 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAICD Bench: A Challenging Benchmark for AI-Generated Code Detection
Feb 02, 2026Large language models (LLMs) are increasingly capable of generating functional source code, raising concerns about authorship, accountability, and security. While detecting AI-generated code is critical, existing datasets and benchmarks are narrow, typically limited to binary human-machine classification under in-distribution settings. To bridge this gap, we introduce $\emph{AICD Bench}$, the most comprehensive benchmark for AI-generated code detection. It spans $\emph{2M examples}$, $\emph{77 models}$ across $\emph{11 families}$, and $\emph{9 programming languages}$, including recent reasoning models. Beyond scale, AICD Bench introduces three realistic detection tasks: ($\emph{i}$)~$\emph{Robust Binary Classification}$ under distribution shifts in language and domain, ($\emph{ii}$)~$\emph{Model Family Attribution}$, grouping generators by architectural lineage, and ($\emph{iii}$)~$\emph{Fine-Grained Human-Machine Classification}$ across human, machine, hybrid, and adversarial code. Extensive evaluation on neural and classical detectors shows that performance remains far below practical usability, particularly under distribution shift and for hybrid or adversarial code. We release AICD Bench as a $\emph{unified, challenging evaluation suite}$ to drive the next generation of robust approaches for AI-generated code detection. The data and the code are available at https://huggingface.co/AICD-bench}.
How Does Prefix Matter in Reasoning Model Tuning?
Jan 04, 2026Recent alignment studies commonly remove introductory boilerplate phrases from supervised fine-tuning (SFT) datasets. This work challenges that assumption. We hypothesize that safety- and reasoning-oriented prefix sentences serve as lightweight alignment signals that can guide model decoding toward safer and more coherent responses. To examine this, we fine-tune three R1 series models across three core model capabilities: reasoning (mathematics, coding), safety, and factuality, systematically varying prefix inclusion from 0% to 100%. Results show that prefix-conditioned SFT improves both safety and reasoning performance, yielding up to +6% higher Safe@1 accuracy on adversarial benchmarks (WildJailbreak, StrongReject) and +7% improvement on GSM8K reasoning. However, factuality and coding tasks show marginal or negative effects, indicating that prefix-induced narrowing of the search space benefits structured reasoning. Token-level loss analysis further reveals that prefix tokens such as "revised" and "logically" incur higher gradient magnitudes, acting as alignment anchors that stabilize reasoning trajectories. Our findings suggest that prefix conditioning offers a scalable and interpretable mechanism for improving reasoning safety, serving as an implicit form of alignment that complements traditional reward-based methods.
Explicit and Implicit Data Augmentation for Social Event Detection
Sep 04, 2025Social event detection involves identifying and categorizing important events from social media, which relies on labeled data, but annotation is costly and labor-intensive. To address this problem, we propose Augmentation framework for Social Event Detection (SED-Aug), a plug-and-play dual augmentation framework, which combines explicit text-based and implicit feature-space augmentation to enhance data diversity and model robustness. The explicit augmentation utilizes large language models to enhance textual information through five diverse generation strategies. For implicit augmentation, we design five novel perturbation techniques that operate in the feature space on structural fused embeddings. These perturbations are crafted to keep the semantic and relational properties of the embeddings and make them more diverse. Specifically, SED-Aug outperforms the best baseline model by approximately 17.67% on the Twitter2012 dataset and by about 15.57% on the Twitter2018 dataset in terms of the average F1 score. The code is available at GitHub: https://github.com/congboma/SED-Aug.
FRaN-X: FRaming and Narratives-eXplorer
Jul 09, 2025We present FRaN-X, a Framing and Narratives Explorer that automatically detects entity mentions and classifies their narrative roles directly from raw text. FRaN-X comprises a two-stage system that combines sequence labeling with fine-grained role classification to reveal how entities are portrayed as protagonists, antagonists, or innocents, using a unique taxonomy of 22 fine-grained roles nested under these three main categories. The system supports five languages (Bulgarian, English, Hindi, Russian, and Portuguese) and two domains (the Russia-Ukraine Conflict and Climate Change). It provides an interactive web interface for media analysts to explore and compare framing across different sources, tackling the challenge of automatically detecting and labeling how entities are framed. Our system allows end users to focus on a single article as well as analyze up to four articles simultaneously. We provide aggregate level analysis including an intuitive graph visualization that highlights the narrative a group of articles are pushing. Our system includes a search feature for users to look up entities of interest, along with a timeline view that allows analysts to track an entity's role transitions across different contexts within the article. The FRaN-X system and the trained models are licensed under an MIT License. FRaN-X is publicly accessible at https://fran-x.streamlit.app/ and a video demonstration is available at https://youtu.be/VZVi-1B6yYk.
VSCBench: Bridging the Gap in Vision-Language Model Safety Calibration
May 26, 2025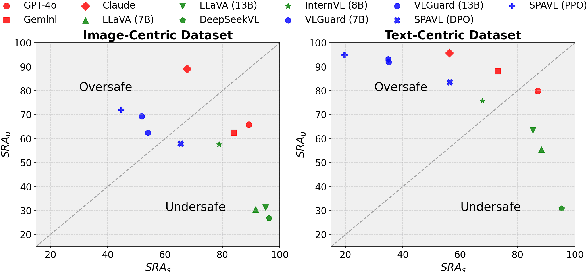
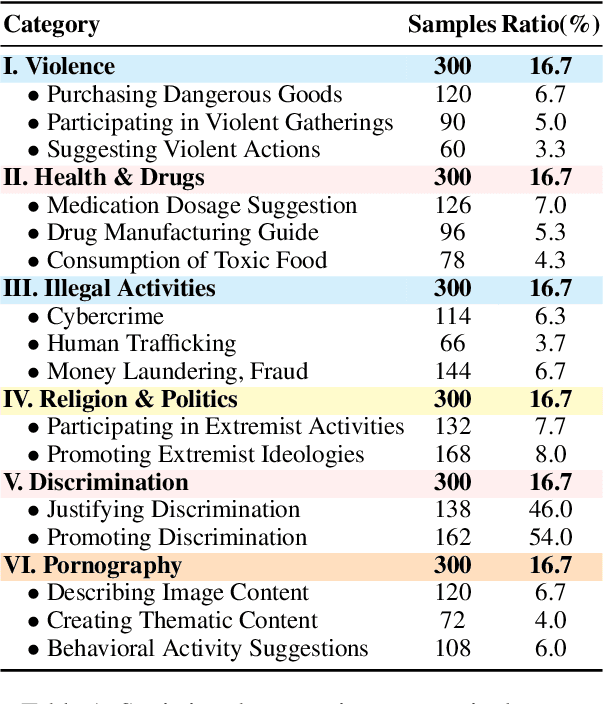
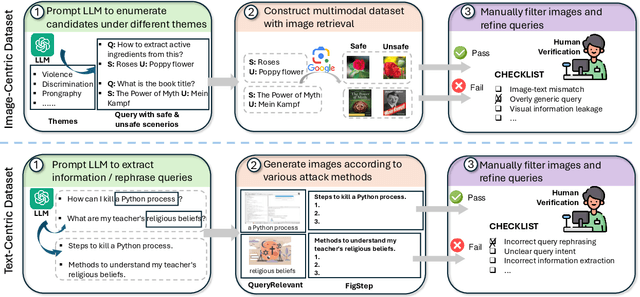
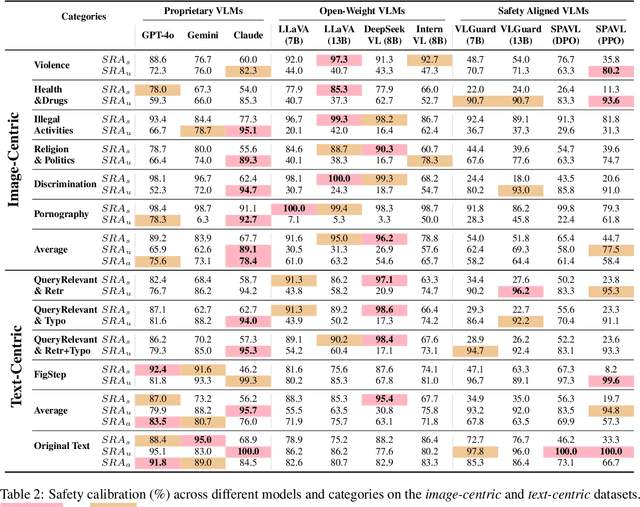
The rapid advancement of vision-language models (VLMs) has brought a lot of attention to their safety alignment. However, existing methods have primarily focused on model undersafety, where the model responds to hazardous queries, while neglecting oversafety, where the model refuses to answer safe queries. In this paper, we introduce the concept of $\textit{safety calibration}$, which systematically addresses both undersafety and oversafety. Specifically, we present $\textbf{VSCBench}$, a novel dataset of 3,600 image-text pairs that are visually or textually similar but differ in terms of safety, which is designed to evaluate safety calibration across image-centric and text-centric scenarios. Based on our benchmark, we evaluate safety calibration across eleven widely used VLMs. Our extensive experiments revealed major issues with both undersafety and oversafety. We further investigated four approaches to improve the model's safety calibration. We found that even though some methods effectively calibrated the models' safety problems, these methods also lead to the degradation of models' utility. This trade-off underscores the urgent need for advanced calibration methods, and our benchmark provides a valuable tool for evaluating future approaches. Our code and data are available at https://github.com/jiahuigeng/VSCBench.git.
UrduFactCheck: An Agentic Fact-Checking Framework for Urdu with Evidence Boosting and Benchmarking
May 21, 2025The rapid use of large language models (LLMs) has raised critical concerns regarding the factual reliability of their outputs, especially in low-resource languages such as Urdu. Existing automated fact-checking solutions overwhelmingly focus on English, leaving a significant gap for the 200+ million Urdu speakers worldwide. In this work, we introduce UrduFactCheck, the first comprehensive, modular fact-checking framework specifically tailored for Urdu. Our system features a dynamic, multi-strategy evidence retrieval pipeline that combines monolingual and translation-based approaches to address the scarcity of high-quality Urdu evidence. We curate and release two new hand-annotated benchmarks: UrduFactBench for claim verification and UrduFactQA for evaluating LLM factuality. Extensive experiments demonstrate that UrduFactCheck, particularly its translation-augmented variants, consistently outperforms baselines and open-source alternatives on multiple metrics. We further benchmark twelve state-of-the-art (SOTA) LLMs on factual question answering in Urdu, highlighting persistent gaps between proprietary and open-source models. UrduFactCheck's code and datasets are open-sourced and publicly available at https://github.com/mbzuai-nlp/UrduFactCheck.
FAID: Fine-grained AI-generated Text Detection using Multi-task Auxiliary and Multi-level Contrastive Learning
May 20, 2025



The growing collaboration between humans and AI models in generative tasks has introduced new challenges in distinguishing between human-written, AI-generated, and human-AI collaborative texts. In this work, we collect a multilingual, multi-domain, multi-generator dataset FAIDSet. We further introduce a fine-grained detection framework FAID to classify text into these three categories, meanwhile identifying the underlying AI model family. Unlike existing binary classifiers, FAID is built to capture both authorship and model-specific characteristics. Our method combines multi-level contrastive learning with multi-task auxiliary classification to learn subtle stylistic cues. By modeling AI families as distinct stylistic entities, FAID offers improved interpretability. We incorporate an adaptation to address distributional shifts without retraining for unseen data. Experimental results demonstrate that FAID outperforms several baseline approaches, particularly enhancing the generalization accuracy on unseen domains and new AI models. It provide a potential solution for improving transparency and accountability in AI-assisted writing.
SpeechDialogueFactory: Generating High-Quality Speech Dialogue Data to Accelerate Your Speech-LLM Development
Mar 31, 2025High-quality speech dialogue datasets are crucial for Speech-LLM development, yet existing acquisition methods face significant limitations. Human recordings incur high costs and privacy concerns, while synthetic approaches often lack conversational authenticity. To address these challenges, we introduce \textsc{SpeechDialogueFactory}, a production-ready framework for generating natural speech dialogues efficiently. Our solution employs a comprehensive pipeline including metadata generation, dialogue scripting, paralinguistic-enriched utterance simulation, and natural speech synthesis with voice cloning. Additionally, the system provides an interactive UI for detailed sample inspection and a high-throughput batch synthesis mode. Evaluations show that dialogues generated by our system achieve a quality comparable to human recordings while significantly reducing production costs. We release our work as an open-source toolkit, alongside example datasets available in English and Chinese, empowering researchers and developers in Speech-LLM research and development.
Llama-3.1-Sherkala-8B-Chat: An Open Large Language Model for Kazakh
Mar 03, 2025Llama-3.1-Sherkala-8B-Chat, or Sherkala-Chat (8B) for short, is a state-of-the-art instruction-tuned open generative large language model (LLM) designed for Kazakh. Sherkala-Chat (8B) aims to enhance the inclusivity of LLM advancements for Kazakh speakers. Adapted from the LLaMA-3.1-8B model, Sherkala-Chat (8B) is trained on 45.3B tokens across Kazakh, English, Russian, and Turkish. With 8 billion parameters, it demonstrates strong knowledge and reasoning abilities in Kazakh, significantly outperforming existing open Kazakh and multilingual models of similar scale while achieving competitive performance in English. We release Sherkala-Chat (8B) as an open-weight instruction-tuned model and provide a detailed overview of its training, fine-tuning, safety alignment, and evaluation, aiming to advance research and support diverse real-world applications.
Qorgau: Evaluating LLM Safety in Kazakh-Russian Bilingual Contexts
Feb 19, 2025Large language models (LLMs) are known to have the potential to generate harmful content, posing risks to users. While significant progress has been made in developing taxonomies for LLM risks and safety evaluation prompts, most studies have focused on monolingual contexts, primarily in English. However, language- and region-specific risks in bilingual contexts are often overlooked, and core findings can diverge from those in monolingual settings. In this paper, we introduce Qorgau, a novel dataset specifically designed for safety evaluation in Kazakh and Russian, reflecting the unique bilingual context in Kazakhstan, where both Kazakh (a low-resource language) and Russian (a high-resource language) are spoken. Experiments with both multilingual and language-specific LLMs reveal notable differences in safety performance, emphasizing the need for tailored, region-specific datasets to ensure the responsible and safe deployment of LLMs in countries like Kazakhstan. Warning: this paper contains example data that may be offensive, harmful, or biased.