 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Prompt Tuning
Jul 09, 2025This survey reviews prompt tuning, a parameter-efficient approach for adapting language models by prepending trainable continuous vectors while keeping the model frozen. We classify existing approaches into two categories: direct prompt learning and transfer learning. Direct prompt learning methods include: general optimization approaches, encoder-based methods, decomposition strategies, and mixture-of-experts frameworks. Transfer learning methods consist of: general transfer approaches, encoder-based methods, and decomposition strategies. For each method, we analyze method designs, innovations, insights, advantages, and disadvantages, with illustrative visualizations comparing different frameworks. We identify challenges in computational efficiency and training stability, and discuss future directions in improving training robustness and broadening application scope.
PT-MoE: An Efficient Finetuning Framework for Integrating Mixture-of-Experts into Prompt Tuning
May 14, 2025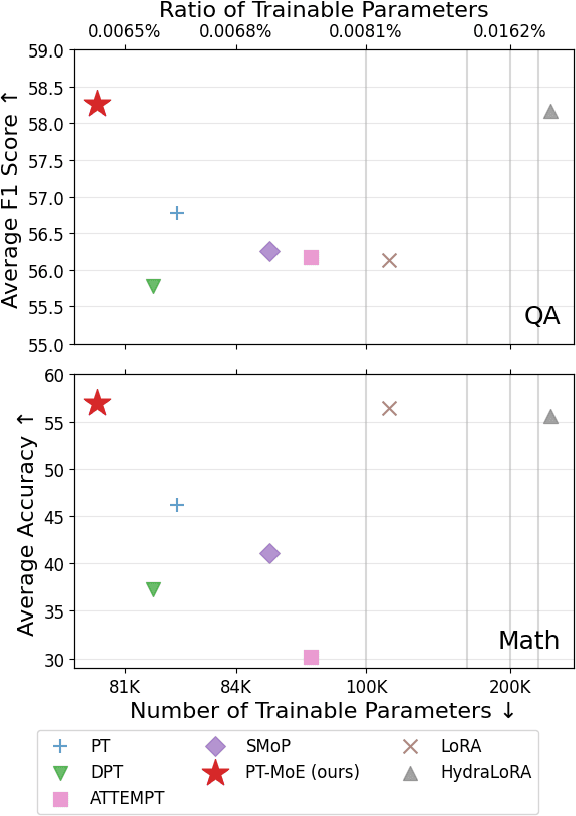

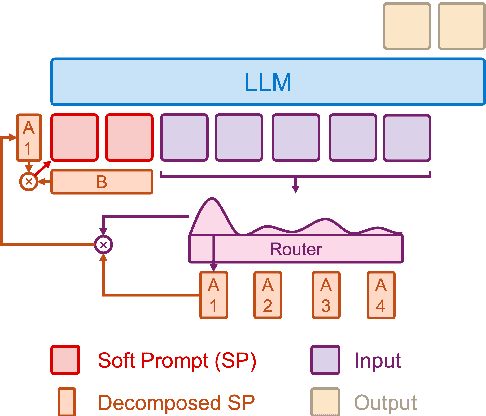
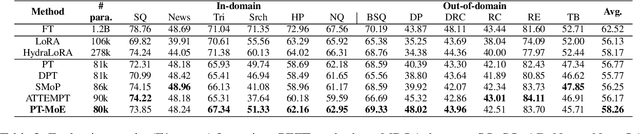
Parameter-efficient fine-tuning (PEFT) methods have shown promise in adapting large language models, yet existing approaches exhibit counter-intuitive phenomena: integrating router into prompt tuning (PT) increases training efficiency yet does not improve performance universally; parameter reduction through matrix decomposition can improve performance in specific domains. Motivated by these observations and the modular nature of PT, we propose PT-MoE, a novel framework that integrates matrix decomposition with mixture-of-experts (MoE) routing for efficient PT. Results across 17 datasets demonstrate that PT-MoE achieves state-of-the-art performance in both question answering (QA) and mathematical problem solving tasks, improving F1 score by 1.49 points over PT and 2.13 points over LoRA in QA tasks, while enhancing mathematical accuracy by 10.75 points over PT and 0.44 points over LoRA, all while using 25% fewer parameters than LoRA. Our analysis reveals that while PT methods generally excel in QA tasks and LoRA-based methods in math datasets, the integration of matrix decomposition and MoE in PT-MoE yields complementary benefits: decomposition enables efficient parameter sharing across experts while MoE provides dynamic adaptation, collectively enabling PT-MoE to demonstrate cross-task consistency and generalization abilities. These findings, along with ablation studies on routing mechanisms and architectural components, provide insights for future PEFT methods.
General Scales Unlock AI Evaluation with Explanatory and Predictive Power
Mar 09, 2025Ensuring safe and effective use of AI requires understanding and anticipating its performance on novel tasks, from advanced scientific challenges to transformed workplace activities. So far, benchmarking has guided progress in AI, but it has offered limited explanatory and predictive power for general-purpose AI systems, given the low transferability across diverse tasks. In this paper, we introduce general scales for AI evaluation that can explain what common AI benchmarks really measure, extract ability profiles of AI systems, and predict their performance for new task instances, in- and out-of-distribution. Our fully-automated methodology builds on 18 newly-crafted rubrics that place instance demands on general scales that do not saturate. Illustrated for 15 large language models and 63 tasks, high explanatory power is unleashed from inspecting the demand and ability profiles, bringing insights on the sensitivity and specificity exhibited by different benchmarks, and how knowledge, metacognition and reasoning are affected by model size, chain-of-thought and distillation. Surprisingly, high predictive power at the instance level becomes possible using these demand levels, providing superior estimates over black-box baseline predictors based on embeddings or finetuning, especially in out-of-distribution settings (new tasks and new benchmarks). The scales, rubrics, battery, techniques and results presented here represent a major step for AI evaluation, underpinning the reliable deployment of AI in the years ahead.
ReasonGraph: Visualisation of Reasoning Paths
Mar 06, 2025Large Language Models (LLMs) reasoning processes are challenging to analyze due to their complexity and the lack of organized visualization tools. We present ReasonGraph, a web-based platform for visualizing and analyzing LLM reasoning processes. It supports both sequential and tree-based reasoning methods while integrating with major LLM providers and over fifty state-of-the-art models. ReasonGraph incorporates an intuitive UI with meta reasoning method selection, configurable visualization parameters, and a modular framework that facilitates efficient extension. Our evaluation shows high parsing reliability, efficient processing, and strong usability across various downstream applications. By providing a unified visualization framework, ReasonGraph reduces cognitive load in analyzing complex reasoning paths, improves error detection in logical processes, and enables more effective development of LLM-based applications. The platform is open-source, promoting accessibility and reproducibility in LLM reasoning analysis.
Prompt Compression for Large Language Models: A Survey
Oct 17, 2024Leveraging large language models (LLMs) for complex natural language tasks typically requires long-form prompts to convey detailed requirements and information, which results in increased memory usage and inference costs. To mitigate these challenges, multiple efficient methods have been proposed, with prompt compression gaining significant research interest. This survey provides an overview of prompt compression techniques, categorized into hard prompt methods and soft prompt methods. First, the technical approaches of these methods are compared, followed by an exploration of various ways to understand their mechanisms, including the perspectives of attention optimization, Parameter-Efficient Fine-Tuning (PEFT), modality integration, and new synthetic language. We also examine the downstream adaptations of various prompt compression techniques. Finally, the limitations of current prompt compression methods are analyzed, and several future directions are outlined, such as optimizing the compression encoder, combining hard and soft prompts methods, and leveraging insights from multimodality.
500xCompressor: Generalized Prompt Compression for Large Language Models
Aug 06, 2024Prompt compression is crucial for enhancing inference speed, reducing costs, and improving user experience. However, current methods face challenges such as low compression ratios and potential data leakage during evaluation. To address these issues, we propose 500xCompressor, a method that compresses extensive natural language contexts into a minimum of one single special token. The 500xCompressor introduces approximately 0.3% additional parameters and achieves compression ratios ranging from 6x to 480x. It is designed to compress any text, answer various types of questions, and could be utilized by the original large language model (LLM) without requiring fine-tuning. Initially, 500xCompressor was pretrained on the Arxiv Corpus, followed by fine-tuning on the ArxivQA dataset, and subsequently evaluated on strictly unseen and classical question answering (QA) datasets. The results demonstrate that the LLM retained 62.26-72.89% of its capabilities compared to using non-compressed prompts. This study also shows that not all the compressed tokens are equally utilized and that K V values have significant advantages over embeddings in preserving information at high compression ratios. The highly compressive nature of natural language prompts, even for fine-grained complex information, suggests promising potential for future applications and further research into developing a new LLM language.