero-shot applications, respectively, could be beneficial additions to the current set of tools available in summarization. To explore one possible approach, we devise a strategy for combining state-of-the-art models' outputs using maximal marginal relevance (MMR) with a focus on query relevance rather than document diversity. Our MMR-based approach shows improvement over some aspects of the current state-of-the-art results in both few-shot and zero-shot MDS applications while maintaining a state-of-the-art standard of output by all available metrics.
Extract with Order for Coherent Multi-Document Summarization
Jun 12, 2017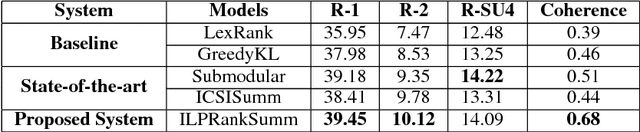
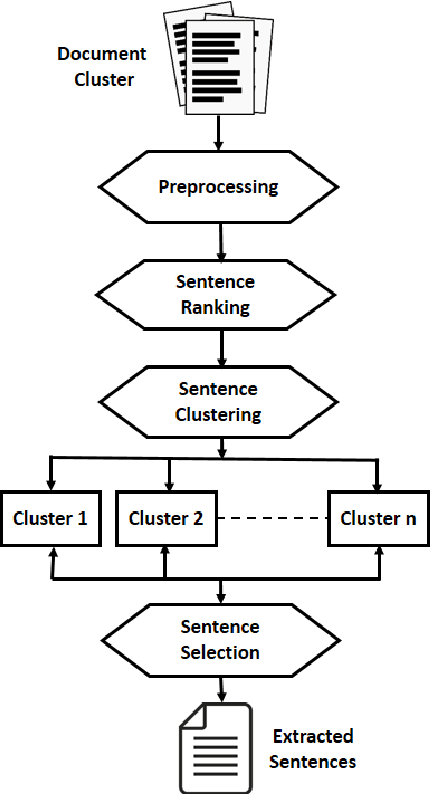
In this work, we aim at developing an extractive summarizer in the multi-document setting. We implement a rank based sentence selection using continuous vector representations along with key-phrases. Furthermore, we propose a model to tackle summary coherence for increasing readability. We conduct experiments on the Document Understanding Conference (DUC) 2004 datasets using ROUGE toolkit. Our experiments demonstrate that the methods bring significant improvements over the state of the art methods in terms of informativity and coherence.
Complex Question Answering: Unsupervised Learning Approaches and Experiments
Jan 15, 2014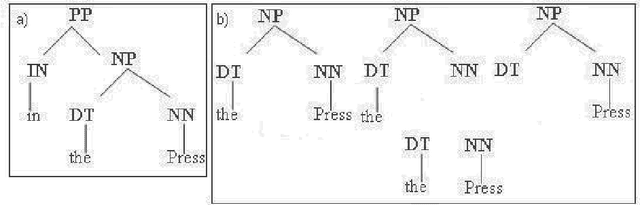

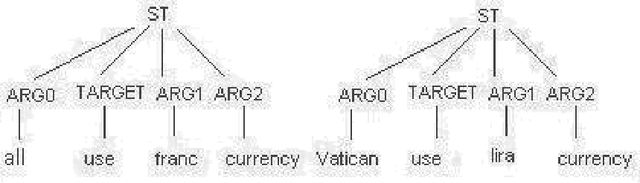

Complex questions that require inferencing and synthesizing information from multiple documents can be seen as a kind of topic-oriented, informative multi-document summarization where the goal is to produce a single text as a compressed version of a set of documents with a minimum loss of relevant information. In this paper, we experiment with one empirical method and two unsupervised statistical machine learning techniques: K-means and Expectation Maximization (EM), for computing relative importance of the sentences. We compare the results of these approaches. Our experiments show that the empirical approach outperforms the other two techniques and EM performs better than K-means. However, the performance of these approaches depends entirely on the feature set used and the weighting of these features. In order to measure the importance and relevance to the user query we extract different kinds of features (i.e. lexical, lexical semantic, cosine similarity, basic element, tree kernel based syntactic and shallow-semantic) for each of the document sentences. We use a local search technique to learn the weights of the features. To the best of our knowledge, no study has used tree kernel functions to encode syntactic/semantic information for more complex tasks such as computing the relatedness between the query sentences and the document sentences in order to generate query-focused summaries (or answers to complex questions). For each of our methods of generating summaries (i.e. empirical, K-means and EM) we show the effects of syntactic and shallow-semantic features over the bag-of-words (BOW) features.