 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFineweb-Edu-Ar: Machine-translated Corpus to Support Arabic Small Language Models
Nov 10, 2024
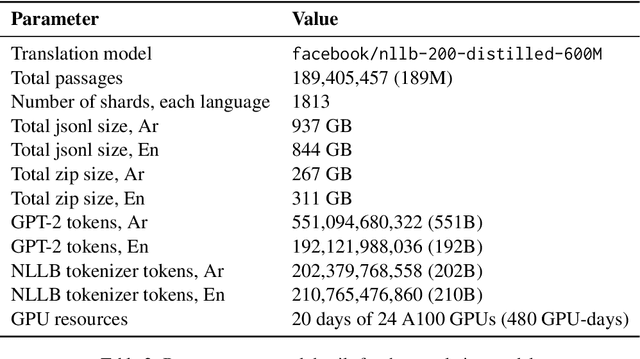
As large language models (LLMs) grow and develop, so do their data demands. This is especially true for multilingual LLMs, where the scarcity of high-quality and readily available data online has led to a multitude of synthetic dataset generation approaches. A key technique in this space is machine translation (MT), where high-quality English text is adapted to a target, comparatively low-resource language. This report introduces FineWeb-Edu-Ar, a machine-translated version of the exceedingly popular (deduplicated) FineWeb-Edu dataset from HuggingFace. To the best of our knowledge, FineWeb-Edu-Ar is the largest publicly available machine-translated Arabic dataset out there, with its size of 202B tokens of an Arabic-trained tokenizer.
Graph neural networks with configuration cross-attention for tensor compilers
May 26, 2024


With the recent popularity of neural networks comes the need for efficient serving of inference workloads. A neural network inference workload can be represented as a computational graph with nodes as operators transforming multidimensional tensors. The tensors can be transposed and/or tiled in a combinatorially large number of ways, some configurations leading to accelerated inference. We propose TGraph, a neural graph architecture that allows screening for fast configurations of the target computational graph, thus representing an artificial intelligence (AI) tensor compiler in contrast to the traditional heuristics-based compilers. The proposed solution improves mean Kendall's $\tau$ across layout collections of TpuGraphs from 29.8% of the reliable baseline to 67.4% of TGraph. We estimate the potential CO$_2$ emission reduction associated with our work to be equivalent to over 50% of the total household emissions in the areas hosting AI-oriented data centers.