 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStop Taking Tokenizers for Granted: They Are Core Design Decisions in Large Language Models
Jan 19, 2026Tokenization underlies every large language model, yet it remains an under-theorized and inconsistently designed component. Common subword approaches such as Byte Pair Encoding (BPE) offer scalability but often misalign with linguistic structure, amplify bias, and waste capacity across languages and domains. This paper reframes tokenization as a core modeling decision rather than a preprocessing step. We argue for a context-aware framework that integrates tokenizer and model co-design, guided by linguistic, domain, and deployment considerations. Standardized evaluation and transparent reporting are essential to make tokenization choices accountable and comparable. Treating tokenization as a core design problem, not a technical afterthought, can yield language technologies that are fairer, more efficient, and more adaptable.
SurveyGen: Quality-Aware Scientific Survey Generation with Large Language Models
Aug 25, 2025Automatic survey generation has emerged as a key task in scientific document processing. While large language models (LLMs) have shown promise in generating survey texts, the lack of standardized evaluation datasets critically hampers rigorous assessment of their performance against human-written surveys. In this work, we present SurveyGen, a large-scale dataset comprising over 4,200 human-written surveys across diverse scientific domains, along with 242,143 cited references and extensive quality-related metadata for both the surveys and the cited papers. Leveraging this resource, we build QUAL-SG, a novel quality-aware framework for survey generation that enhances the standard Retrieval-Augmented Generation (RAG) pipeline by incorporating quality-aware indicators into literature retrieval to assess and select higher-quality source papers. Using this dataset and framework, we systematically evaluate state-of-the-art LLMs under varying levels of human involvement - from fully automatic generation to human-guided writing. Experimental results and human evaluations show that while semi-automatic pipelines can achieve partially competitive outcomes, fully automatic survey generation still suffers from low citation quality and limited critical analysis.
Judging the Judges: Can Large Vision-Language Models Fairly Evaluate Chart Comprehension and Reasoning?
May 13, 2025Charts are ubiquitous as they help people understand and reason with data. Recently, various downstream tasks, such as chart question answering, chart2text, and fact-checking, have emerged. Large Vision-Language Models (LVLMs) show promise in tackling these tasks, but their evaluation is costly and time-consuming, limiting real-world deployment. While using LVLMs as judges to assess the chart comprehension capabilities of other LVLMs could streamline evaluation processes, challenges like proprietary datasets, restricted access to powerful models, and evaluation costs hinder their adoption in industrial settings. To this end, we present a comprehensive evaluation of 13 open-source LVLMs as judges for diverse chart comprehension and reasoning tasks. We design both pairwise and pointwise evaluation tasks covering criteria like factual correctness, informativeness, and relevancy. Additionally, we analyze LVLM judges based on format adherence, positional consistency, length bias, and instruction-following. We focus on cost-effective LVLMs (<10B parameters) suitable for both research and commercial use, following a standardized evaluation protocol and rubric to measure the LVLM judge's accuracy. Experimental results reveal notable variability: while some open LVLM judges achieve GPT-4-level evaluation performance (about 80% agreement with GPT-4 judgments), others struggle (below ~10% agreement). Our findings highlight that state-of-the-art open-source LVLMs can serve as cost-effective automatic evaluators for chart-related tasks, though biases such as positional preference and length bias persist.
eC-Tab2Text: Aspect-Based Text Generation from e-Commerce Product Tables
Feb 20, 2025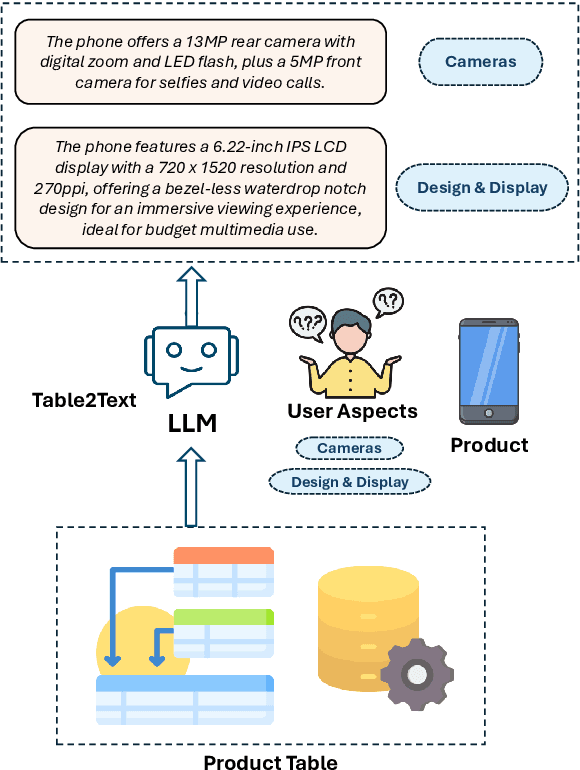
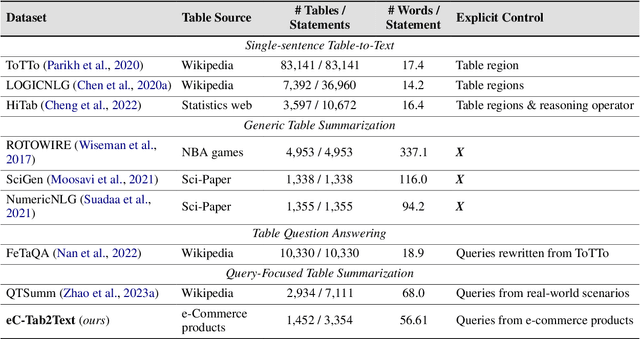

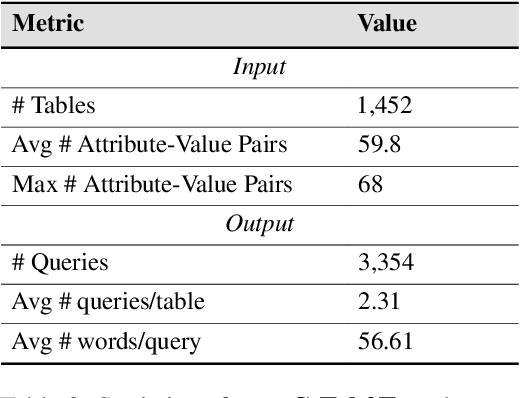
Large Language Models (LLMs) have demonstrated exceptional versatility across diverse domains, yet their application in e-commerce remains underexplored due to a lack of domain-specific datasets. To address this gap, we introduce eC-Tab2Text, a novel dataset designed to capture the intricacies of e-commerce, including detailed product attributes and user-specific queries. Leveraging eC-Tab2Text, we focus on text generation from product tables, enabling LLMs to produce high-quality, attribute-specific product reviews from structured tabular data. Fine-tuned models were rigorously evaluated using standard Table2Text metrics, alongside correctness, faithfulness, and fluency assessments. Our results demonstrate substantial improvements in generating contextually accurate reviews, highlighting the transformative potential of tailored datasets and fine-tuning methodologies in optimizing e-commerce workflows. This work highlights the potential of LLMs in e-commerce workflows and the essential role of domain-specific datasets in tailoring them to industry-specific challenges.
LFOSum: Summarizing Long-form Opinions with Large Language Models
Oct 16, 2024Online reviews play a pivotal role in influencing consumer decisions across various domains, from purchasing products to selecting hotels or restaurants. However, the sheer volume of reviews -- often containing repetitive or irrelevant content -- leads to information overload, making it challenging for users to extract meaningful insights. Traditional opinion summarization models face challenges in handling long inputs and large volumes of reviews, while newer Large Language Model (LLM) approaches often fail to generate accurate and faithful summaries. To address those challenges, this paper introduces (1) a new dataset of long-form user reviews, each entity comprising over a thousand reviews, (2) two training-free LLM-based summarization approaches that scale to long inputs, and (3) automatic evaluation metrics. Our dataset of user reviews is paired with in-depth and unbiased critical summaries by domain experts, serving as a reference for evaluation. Additionally, our novel reference-free evaluation metrics provide a more granular, context-sensitive assessment of summary faithfulness. We benchmark several open-source and closed-source LLMs using our methods. Our evaluation reveals that LLMs still face challenges in balancing sentiment and format adherence in long-form summaries, though open-source models can narrow the gap when relevant information is retrieved in a focused manner.
KidLM: Advancing Language Models for Children -- Early Insights and Future Directions
Oct 04, 2024



Recent studies highlight the potential of large language models in creating educational tools for children, yet significant challenges remain in maintaining key child-specific properties such as linguistic nuances, cognitive needs, and safety standards. In this paper, we explore foundational steps toward the development of child-specific language models, emphasizing the necessity of high-quality pre-training data. We introduce a novel user-centric data collection pipeline that involves gathering and validating a corpus specifically written for and sometimes by children. Additionally, we propose a new training objective, Stratified Masking, which dynamically adjusts masking probabilities based on our domain-specific child language data, enabling models to prioritize vocabulary and concepts more suitable for children. Experimental evaluations demonstrate that our model excels in understanding lower grade-level text, maintains safety by avoiding stereotypes, and captures children's unique preferences. Furthermore, we provide actionable insights for future research and development in child-specific language modeling.
XL-HeadTags: Leveraging Multimodal Retrieval Augmentation for the Multilingual Generation of News Headlines and Tags
Jun 07, 2024



Millions of news articles published online daily can overwhelm readers. Headlines and entity (topic) tags are essential for guiding readers to decide if the content is worth their time. While headline generation has been extensively studied, tag generation remains largely unexplored, yet it offers readers better access to topics of interest. The need for conciseness in capturing readers' attention necessitates improved content selection strategies for identifying salient and relevant segments within lengthy articles, thereby guiding language models effectively. To address this, we propose to leverage auxiliary information such as images and captions embedded in the articles to retrieve relevant sentences and utilize instruction tuning with variations to generate both headlines and tags for news articles in a multilingual context. To make use of the auxiliary information, we have compiled a dataset named XL-HeadTags, which includes 20 languages across 6 diverse language families. Through extensive evaluation, we demonstrate the effectiveness of our plug-and-play multimodal-multilingual retrievers for both tasks. Additionally, we have developed a suite of tools for processing and evaluating multilingual texts, significantly contributing to the research community by enabling more accurate and efficient analysis across languages.
Are Large Vision Language Models up to the Challenge of Chart Comprehension and Reasoning? An Extensive Investigation into the Capabilities and Limitations of LVLMs
Jun 01, 2024


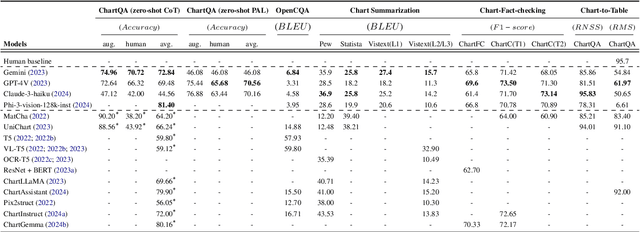
Natural language is a powerful complementary modality of communication for data visualizations, such as bar and line charts. To facilitate chart-based reasoning using natural language, various downstream tasks have been introduced recently such as chart question answering, chart summarization, and fact-checking with charts. These tasks pose a unique challenge, demanding both vision-language reasoning and a nuanced understanding of chart data tables, visual encodings, and natural language prompts. Despite the recent success of Large Language Models (LLMs) across diverse NLP tasks, their abilities and limitations in the realm of data visualization remain under-explored, possibly due to their lack of multi-modal capabilities. To bridge the gap, this paper presents the first comprehensive evaluation of the recently developed large vision language models (LVLMs) for chart understanding and reasoning tasks. Our evaluation includes a comprehensive assessment of LVLMs, including GPT-4V and Gemini, across four major chart reasoning tasks. Furthermore, we perform a qualitative evaluation of LVLMs' performance on a diverse range of charts, aiming to provide a thorough analysis of their strengths and weaknesses. Our findings reveal that LVLMs demonstrate impressive abilities in generating fluent texts covering high-level data insights while also encountering common problems like hallucinations, factual errors, and data bias. We highlight the key strengths and limitations of chart comprehension tasks, offering insights for future research.
BenLLMEval: A Comprehensive Evaluation into the Potentials and Pitfalls of Large Language Models on Bengali NLP
Sep 22, 2023Large Language Models (LLMs) have emerged as one of the most important breakthroughs in natural language processing (NLP) for their impressive skills in language generation and other language-specific tasks. Though LLMs have been evaluated in various tasks, mostly in English, they have not yet undergone thorough evaluation in under-resourced languages such as Bengali (Bangla). In this paper, we evaluate the performance of LLMs for the low-resourced Bangla language. We select various important and diverse Bangla NLP tasks, such as abstractive summarization, question answering, paraphrasing, natural language inference, text classification, and sentiment analysis for zero-shot evaluation with ChatGPT, LLaMA-2, and Claude-2 and compare the performance with state-of-the-art fine-tuned models. Our experimental results demonstrate an inferior performance of LLMs for different Bangla NLP tasks, calling for further effort to develop better understanding of LLMs in low-resource languages like Bangla.
On the Role of Reviewer Expertise in Temporal Review Helpfulness Prediction
Feb 22, 2023Helpful reviews have been essential for the success of e-commerce services, as they help customers make quick purchase decisions and benefit the merchants in their sales. While many reviews are informative, others provide little value and may contain spam, excessive appraisal, or unexpected biases. With the large volume of reviews and their uneven quality, the problem of detecting helpful reviews has drawn much attention lately. Existing methods for identifying helpful reviews primarily focus on review text and ignore the two key factors of (1) who post the reviews and (2) when the reviews are posted. Moreover, the helpfulness votes suffer from scarcity for less popular products and recently submitted (a.k.a., cold-start) reviews. To address these challenges, we introduce a dataset and develop a model that integrates the reviewer's expertise, derived from the past review history of the reviewers, and the temporal dynamics of the reviews to automatically assess review helpfulness. We conduct experiments on our dataset to demonstrate the effectiveness of incorporating these factors and report improved results compared to several well-established baselines.