 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAraMix: Recycling, Refiltering, and Deduplicating to Deliver the Largest Arabic Pretraining Corpus
Dec 21, 2025We present AraMix, a deduplicated Arabic pretraining corpus containing approximately 178 billion tokens across 179 million documents. Rather than scraping the web again, AraMix demonstrates that substantial value lies in systematically reusing and curating existing pretraining datasets: we combine seven publicly available Arabic web datasets, apply quality filtering designed specifically for Arabic text to re-filter some datasets, and perform cross-dataset deduplication, both MinHash and sentence-level. This approach reveals that nearly 60% of tokens across these independently collected corpora are duplicates, redundancy that any new scraping efforts will reproduce. Our work suggests that for lower resource languages, investment in curation pipelines for existing data yields greater returns than additional web crawls, an approach that allowed us to curate the largest heavily filtered publicly available Arabic pretraining corpus.
SmolTulu: Higher Learning Rate to Batch Size Ratios Can Lead to Better Reasoning in SLMs
Dec 11, 2024
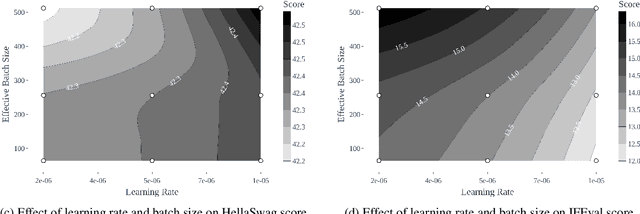

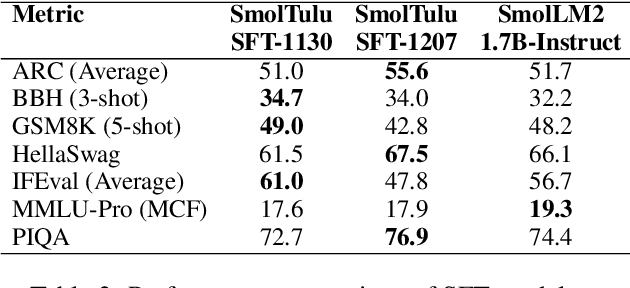
We present SmolTulu-1.7b-Instruct, referenced in this report as SmolTulu-DPO-1130, an instruction-tuned language model that adapts AllenAI's Tulu 3 post-training pipeline to enhance Huggingface's SmolLM2-1.7B base model. Through comprehensive empirical analysis using a 135M parameter model, we demonstrate that the relationship between learning rate and batch size significantly impacts model performance in a task-dependent manner. Our findings reveal a clear split: reasoning tasks like ARC and GSM8K benefit from higher learning rate to batch size ratios, while pattern recognition tasks such as HellaSwag and IFEval show optimal performance with lower ratios. These insights informed the development of SmolTulu, which achieves state-of-the-art performance among sub-2B parameter models on instruction following, scoring 67.7% on IFEval ($\Delta$11%), and mathematical reasoning with 51.6% on GSM8K ($\Delta$3.4%), with an alternate version achieving scoring 57.1% on ARC ($\Delta5.4%$). We release our model, training recipes, and ablation studies to facilitate further research in efficient model alignment, demonstrating that careful adaptation of optimization dynamics can help bridge the capability gap between small and large language models.
Fineweb-Edu-Ar: Machine-translated Corpus to Support Arabic Small Language Models
Nov 10, 2024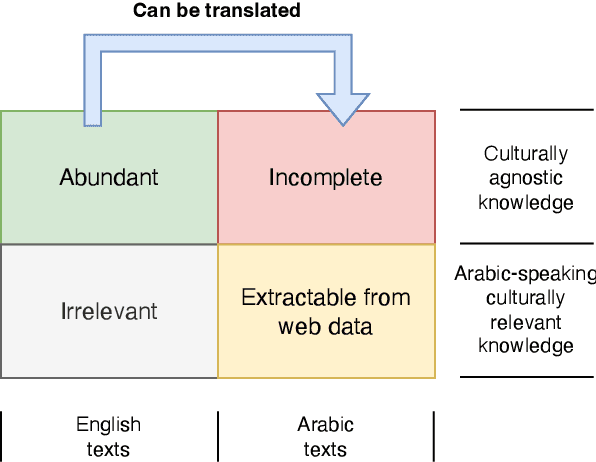
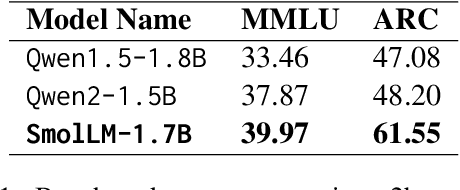
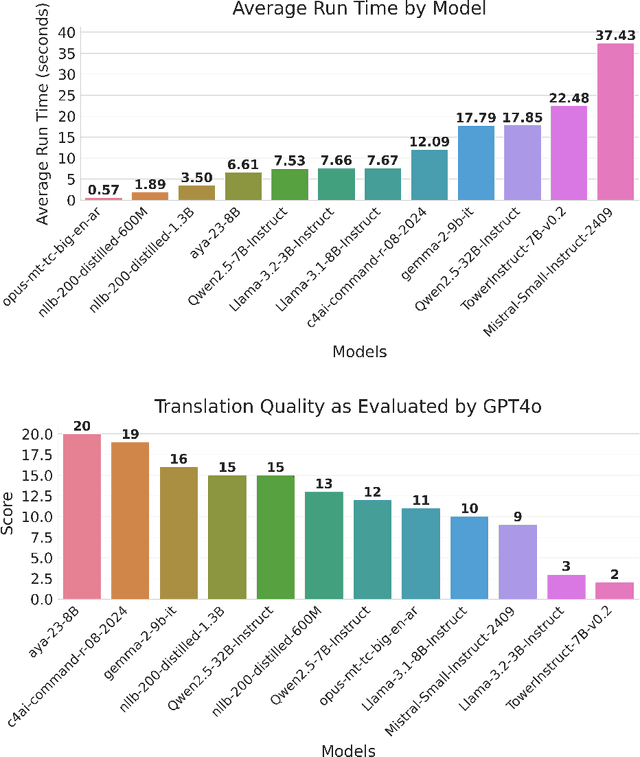
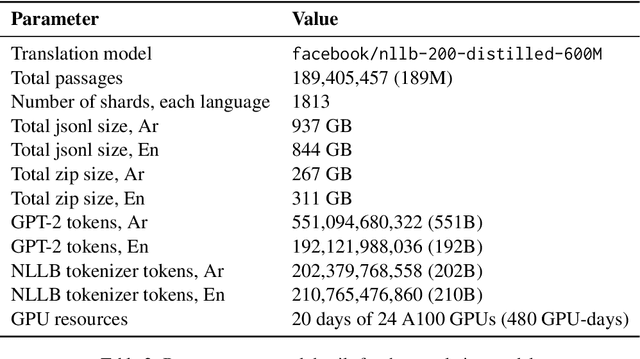
As large language models (LLMs) grow and develop, so do their data demands. This is especially true for multilingual LLMs, where the scarcity of high-quality and readily available data online has led to a multitude of synthetic dataset generation approaches. A key technique in this space is machine translation (MT), where high-quality English text is adapted to a target, comparatively low-resource language. This report introduces FineWeb-Edu-Ar, a machine-translated version of the exceedingly popular (deduplicated) FineWeb-Edu dataset from HuggingFace. To the best of our knowledge, FineWeb-Edu-Ar is the largest publicly available machine-translated Arabic dataset out there, with its size of 202B tokens of an Arabic-trained tokenizer.
When Benchmarks are Targets: Revealing the Sensitivity of Large Language Model Leaderboards
Feb 01, 2024



Large Language Model (LLM) leaderboards based on benchmark rankings are regularly used to guide practitioners in model selection. Often, the published leaderboard rankings are taken at face value - we show this is a (potentially costly) mistake. Under existing leaderboards, the relative performance of LLMs is highly sensitive to (often minute) details. We show that for popular multiple choice question benchmarks (e.g. MMLU) minor perturbations to the benchmark, such as changing the order of choices or the method of answer selection, result in changes in rankings up to 8 positions. We explain this phenomenon by conducting systematic experiments over three broad categories of benchmark perturbations and identifying the sources of this behavior. Our analysis results in several best-practice recommendations, including the advantage of a hybrid scoring method for answer selection. Our study highlights the dangers of relying on simple benchmark evaluations and charts the path for more robust evaluation schemes on the existing benchmarks.