 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Outlining: Heterogeneous Recursive Planning for Adaptive Long-form Writing with Language Models
Mar 11, 2025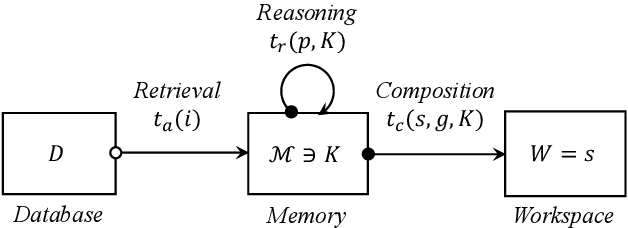
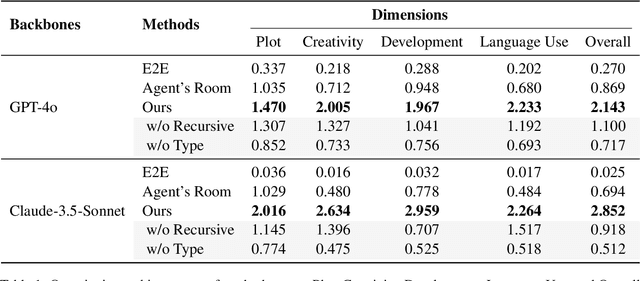
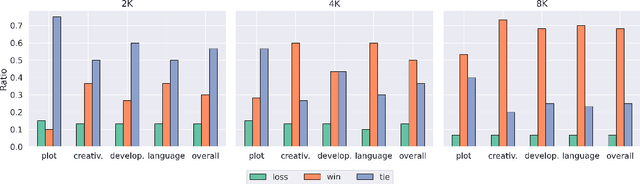
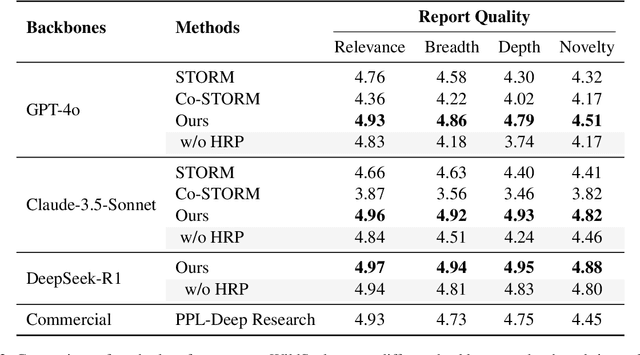
Long-form writing agents require flexible integration and interaction across information retrieval, reasoning, and composition. Current approaches rely on predetermined workflows and rigid thinking patterns to generate outlines before writing, resulting in constrained adaptability during writing. In this paper we propose a general agent framework that achieves human-like adaptive writing through recursive task decomposition and dynamic integration of three fundamental task types, i.e. retrieval, reasoning, and composition. Our methodology features: 1) a planning mechanism that interleaves recursive task decomposition and execution, eliminating artificial restrictions on writing workflow; and 2) integration of task types that facilitates heterogeneous task decomposition. Evaluations on both fiction writing and technical report generation show that our method consistently outperforms state-of-the-art approaches across all automatic evaluation metrics, which demonstrate the effectiveness and broad applicability of our proposed framework.
How to Correctly do Semantic Backpropagation on Language-based Agentic Systems
Dec 04, 2024Language-based agentic systems have shown great promise in recent years, transitioning from solving small-scale research problems to being deployed in challenging real-world tasks. However, optimizing these systems often requires substantial manual labor. Recent studies have demonstrated that these systems can be represented as computational graphs, enabling automatic optimization. Despite these advancements, most current efforts in Graph-based Agentic System Optimization (GASO) fail to properly assign feedback to the system's components given feedback on the system's output. To address this challenge, we formalize the concept of semantic backpropagation with semantic gradients -- a generalization that aligns several key optimization techniques, including reverse-mode automatic differentiation and the more recent TextGrad by exploiting the relationship among nodes with a common successor. This serves as a method for computing directional information about how changes to each component of an agentic system might improve the system's output. To use these gradients, we propose a method called semantic gradient descent which enables us to solve GASO effectively. Our results on both BIG-Bench Hard and GSM8K show that our approach outperforms existing state-of-the-art methods for solving GASO problems. A detailed ablation study on the LIAR dataset demonstrates the parsimonious nature of our method. A full copy of our implementation is publicly available at https://github.com/HishamAlyahya/semantic_backprop
Fineweb-Edu-Ar: Machine-translated Corpus to Support Arabic Small Language Models
Nov 10, 2024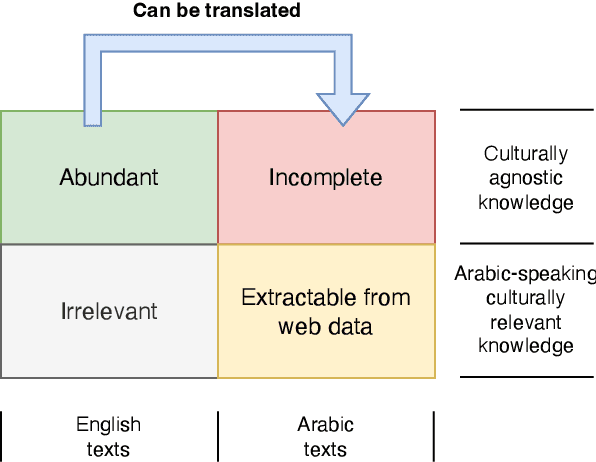
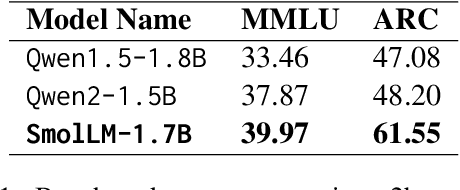
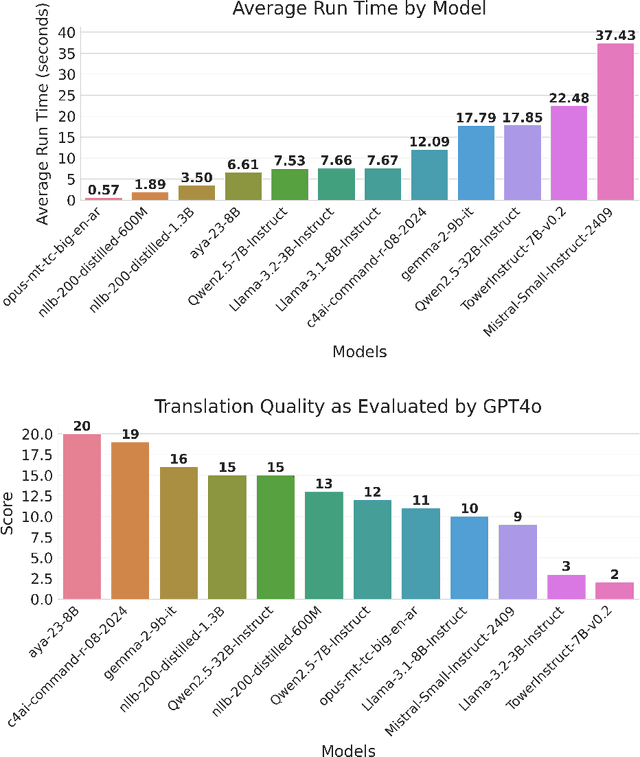
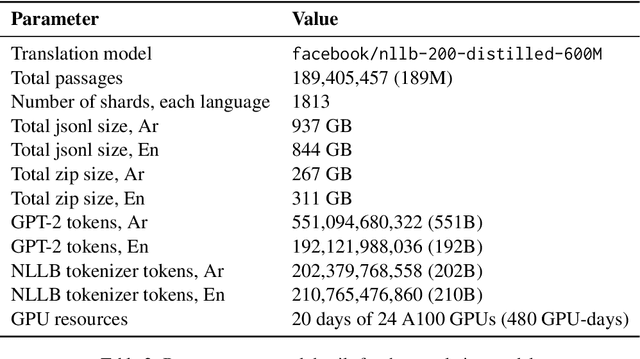
As large language models (LLMs) grow and develop, so do their data demands. This is especially true for multilingual LLMs, where the scarcity of high-quality and readily available data online has led to a multitude of synthetic dataset generation approaches. A key technique in this space is machine translation (MT), where high-quality English text is adapted to a target, comparatively low-resource language. This report introduces FineWeb-Edu-Ar, a machine-translated version of the exceedingly popular (deduplicated) FineWeb-Edu dataset from HuggingFace. To the best of our knowledge, FineWeb-Edu-Ar is the largest publicly available machine-translated Arabic dataset out there, with its size of 202B tokens of an Arabic-trained tokenizer.
Agent-as-a-Judge: Evaluate Agents with Agents
Oct 14, 2024



Contemporary evaluation techniques are inadequate for agentic systems. These approaches either focus exclusively on final outcomes -- ignoring the step-by-step nature of agentic systems, or require excessive manual labour. To address this, we introduce the Agent-as-a-Judge framework, wherein agentic systems are used to evaluate agentic systems. This is an organic extension of the LLM-as-a-Judge framework, incorporating agentic features that enable intermediate feedback for the entire task-solving process. We apply the Agent-as-a-Judge to the task of code generation. To overcome issues with existing benchmarks and provide a proof-of-concept testbed for Agent-as-a-Judge, we present DevAI, a new benchmark of 55 realistic automated AI development tasks. It includes rich manual annotations, like a total of 365 hierarchical user requirements. We benchmark three of the popular agentic systems using Agent-as-a-Judge and find it dramatically outperforms LLM-as-a-Judge and is as reliable as our human evaluation baseline. Altogether, we believe that Agent-as-a-Judge marks a concrete step forward for modern agentic systems -- by providing rich and reliable reward signals necessary for dynamic and scalable self-improvement.
Graph neural networks with configuration cross-attention for tensor compilers
May 26, 2024

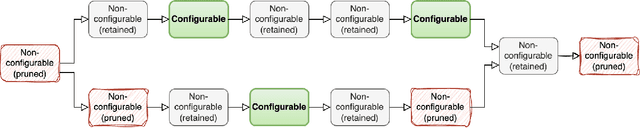

With the recent popularity of neural networks comes the need for efficient serving of inference workloads. A neural network inference workload can be represented as a computational graph with nodes as operators transforming multidimensional tensors. The tensors can be transposed and/or tiled in a combinatorially large number of ways, some configurations leading to accelerated inference. We propose TGraph, a neural graph architecture that allows screening for fast configurations of the target computational graph, thus representing an artificial intelligence (AI) tensor compiler in contrast to the traditional heuristics-based compilers. The proposed solution improves mean Kendall's $\tau$ across layout collections of TpuGraphs from 29.8% of the reliable baseline to 67.4% of TGraph. We estimate the potential CO$_2$ emission reduction associated with our work to be equivalent to over 50% of the total household emissions in the areas hosting AI-oriented data centers.
Language Agents as Optimizable Graphs
Feb 27, 2024



Various human-designed prompt engineering techniques have been proposed to improve problem solvers based on Large Language Models (LLMs), yielding many disparate code bases. We unify these approaches by describing LLM-based agents as computational graphs. The nodes implement functions to process multimodal data or query LLMs, and the edges describe the information flow between operations. Graphs can be recursively combined into larger composite graphs representing hierarchies of inter-agent collaboration (where edges connect operations of different agents). Our novel automatic graph optimizers (1) refine node-level LLM prompts (node optimization) and (2) improve agent orchestration by changing graph connectivity (edge optimization). Experiments demonstrate that our framework can be used to efficiently develop, integrate, and automatically improve various LLM agents. The code can be found at https://github.com/metauto-ai/gptswarm.
CAMEL: Communicative Agents for "Mind" Exploration of Large Scale Language Model Society
Mar 31, 2023The rapid advancement of conversational and chat-based language models has led to remarkable progress in complex task-solving. However, their success heavily relies on human input to guide the conversation, which can be challenging and time-consuming. This paper explores the potential of building scalable techniques to facilitate autonomous cooperation among communicative agents and provide insight into their "cognitive" processes. To address the challenges of achieving autonomous cooperation, we propose a novel communicative agent framework named role-playing. Our approach involves using inception prompting to guide chat agents toward task completion while maintaining consistency with human intentions. We showcase how role-playing can be used to generate conversational data for studying the behaviors and capabilities of chat agents, providing a valuable resource for investigating conversational language models. Our contributions include introducing a novel communicative agent framework, offering a scalable approach for studying the cooperative behaviors and capabilities of multi-agent systems, and open-sourcing our library to support research on communicative agents and beyond. The GitHub repository of this project is made publicly available on: https://github.com/lightaime/camel.