 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUCorrect: An Unsupervised Framework for Automatic Speech Recognition Error Correction
Jan 11, 2024Error correction techniques have been used to refine the output sentences from automatic speech recognition (ASR) models and achieve a lower word error rate (WER). Previous works usually adopt end-to-end models and has strong dependency on Pseudo Paired Data and Original Paired Data. But when only pre-training on Pseudo Paired Data, previous models have negative effect on correction. While fine-tuning on Original Paired Data, the source side data must be transcribed by a well-trained ASR model, which takes a lot of time and not universal. In this paper, we propose UCorrect, an unsupervised Detector-Generator-Selector framework for ASR Error Correction. UCorrect has no dependency on the training data mentioned before. The whole procedure is first to detect whether the character is erroneous, then to generate some candidate characters and finally to select the most confident one to replace the error character. Experiments on the public AISHELL-1 dataset and WenetSpeech dataset show the effectiveness of UCorrect for ASR error correction: 1) it achieves significant WER reduction, achieves 6.83\% even without fine-tuning and 14.29\% after fine-tuning; 2) it outperforms the popular NAR correction models by a large margin with a competitive low latency; and 3) it is an universal method, as it reduces all WERs of the ASR model with different decoding strategies and reduces all WERs of ASR models trained on different scale datasets.
Text Style Transfer Back-Translation
Jun 02, 2023Back Translation (BT) is widely used in the field of machine translation, as it has been proved effective for enhancing translation quality. However, BT mainly improves the translation of inputs that share a similar style (to be more specific, translation-like inputs), since the source side of BT data is machine-translated. For natural inputs, BT brings only slight improvements and sometimes even adverse effects. To address this issue, we propose Text Style Transfer Back Translation (TST BT), which uses a style transfer model to modify the source side of BT data. By making the style of source-side text more natural, we aim to improve the translation of natural inputs. Our experiments on various language pairs, including both high-resource and low-resource ones, demonstrate that TST BT significantly improves translation performance against popular BT benchmarks. In addition, TST BT is proved to be effective in domain adaptation so this strategy can be regarded as a general data augmentation method. Our training code and text style transfer model are open-sourced.
Joint-training on Symbiosis Networks for Deep Nueral Machine Translation models
Dec 22, 2021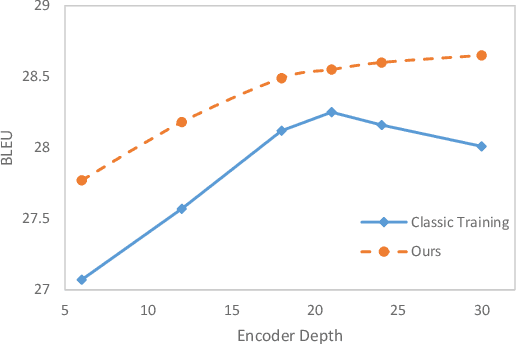
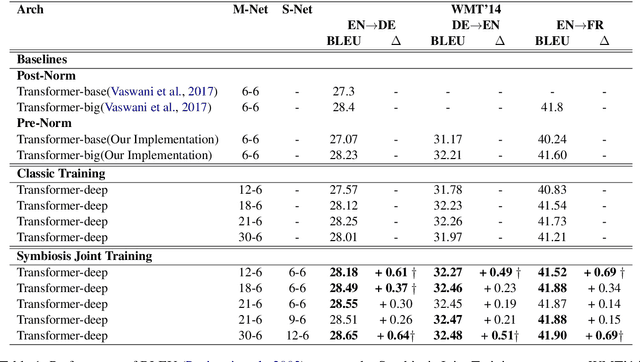
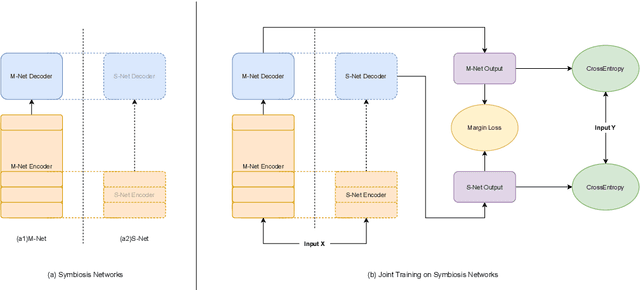
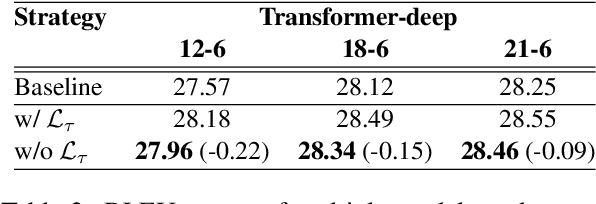
Deep encoders have been proven to be effective in improving neural machine translation (NMT) systems, but it reaches the upper bound of translation quality when the number of encoder layers exceeds 18. Worse still, deeper networks consume a lot of memory, making it impossible to train efficiently. In this paper, we present Symbiosis Networks, which include a full network as the Symbiosis Main Network (M-Net) and another shared sub-network with the same structure but less layers as the Symbiotic Sub Network (S-Net). We adopt Symbiosis Networks on Transformer-deep (m-n) architecture and define a particular regularization loss $\mathcal{L}_{\tau}$ between the M-Net and S-Net in NMT. We apply joint-training on the Symbiosis Networks and aim to improve the M-Net performance. Our proposed training strategy improves Transformer-deep (12-6) by 0.61, 0.49 and 0.69 BLEU over the baselines under classic training on WMT'14 EN->DE, DE->EN and EN->FR tasks. Furthermore, our Transformer-deep (12-6) even outperforms classic Transformer-deep (18-6).
Self-Distillation Mixup Training for Non-autoregressive Neural Machine Translation
Dec 22, 2021

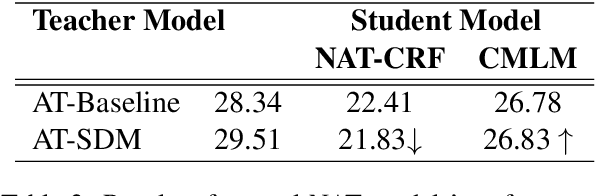
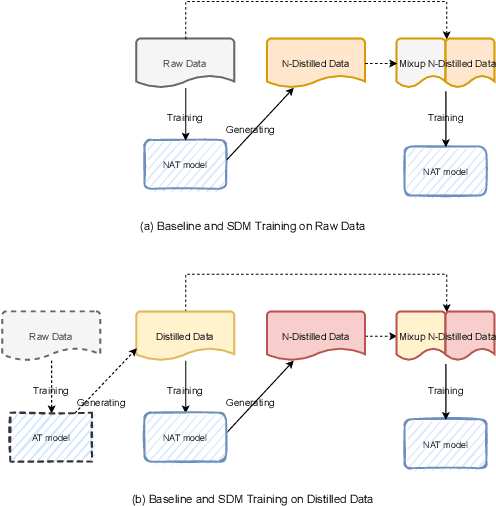
Recently, non-autoregressive (NAT) models predict outputs in parallel, achieving substantial improvements in generation speed compared to autoregressive (AT) models. While performing worse on raw data, most NAT models are trained as student models on distilled data generated by AT teacher models, which is known as sequence-level Knowledge Distillation. An effective training strategy to improve the performance of AT models is Self-Distillation Mixup (SDM) Training, which pre-trains a model on raw data, generates distilled data by the pre-trained model itself and finally re-trains a model on the combination of raw data and distilled data. In this work, we aim to view SDM for NAT models, but find directly adopting SDM to NAT models gains no improvements in terms of translation quality. Through careful analysis, we observe the invalidation is correlated to Modeling Diversity and Confirmation Bias between the AT teacher model and the NAT student models. Based on these findings, we propose an enhanced strategy named SDMRT by adding two stages to classic SDM: one is Pre-Rerank on self-distilled data, the other is Fine-Tune on Filtered teacher-distilled data. Our results outperform baselines by 0.6 to 1.2 BLEU on multiple NAT models. As another bonus, for Iterative Refinement NAT models, our methods can outperform baselines within half iteration number, which means 2X acceleration.