 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResurfacing Paralinguistic Awareness in Large Audio Language Models
Mar 12, 2026Large Audio Language Models (LALMs) have expanded the interaction with human to speech modality, which introduces great interactive potential, due to the paralinguistic cues implicitly indicating the user context. However, building on the current content-centred paradigm, LALMs usually neglect such paralinguistic cues and respond solely based on query content. In this work, to resurface the paralinguistic awareness in LALMs, we introduce five diverse layer-wise analyses to jointly identify paralinguistic layers and semantic understanding layers. Based on these insights, we propose a paralinguistic-enhanced fine-tuning (PE-FT) protocol accordingly to equip LALMs with paralinguistic-aware capabilities, including (1) selective-layer fine-tuning, and (2) an auxiliary dual-level classification head. Our experiments demonstrate that PE-FT protocol efficiently and effectively resurfaces the paralinguistic awareness, even surpassing the performance of the all-layer fine-tuning strategy.
GTS: Inference-Time Scaling of Latent Reasoning with a Learnable Gaussian Thought Sampler
Feb 15, 2026Inference-time scaling (ITS) in latent reasoning models typically introduces stochasticity through heuristic perturbations, such as dropout or fixed Gaussian noise. While these methods increase trajectory diversity, their exploration behavior is not explicitly modeled and can be inefficient under finite sampling budgets. We observe that stronger perturbations do not necessarily translate into more effective candidate trajectories, as unguided noise may disrupt internal decision structure rather than steer it. To provide a more structured alternative, we model latent thought exploration as conditional sampling from learnable densities and instantiate this idea as a Gaussian Thought Sampler (GTS). GTS predicts context-dependent perturbation distributions over continuous reasoning states and is trained with GRPO-style policy optimization while keeping the backbone frozen. Experiments on GSM8K with two latent reasoning architectures show that GTS achieves more reliable inference-time scaling than heuristic baselines. These findings indicate that improving latent ITS requires structured and optimizable exploration mechanisms rather than simply amplifying stochasticity.
Improving Symbolic Translation of Language Models for Logical Reasoning
Jan 14, 2026The use of formal language for deductive logical reasoning aligns well with language models (LMs), where translating natural language (NL) into first-order logic (FOL) and employing an external solver results in a verifiable and therefore reliable reasoning system. However, smaller LMs often struggle with this translation task, frequently producing incorrect symbolic outputs due to formatting and translation errors. Existing approaches typically rely on self-iteration to correct these errors, but such methods depend heavily on the capabilities of the underlying model. To address this, we first categorize common errors and fine-tune smaller LMs using data synthesized by large language models. The evaluation is performed using the defined error categories. We introduce incremental inference, which divides inference into two stages, predicate generation and FOL translation, providing greater control over model behavior and enhancing generation quality as measured by predicate metrics. This decomposition framework also enables the use of a verification module that targets predicate-arity errors to further improve performance. Our study evaluates three families of models across four logical-reasoning datasets. The comprehensive fine-tuning, incremental inference, and verification modules reduce error rates, increase predicate coverage, and improve reasoning performance for smaller LMs, moving us closer to developing reliable and accessible symbolic-reasoning systems.
Cube Bench: A Benchmark for Spatial Visual Reasoning in MLLMs
Dec 23, 2025We introduce Cube Bench, a Rubik's-cube benchmark for evaluating spatial and sequential reasoning in multimodal large language models (MLLMs). The benchmark decomposes performance into five skills: (i) reconstructing cube faces from images and text, (ii) choosing the optimal next move, (iii) predicting the outcome of a candidate move without applying it, (iv) executing multi-step plans while recovering from mistakes, and (v) detecting and revising one's own errors. Using a shared set of scrambled cube states, identical prompts and parsers, and a single distance-to-solved metric, we compare recent MLLMs side by side as a function of scramble depth. Across seven MLLMs, accuracy drops sharply with depth; once a trajectory stalls or diverges, models rarely recover, and high face-reconstruction accuracy does not guarantee competent action selection or multi-step execution. A pronounced closed- vs open-source gap emerges: the strongest closed model leads on both single-step perception tasks and multi-step control tasks, while open-weight models cluster near chance on the hardest settings; yet even the best MLLM degrades at higher cube complexity. A simple self-correction via reflective thinking yields modest gains but can also introduce overthinking. Cube Bench offers a compact, reproducible probe of sequential spatial reasoning in MLLMs.
All Roads Lead to Rome: Graph-Based Confidence Estimation for Large Language Model Reasoning
Sep 16, 2025Confidence estimation is essential for the reliable deployment of large language models (LLMs). Existing methods are primarily designed for factual QA tasks and often fail to generalize to reasoning tasks. To address this gap, we propose a set of training-free, graph-based confidence estimation methods tailored to reasoning tasks. Our approach models reasoning paths as directed graphs and estimates confidence by exploiting graph properties such as centrality, path convergence, and path weighting. Experiments with two LLMs on three reasoning datasets demonstrate improved confidence estimation and enhanced performance on two downstream tasks.
Logical Reasoning with Outcome Reward Models for Test-Time Scaling
Aug 27, 2025Logical reasoning is a critical benchmark for evaluating the capabilities of large language models (LLMs), as it reflects their ability to derive valid conclusions from given premises. While the combination of test-time scaling with dedicated outcome or process reward models has opened up new avenues to enhance LLMs performance in complex reasoning tasks, this space is under-explored in deductive logical reasoning. We present a set of Outcome Reward Models (ORMs) for deductive reasoning. To train the ORMs we mainly generate data using Chain-of-Thought (CoT) with single and multiple samples. Additionally, we propose a novel tactic to further expand the type of errors covered in the training dataset of the ORM. In particular, we propose an echo generation technique that leverages LLMs' tendency to reflect incorrect assumptions made in prompts to extract additional training data, covering previously unexplored error types. While a standard CoT chain may contain errors likely to be made by the reasoner, the echo strategy deliberately steers the model toward incorrect reasoning. We show that ORMs trained on CoT and echo-augmented data demonstrate improved performance on the FOLIO, JustLogic, and ProverQA datasets across four different LLMs.
Discrete Minds in a Continuous World: Do Language Models Know Time Passes?
Jun 06, 2025



While Large Language Models (LLMs) excel at temporal reasoning tasks like event ordering and duration estimation, their ability to perceive the actual passage of time remains unexplored. We investigate whether LLMs perceive the passage of time and adapt their decision-making accordingly through three complementary experiments. First, we introduce the Token-Time Hypothesis, positing that LLMs can map discrete token counts to continuous wall-clock time, and validate this through a dialogue duration judgment task. Second, we demonstrate that LLMs could use this awareness to adapt their response length while maintaining accuracy when users express urgency in question answering tasks. Finally, we develop BombRush, an interactive navigation challenge that examines how LLMs modify behavior under progressive time pressure in dynamic environments. Our findings indicate that LLMs possess certain awareness of time passage, enabling them to bridge discrete linguistic tokens and continuous physical time, though this capability varies with model size and reasoning abilities. This work establishes a theoretical foundation for enhancing temporal awareness in LLMs for time-sensitive applications.
Reshaping Representation Space to Balance the Safety and Over-rejection in Large Audio Language Models
May 26, 2025Large Audio Language Models (LALMs) have extended the capabilities of Large Language Models (LLMs) by enabling audio-based human interactions. However, recent research has revealed that LALMs remain vulnerable to harmful queries due to insufficient safety-alignment. Despite advances in defence measures for text and vision LLMs, effective safety-alignment strategies and audio-safety dataset specifically targeting LALMs are notably absent. Meanwhile defence measures based on Supervised Fine-tuning (SFT) struggle to address safety improvement while avoiding over-rejection issues, significantly compromising helpfulness. In this work, we propose an unsupervised safety-fine-tuning strategy as remedy that reshapes model's representation space to enhance existing LALMs safety-alignment while balancing the risk of over-rejection. Our experiments, conducted across three generations of Qwen LALMs, demonstrate that our approach significantly improves LALMs safety under three modality input conditions (audio-text, text-only, and audio-only) while increasing over-rejection rate by only 0.88% on average. Warning: this paper contains harmful examples.
VerifiAgent: a Unified Verification Agent in Language Model Reasoning
Apr 01, 2025


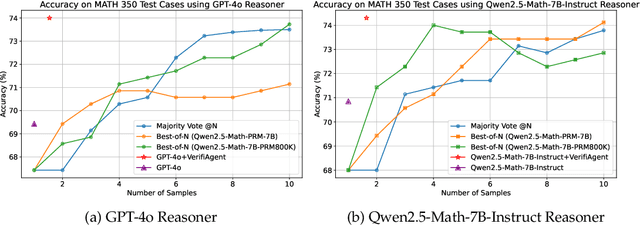
Large language models demonstrate remarkable reasoning capabilities but often produce unreliable or incorrect responses. Existing verification methods are typically model-specific or domain-restricted, requiring significant computational resources and lacking scalability across diverse reasoning tasks. To address these limitations, we propose VerifiAgent, a unified verification agent that integrates two levels of verification: meta-verification, which assesses completeness and consistency in model responses, and tool-based adaptive verification, where VerifiAgent autonomously selects appropriate verification tools based on the reasoning type, including mathematical, logical, or commonsense reasoning. This adaptive approach ensures both efficiency and robustness across different verification scenarios. Experimental results show that VerifiAgent outperforms baseline verification methods (e.g., deductive verifier, backward verifier) among all reasoning tasks. Additionally, it can further enhance reasoning accuracy by leveraging feedback from verification results. VerifiAgent can also be effectively applied to inference scaling, achieving better results with fewer generated samples and costs compared to existing process reward models in the mathematical reasoning domain. Code is available at https://github.com/Jiuzhouh/VerifiAgent
SpeechDialogueFactory: Generating High-Quality Speech Dialogue Data to Accelerate Your Speech-LLM Development
Mar 31, 2025High-quality speech dialogue datasets are crucial for Speech-LLM development, yet existing acquisition methods face significant limitations. Human recordings incur high costs and privacy concerns, while synthetic approaches often lack conversational authenticity. To address these challenges, we introduce \textsc{SpeechDialogueFactory}, a production-ready framework for generating natural speech dialogues efficiently. Our solution employs a comprehensive pipeline including metadata generation, dialogue scripting, paralinguistic-enriched utterance simulation, and natural speech synthesis with voice cloning. Additionally, the system provides an interactive UI for detailed sample inspection and a high-throughput batch synthesis mode. Evaluations show that dialogues generated by our system achieve a quality comparable to human recordings while significantly reducing production costs. We release our work as an open-source toolkit, alongside example datasets available in English and Chinese, empowering researchers and developers in Speech-LLM research and development.