 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePDR: A Plug-and-Play Positional Decay Framework for LLM Pre-training Data Detection
Jan 11, 2026Detecting pre-training data in Large Language Models (LLMs) is crucial for auditing data privacy and copyright compliance, yet it remains challenging in black-box, zero-shot settings where computational resources and training data are scarce. While existing likelihood-based methods have shown promise, they typically aggregate token-level scores using uniform weights, thereby neglecting the inherent information-theoretic dynamics of autoregressive generation. In this paper, we hypothesize and empirically validate that memorization signals are heavily skewed towards the high-entropy initial tokens, where model uncertainty is highest, and decay as context accumulates. To leverage this linguistic property, we introduce Positional Decay Reweighting (PDR), a training-free and plug-and-play framework. PDR explicitly reweights token-level scores to amplify distinct signals from early positions while suppressing noise from later ones. Extensive experiments show that PDR acts as a robust prior and can usually enhance a wide range of advanced methods across multiple benchmarks.
Huxley-Gödel Machine: Human-Level Coding Agent Development by an Approximation of the Optimal Self-Improving Machine
Oct 24, 2025Recent studies operationalize self-improvement through coding agents that edit their own codebases. They grow a tree of self-modifications through expansion strategies that favor higher software engineering benchmark performance, assuming that this implies more promising subsequent self-modifications. However, we identify a mismatch between the agent's self-improvement potential (metaproductivity) and its coding benchmark performance, namely the Metaproductivity-Performance Mismatch. Inspired by Huxley's concept of clade, we propose a metric ($\mathrm{CMP}$) that aggregates the benchmark performances of the descendants of an agent as an indicator of its potential for self-improvement. We show that, in our self-improving coding agent development setting, access to the true $\mathrm{CMP}$ is sufficient to simulate how the G\"odel Machine would behave under certain assumptions. We introduce the Huxley-G\"odel Machine (HGM), which, by estimating $\mathrm{CMP}$ and using it as guidance, searches the tree of self-modifications. On SWE-bench Verified and Polyglot, HGM outperforms prior self-improving coding agent development methods while using less wall-clock time. Last but not least, HGM demonstrates strong transfer to other coding datasets and large language models. The agent optimized by HGM on SWE-bench Verified with GPT-5-mini and evaluated on SWE-bench Lite with GPT-5 achieves human-level performance, matching the best officially checked results of human-engineered coding agents. Our code is available at https://github.com/metauto-ai/HGM.
Beyond Outlining: Heterogeneous Recursive Planning for Adaptive Long-form Writing with Language Models
Mar 11, 2025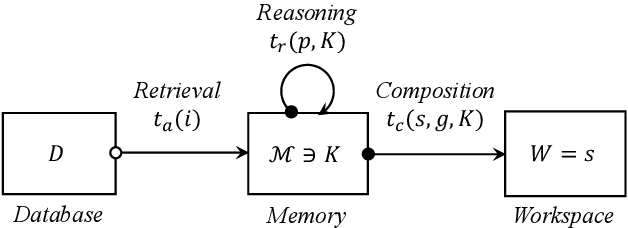
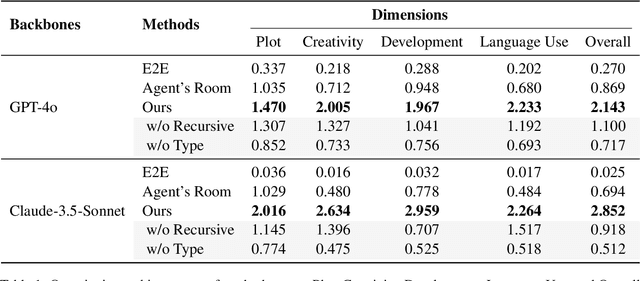
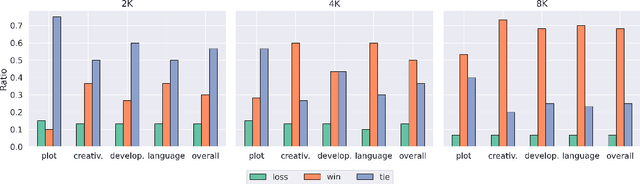
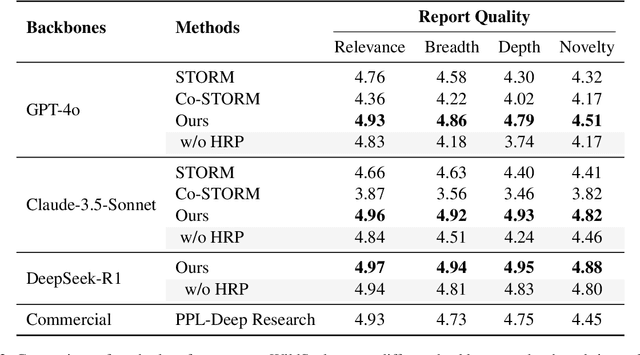
Long-form writing agents require flexible integration and interaction across information retrieval, reasoning, and composition. Current approaches rely on predetermined workflows and rigid thinking patterns to generate outlines before writing, resulting in constrained adaptability during writing. In this paper we propose a general agent framework that achieves human-like adaptive writing through recursive task decomposition and dynamic integration of three fundamental task types, i.e. retrieval, reasoning, and composition. Our methodology features: 1) a planning mechanism that interleaves recursive task decomposition and execution, eliminating artificial restrictions on writing workflow; and 2) integration of task types that facilitates heterogeneous task decomposition. Evaluations on both fiction writing and technical report generation show that our method consistently outperforms state-of-the-art approaches across all automatic evaluation metrics, which demonstrate the effectiveness and broad applicability of our proposed framework.
SepLLM: Accelerate Large Language Models by Compressing One Segment into One Separator
Dec 16, 2024



Large Language Models (LLMs) have exhibited exceptional performance across a spectrum of natural language processing tasks. However, their substantial sizes pose considerable challenges, particularly in computational demands and inference speed, due to their quadratic complexity. In this work, we have identified a key pattern: certain seemingly meaningless special tokens (i.e., separators) contribute disproportionately to attention scores compared to semantically meaningful tokens. This observation suggests that information of the segments between these separator tokens can be effectively condensed into the separator tokens themselves without significant information loss. Guided by this insight, we introduce SepLLM, a plug-and-play framework that accelerates inference by compressing these segments and eliminating redundant tokens. Additionally, we implement efficient kernels for training acceleration. Experimental results across training-free, training-from-scratch, and post-training settings demonstrate SepLLM's effectiveness. Notably, using the Llama-3-8B backbone, SepLLM achieves over 50% reduction in KV cache on the GSM8K-CoT benchmark while maintaining comparable performance. Furthermore, in streaming settings, SepLLM effectively processes sequences of up to 4 million tokens or more while maintaining consistent language modeling capabilities.
Efficient Multi-modal Large Language Models via Visual Token Grouping
Nov 26, 2024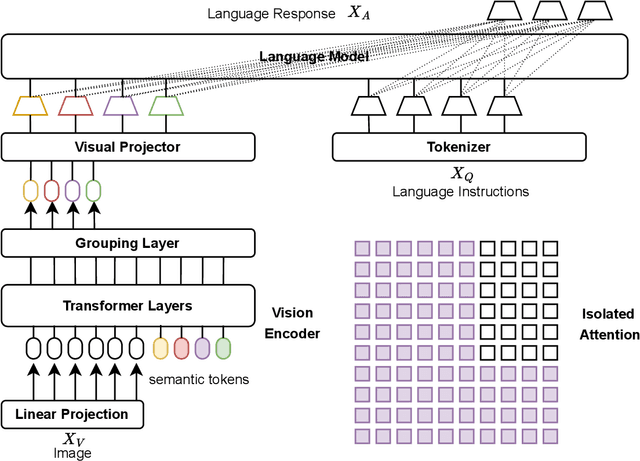
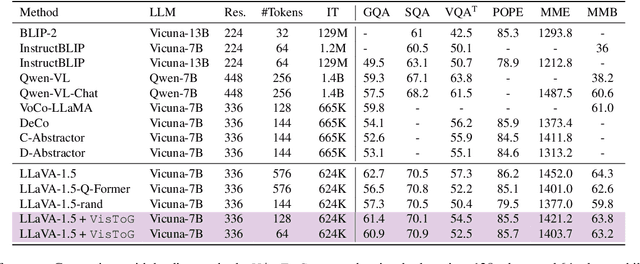
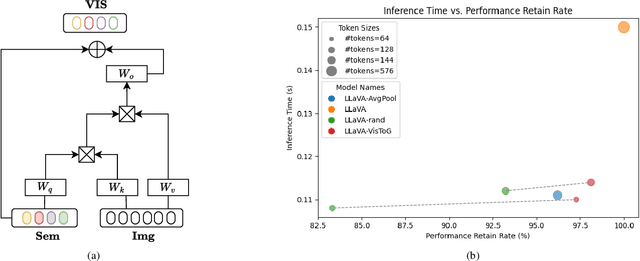
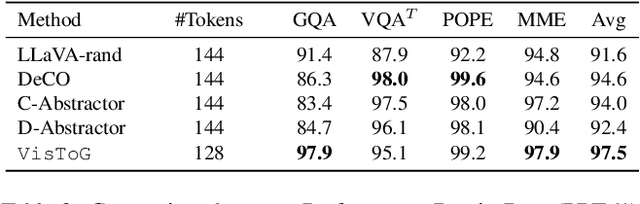
The development of Multi-modal Large Language Models (MLLMs) enhances Large Language Models (LLMs) with the ability to perceive data formats beyond text, significantly advancing a range of downstream applications, such as visual question answering and image captioning. However, the substantial computational costs associated with processing high-resolution images and videos pose a barrier to their broader adoption. To address this challenge, compressing vision tokens in MLLMs has emerged as a promising approach to reduce inference costs. While existing methods conduct token reduction in the feature alignment phase. In this paper, we introduce VisToG, a novel grouping mechanism that leverages the capabilities of pre-trained vision encoders to group similar image segments without the need for segmentation masks. Specifically, we concatenate semantic tokens to represent image semantic segments after the linear projection layer before feeding into the vision encoder. Besides, with the isolated attention we adopt, VisToG can identify and eliminate redundant visual tokens utilizing the prior knowledge in the pre-trained vision encoder, which effectively reduces computational demands. Extensive experiments demonstrate the effectiveness of VisToG, maintaining 98.1% of the original performance while achieving a reduction of over 27\% inference time.
From Handcrafted Features to LLMs: A Brief Survey for Machine Translation Quality Estimation
Mar 21, 2024Machine Translation Quality Estimation (MTQE) is the task of estimating the quality of machine-translated text in real time without the need for reference translations, which is of great importance for the development of MT. After two decades of evolution, QE has yielded a wealth of results. This article provides a comprehensive overview of QE datasets, annotation methods, shared tasks, methodologies, challenges, and future research directions. It begins with an introduction to the background and significance of QE, followed by an explanation of the concepts and evaluation metrics for word-level QE, sentence-level QE, document-level QE, and explainable QE. The paper categorizes the methods developed throughout the history of QE into those based on handcrafted features, deep learning, and Large Language Models (LLMs), with a further division of deep learning-based methods into classic deep learning and those incorporating pre-trained language models (LMs). Additionally, the article details the advantages and limitations of each method and offers a straightforward comparison of different approaches. Finally, the paper discusses the current challenges in QE research and provides an outlook on future research directions.
Explore and Exploit the Diverse Knowledge in Model Zoo for Domain Generalization
Jun 05, 2023



The proliferation of pretrained models, as a result of advancements in pretraining techniques, has led to the emergence of a vast zoo of publicly available models. Effectively utilizing these resources to obtain models with robust out-of-distribution generalization capabilities for downstream tasks has become a crucial area of research. Previous research has primarily focused on identifying the most powerful models within the model zoo, neglecting to fully leverage the diverse inductive biases contained within. This paper argues that the knowledge contained in weaker models is valuable and presents a method for leveraging the diversity within the model zoo to improve out-of-distribution generalization capabilities. Specifically, we investigate the behaviors of various pretrained models across different domains of downstream tasks by characterizing the variations in their encoded representations in terms of two dimensions: diversity shift and correlation shift. This characterization enables us to propose a new algorithm for integrating diverse pretrained models, not limited to the strongest models, in order to achieve enhanced out-of-distribution generalization performance. Our proposed method demonstrates state-of-the-art empirical results on a variety of datasets, thus validating the benefits of utilizing diverse knowledge.
When Does Group Invariant Learning Survive Spurious Correlations?
Jun 29, 2022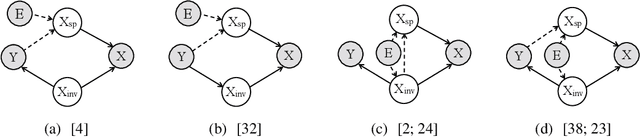
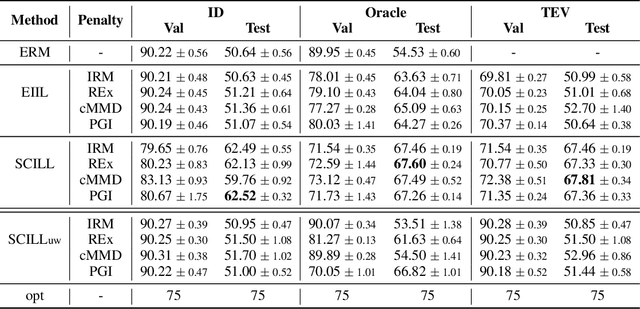
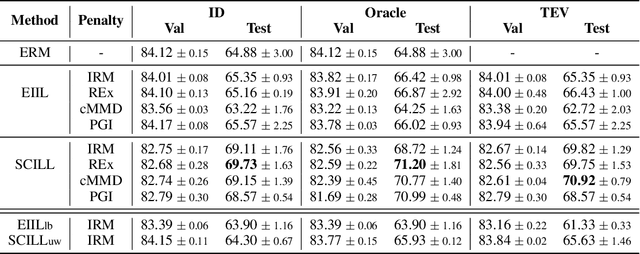
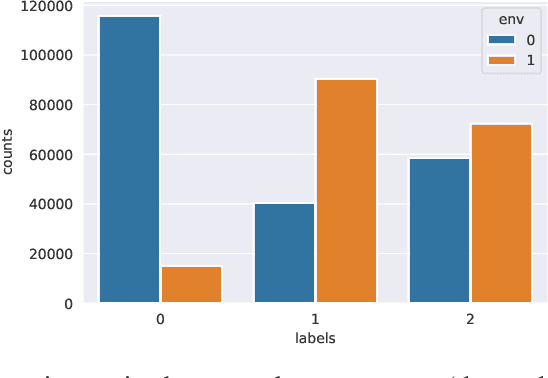
By inferring latent groups in the training data, recent works introduce invariant learning to the case where environment annotations are unavailable. Typically, learning group invariance under a majority/minority split is empirically shown to be effective in improving out-of-distribution generalization on many datasets. However, theoretical guarantee for these methods on learning invariant mechanisms is lacking. In this paper, we reveal the insufficiency of existing group invariant learning methods in preventing classifiers from depending on spurious correlations in the training set. Specifically, we propose two criteria on judging such sufficiency. Theoretically and empirically, we show that existing methods can violate both criteria and thus fail in generalizing to spurious correlation shifts. Motivated by this, we design a new group invariant learning method, which constructs groups with statistical independence tests, and reweights samples by group label proportion to meet the criteria. Experiments on both synthetic and real data demonstrate that the new method significantly outperforms existing group invariant learning methods in generalizing to spurious correlation shifts.
Diformer: Directional Transformer for Neural Machine Translation
Dec 31, 2021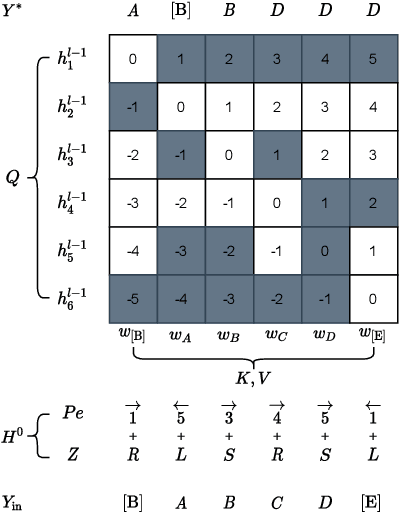
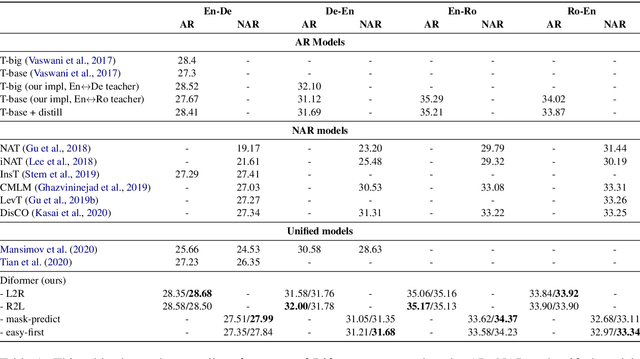
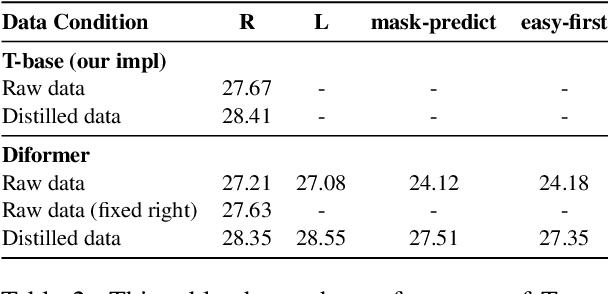
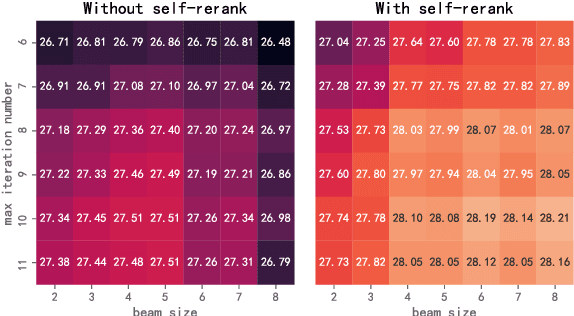
Autoregressive (AR) and Non-autoregressive (NAR) models have their own superiority on the performance and latency, combining them into one model may take advantage of both. Current combination frameworks focus more on the integration of multiple decoding paradigms with a unified generative model, e.g. Masked Language Model. However, the generalization can be harmful to the performance due to the gap between training objective and inference. In this paper, we aim to close the gap by preserving the original objective of AR and NAR under a unified framework. Specifically, we propose the Directional Transformer (Diformer) by jointly modelling AR and NAR into three generation directions (left-to-right, right-to-left and straight) with a newly introduced direction variable, which works by controlling the prediction of each token to have specific dependencies under that direction. The unification achieved by direction successfully preserves the original dependency assumption used in AR and NAR, retaining both generalization and performance. Experiments on 4 WMT benchmarks demonstrate that Diformer outperforms current united-modelling works with more than 1.5 BLEU points for both AR and NAR decoding, and is also competitive to the state-of-the-art independent AR and NAR models.
Joint-training on Symbiosis Networks for Deep Nueral Machine Translation models
Dec 22, 2021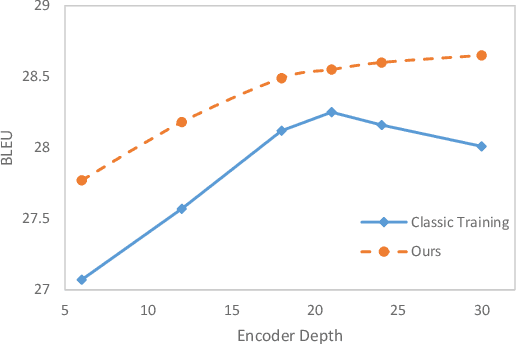
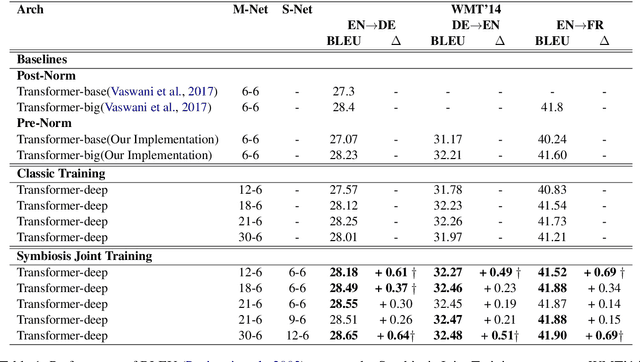
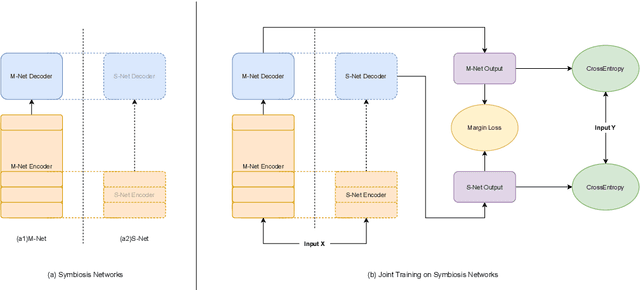
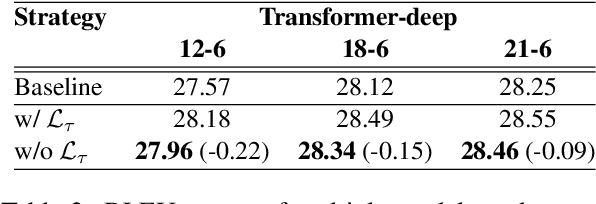
Deep encoders have been proven to be effective in improving neural machine translation (NMT) systems, but it reaches the upper bound of translation quality when the number of encoder layers exceeds 18. Worse still, deeper networks consume a lot of memory, making it impossible to train efficiently. In this paper, we present Symbiosis Networks, which include a full network as the Symbiosis Main Network (M-Net) and another shared sub-network with the same structure but less layers as the Symbiotic Sub Network (S-Net). We adopt Symbiosis Networks on Transformer-deep (m-n) architecture and define a particular regularization loss $\mathcal{L}_{\tau}$ between the M-Net and S-Net in NMT. We apply joint-training on the Symbiosis Networks and aim to improve the M-Net performance. Our proposed training strategy improves Transformer-deep (12-6) by 0.61, 0.49 and 0.69 BLEU over the baselines under classic training on WMT'14 EN->DE, DE->EN and EN->FR tasks. Furthermore, our Transformer-deep (12-6) even outperforms classic Transformer-deep (18-6).