 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStop Taking Tokenizers for Granted: They Are Core Design Decisions in Large Language Models
Jan 19, 2026Tokenization underlies every large language model, yet it remains an under-theorized and inconsistently designed component. Common subword approaches such as Byte Pair Encoding (BPE) offer scalability but often misalign with linguistic structure, amplify bias, and waste capacity across languages and domains. This paper reframes tokenization as a core modeling decision rather than a preprocessing step. We argue for a context-aware framework that integrates tokenizer and model co-design, guided by linguistic, domain, and deployment considerations. Standardized evaluation and transparent reporting are essential to make tokenization choices accountable and comparable. Treating tokenization as a core design problem, not a technical afterthought, can yield language technologies that are fairer, more efficient, and more adaptable.
ZeroSumEval: Scaling LLM Evaluation with Inter-Model Competition
Apr 17, 2025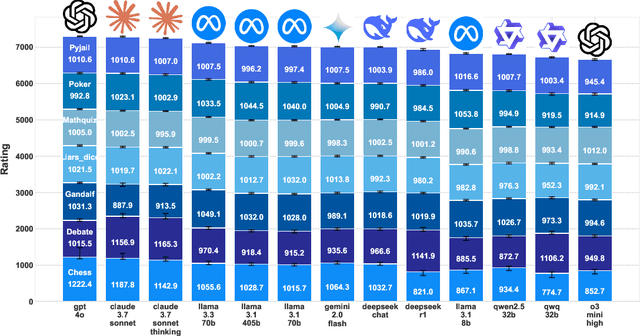



Evaluating the capabilities of Large Language Models (LLMs) has traditionally relied on static benchmark datasets, human assessments, or model-based evaluations - methods that often suffer from overfitting, high costs, and biases. ZeroSumEval is a novel competition-based evaluation protocol that leverages zero-sum games to assess LLMs with dynamic benchmarks that resist saturation. ZeroSumEval encompasses a diverse suite of games, including security challenges (PyJail), classic games (Chess, Liar's Dice, Poker), knowledge tests (MathQuiz), and persuasion challenges (Gandalf, Debate). These games are designed to evaluate a range of AI capabilities such as strategic reasoning, planning, knowledge application, and creativity. Building upon recent studies that highlight the effectiveness of game-based evaluations for LLMs, ZeroSumEval enhances these approaches by providing a standardized and extensible framework. To demonstrate this, we conduct extensive experiments with >7000 simulations across 7 games and 13 models. Our results show that while frontier models from the GPT and Claude families can play common games and answer questions, they struggle to play games that require creating novel and challenging questions. We also observe that models cannot reliably jailbreak each other and fail generally at tasks requiring creativity. We release our code at https://github.com/facebookresearch/ZeroSumEval.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
ALLaM: Large Language Models for Arabic and English
Jul 22, 2024



We present ALLaM: Arabic Large Language Model, a series of large language models to support the ecosystem of Arabic Language Technologies (ALT). ALLaM is carefully trained considering the values of language alignment and knowledge transfer at scale. Our autoregressive decoder-only architecture models demonstrate how second-language acquisition via vocabulary expansion and pretraining on a mixture of Arabic and English text can steer a model towards a new language (Arabic) without any catastrophic forgetting in the original language (English). Furthermore, we highlight the effectiveness of using parallel/translated data to aid the process of knowledge alignment between languages. Finally, we show that extensive alignment with human preferences can significantly enhance the performance of a language model compared to models of a larger scale with lower quality alignment. ALLaM achieves state-of-the-art performance in various Arabic benchmarks, including MMLU Arabic, ACVA, and Arabic Exams. Our aligned models improve both in Arabic and English from their base aligned models.
A Systematic Survey and Critical Review on Evaluating Large Language Models: Challenges, Limitations, and Recommendations
Jul 04, 2024



Large Language Models (LLMs) have recently gained significant attention due to their remarkable capabilities in performing diverse tasks across various domains. However, a thorough evaluation of these models is crucial before deploying them in real-world applications to ensure they produce reliable performance. Despite the well-established importance of evaluating LLMs in the community, the complexity of the evaluation process has led to varied evaluation setups, causing inconsistencies in findings and interpretations. To address this, we systematically review the primary challenges and limitations causing these inconsistencies and unreliable evaluations in various steps of LLM evaluation. Based on our critical review, we present our perspectives and recommendations to ensure LLM evaluations are reproducible, reliable, and robust.
When Benchmarks are Targets: Revealing the Sensitivity of Large Language Model Leaderboards
Feb 01, 2024



Large Language Model (LLM) leaderboards based on benchmark rankings are regularly used to guide practitioners in model selection. Often, the published leaderboard rankings are taken at face value - we show this is a (potentially costly) mistake. Under existing leaderboards, the relative performance of LLMs is highly sensitive to (often minute) details. We show that for popular multiple choice question benchmarks (e.g. MMLU) minor perturbations to the benchmark, such as changing the order of choices or the method of answer selection, result in changes in rankings up to 8 positions. We explain this phenomenon by conducting systematic experiments over three broad categories of benchmark perturbations and identifying the sources of this behavior. Our analysis results in several best-practice recommendations, including the advantage of a hybrid scoring method for answer selection. Our study highlights the dangers of relying on simple benchmark evaluations and charts the path for more robust evaluation schemes on the existing benchmarks.
BenLLMEval: A Comprehensive Evaluation into the Potentials and Pitfalls of Large Language Models on Bengali NLP
Sep 22, 2023Large Language Models (LLMs) have emerged as one of the most important breakthroughs in natural language processing (NLP) for their impressive skills in language generation and other language-specific tasks. Though LLMs have been evaluated in various tasks, mostly in English, they have not yet undergone thorough evaluation in under-resourced languages such as Bengali (Bangla). In this paper, we evaluate the performance of LLMs for the low-resourced Bangla language. We select various important and diverse Bangla NLP tasks, such as abstractive summarization, question answering, paraphrasing, natural language inference, text classification, and sentiment analysis for zero-shot evaluation with ChatGPT, LLaMA-2, and Claude-2 and compare the performance with state-of-the-art fine-tuned models. Our experimental results demonstrate an inferior performance of LLMs for different Bangla NLP tasks, calling for further effort to develop better understanding of LLMs in low-resource languages like Bangla.
A Systematic Study and Comprehensive Evaluation of ChatGPT on Benchmark Datasets
Jun 08, 2023



The development of large language models (LLMs) such as ChatGPT has brought a lot of attention recently. However, their evaluation in the benchmark academic datasets remains under-explored due to the difficulty of evaluating the generative outputs produced by this model against the ground truth. In this paper, we aim to present a thorough evaluation of ChatGPT's performance on diverse academic datasets, covering tasks like question-answering, text summarization, code generation, commonsense reasoning, mathematical problem-solving, machine translation, bias detection, and ethical considerations. Specifically, we evaluate ChatGPT across 140 tasks and analyze 255K responses it generates in these datasets. This makes our work the largest evaluation of ChatGPT in NLP benchmarks. In short, our study aims to validate the strengths and weaknesses of ChatGPT in various tasks and provide insights for future research using LLMs. We also report a new emergent ability to follow multi-query instructions that we mostly found in ChatGPT and other instruction-tuned models. Our extensive evaluation shows that even though ChatGPT is capable of performing a wide variety of tasks, and may obtain impressive performance in several benchmark datasets, it is still far from achieving the ability to reliably solve many challenging tasks. By providing a thorough assessment of ChatGPT's performance across diverse NLP tasks, this paper sets the stage for a targeted deployment of ChatGPT-like LLMs in real-world applications.
xCodeEval: A Large Scale Multilingual Multitask Benchmark for Code Understanding, Generation, Translation and Retrieval
Mar 06, 2023



The ability to solve problems is a hallmark of intelligence and has been an enduring goal in AI. AI systems that can create programs as solutions to problems or assist developers in writing programs can increase productivity and make programming more accessible. Recently, pre-trained large language models have shown impressive abilities in generating new codes from natural language descriptions, repairing buggy codes, translating codes between languages, and retrieving relevant code segments. However, the evaluation of these models has often been performed in a scattered way on only one or two specific tasks, in a few languages, at a partial granularity (e.g., function) level and in many cases without proper training data. Even more concerning is that in most cases the evaluation of generated codes has been done in terms of mere lexical overlap rather than actual execution whereas semantic similarity (or equivalence) of two code segments depends only on their ``execution similarity'', i.e., being able to get the same output for a given input.
SPT: Semi-Parametric Prompt Tuning for Multitask Prompted Learning
Dec 21, 2022



Pre-trained large language models can efficiently interpolate human-written prompts in a natural way. Multitask prompted learning can help generalization through a diverse set of tasks at once, thus enhancing the potential for more effective downstream fine-tuning. To perform efficient multitask-inference in the same batch, parameter-efficient fine-tuning methods such as prompt tuning have been proposed. However, the existing prompt tuning methods may lack generalization. We propose SPT, a semi-parametric prompt tuning method for multitask prompted learning. The novel component of SPT is a memory bank from where memory prompts are retrieved based on discrete prompts. Extensive experiments, such as (i) fine-tuning a full language model with SPT on 31 different tasks from 8 different domains and evaluating zero-shot generalization on 9 heldout datasets under 5 NLP task categories and (ii) pretraining SPT on the GLUE datasets and evaluating fine-tuning on the SuperGLUE datasets, demonstrate effectiveness of SPT.