 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegionRAG: Region-level Retrieval-Augumented Generation for Visually-Rich Documents
Oct 31, 2025

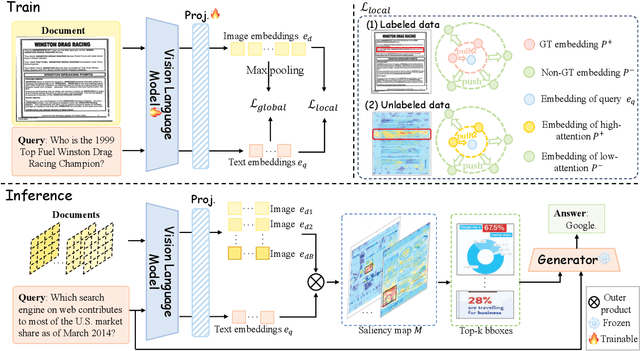

Multi-modal Retrieval-Augmented Generation (RAG) has become a critical method for empowering LLMs by leveraging candidate visual documents. However, current methods consider the entire document as the basic retrieval unit, introducing substantial irrelevant visual content in two ways: 1) Relevant documents often contain large regions unrelated to the query, diluting the focus on salient information; 2) Retrieving multiple documents to increase recall further introduces redundant and irrelevant documents. These redundant contexts distract the model's attention and further degrade the performance. To address this challenge, we propose \modelname, a novel framework that shifts the retrieval paradigm from the document level to the region level. During training, we design a hybrid supervision strategy from both labeled data and unlabeled data to pinpoint relevant patches. During inference, we propose a dynamic pipeline that intelligently groups salient patches into complete semantic regions. By delegating the task of identifying relevant regions to the retriever, \modelname enables the generator to focus solely on concise visual content relevant to queries, improving both efficiency and accuracy. Experiments on six benchmarks demonstrate that RegionRAG achieves state-of-the-art performance. Improves retrieval accuracy by 10.02\% in R@1 on average and increases question answering accuracy by 3.56\% while using only 71.42\% visual tokens compared to prior methods. The code will be available at https://github.com/Aeryn666/RegionRAG.
Why Not Transform Chat Large Language Models to Non-English?
May 22, 2024
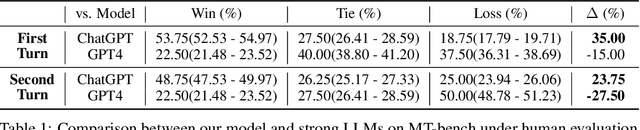


The scarcity of non-English data limits the development of non-English large language models (LLMs). Transforming English-centric LLMs to non-English has been identified as an effective and resource-efficient method. Previous works start from base LLMs and perform knowledge distillation (KD) with data generated by stronger LLMs, e.g. GPT-4. Compared to base LLMs, chat LLMs are further optimized for advanced abilities, e.g. multi-turn conversation and human preference alignment, and thus more powerful in both helpfulness and safety. However, transforming a chat LLM involves two critical issues: (1) How can we effectively transfer advanced abilities without their supervised data? (2) How can we prevent the original knowledge from catastrophic forgetting during transformation? We target these issues by introducing a simple framework called TransLLM. For the first issue, TransLLM divides the transfer problem into some common sub-tasks with the translation chain-of-thought, which uses the translation as the bridge between English and non-English step-by-step. We further enhance the performance of sub-tasks with publicly available data. For the second issue, we propose a method comprising two synergistic components: low-rank adaptation for training to maintain the original LLM parameters, and recovery KD, which utilizes data generated by the chat LLM itself to recover the original knowledge from the frozen parameters. In the experiments, we transform the LLaMA-2-chat-7B to the Thai language. Our method, using only single-turn data, outperforms strong baselines and ChatGPT on multi-turn benchmark MT-bench. Furthermore, our method, without safety data, rejects more harmful queries of safety benchmark AdvBench than both ChatGPT and GPT-4.
UCorrect: An Unsupervised Framework for Automatic Speech Recognition Error Correction
Jan 11, 2024Error correction techniques have been used to refine the output sentences from automatic speech recognition (ASR) models and achieve a lower word error rate (WER). Previous works usually adopt end-to-end models and has strong dependency on Pseudo Paired Data and Original Paired Data. But when only pre-training on Pseudo Paired Data, previous models have negative effect on correction. While fine-tuning on Original Paired Data, the source side data must be transcribed by a well-trained ASR model, which takes a lot of time and not universal. In this paper, we propose UCorrect, an unsupervised Detector-Generator-Selector framework for ASR Error Correction. UCorrect has no dependency on the training data mentioned before. The whole procedure is first to detect whether the character is erroneous, then to generate some candidate characters and finally to select the most confident one to replace the error character. Experiments on the public AISHELL-1 dataset and WenetSpeech dataset show the effectiveness of UCorrect for ASR error correction: 1) it achieves significant WER reduction, achieves 6.83\% even without fine-tuning and 14.29\% after fine-tuning; 2) it outperforms the popular NAR correction models by a large margin with a competitive low latency; and 3) it is an universal method, as it reduces all WERs of the ASR model with different decoding strategies and reduces all WERs of ASR models trained on different scale datasets.
CB-Whisper: Contextual Biasing Whisper using TTS-based Keyword Spotting
Sep 18, 2023



End-to-end automatic speech recognition (ASR) systems often struggle to recognize rare name entities, such as personal names, organizations, or technical terms that are not frequently encountered in the training data. This paper presents Contextual Biasing Whisper (CB-Whisper), a novel ASR system based on OpenAI's Whisper model that performs keyword-spotting (KWS) before the decoder. The KWS module leverages text-to-speech (TTS) techniques and a convolutional neural network (CNN) classifier to match the features between the entities and the utterances. Experiments demonstrate that by incorporating predicted entities into a carefully designed spoken form prompt, the mixed-error-rate (MER) and entity recall of the Whisper model is significantly improved on three internal datasets and two open-sourced datasets that cover English-only, Chinese-only, and code-switching scenarios.
KG-BERTScore: Incorporating Knowledge Graph into BERTScore for Reference-Free Machine Translation Evaluation
Jan 30, 2023BERTScore is an effective and robust automatic metric for referencebased machine translation evaluation. In this paper, we incorporate multilingual knowledge graph into BERTScore and propose a metric named KG-BERTScore, which linearly combines the results of BERTScore and bilingual named entity matching for reference-free machine translation evaluation. From the experimental results on WMT19 QE as a metric without references shared tasks, our metric KG-BERTScore gets higher overall correlation with human judgements than the current state-of-the-art metrics for reference-free machine translation evaluation.1 Moreover, the pre-trained multilingual model used by KG-BERTScore and the parameter for linear combination are also studied in this paper.
Diformer: Directional Transformer for Neural Machine Translation
Dec 31, 2021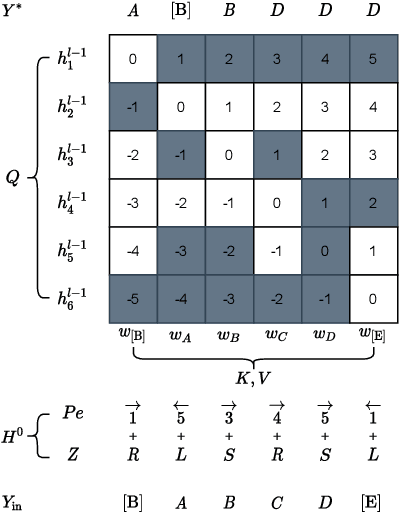
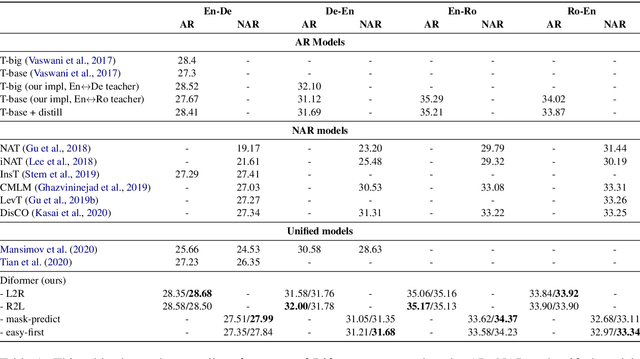
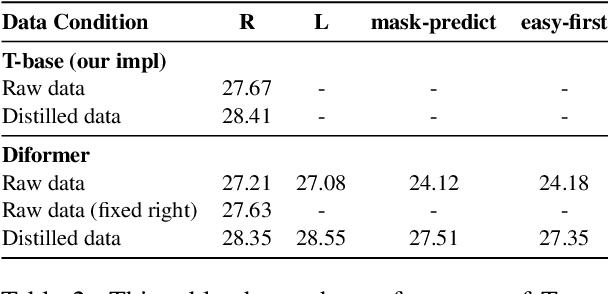
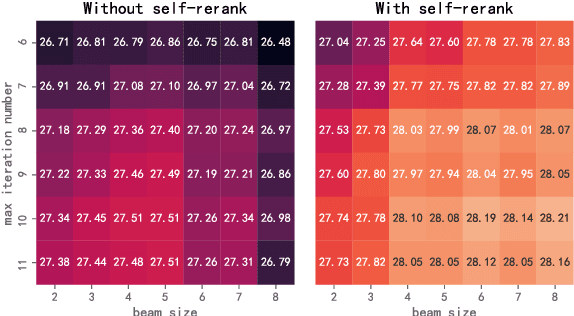
Autoregressive (AR) and Non-autoregressive (NAR) models have their own superiority on the performance and latency, combining them into one model may take advantage of both. Current combination frameworks focus more on the integration of multiple decoding paradigms with a unified generative model, e.g. Masked Language Model. However, the generalization can be harmful to the performance due to the gap between training objective and inference. In this paper, we aim to close the gap by preserving the original objective of AR and NAR under a unified framework. Specifically, we propose the Directional Transformer (Diformer) by jointly modelling AR and NAR into three generation directions (left-to-right, right-to-left and straight) with a newly introduced direction variable, which works by controlling the prediction of each token to have specific dependencies under that direction. The unification achieved by direction successfully preserves the original dependency assumption used in AR and NAR, retaining both generalization and performance. Experiments on 4 WMT benchmarks demonstrate that Diformer outperforms current united-modelling works with more than 1.5 BLEU points for both AR and NAR decoding, and is also competitive to the state-of-the-art independent AR and NAR models.