 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Matter of Interest: Understanding Interestingness of Math Problems in Humans and Language Models
Nov 11, 2025The evolution of mathematics has been guided in part by interestingness. From researchers choosing which problems to tackle next, to students deciding which ones to engage with, people's choices are often guided by judgments about how interesting or challenging problems are likely to be. As AI systems, such as LLMs, increasingly participate in mathematics with people -- whether for advanced research or education -- it becomes important to understand how well their judgments align with human ones. Our work examines this alignment through two empirical studies of human and LLM assessment of mathematical interestingness and difficulty, spanning a range of mathematical experience. We study two groups: participants from a crowdsourcing platform and International Math Olympiad competitors. We show that while many LLMs appear to broadly agree with human notions of interestingness, they mostly do not capture the distribution observed in human judgments. Moreover, most LLMs only somewhat align with why humans find certain math problems interesting, showing weak correlation with human-selected interestingness rationales. Together, our findings highlight both the promises and limitations of current LLMs in capturing human interestingness judgments for mathematical AI thought partnerships.
What's in the Box? Reasoning about Unseen Objects from Multimodal Cues
Jun 17, 2025People regularly make inferences about objects in the world that they cannot see by flexibly integrating information from multiple sources: auditory and visual cues, language, and our prior beliefs and knowledge about the scene. How are we able to so flexibly integrate many sources of information to make sense of the world around us, even if we have no direct knowledge? In this work, we propose a neurosymbolic model that uses neural networks to parse open-ended multimodal inputs and then applies a Bayesian model to integrate different sources of information to evaluate different hypotheses. We evaluate our model with a novel object guessing game called ``What's in the Box?'' where humans and models watch a video clip of an experimenter shaking boxes and then try to guess the objects inside the boxes. Through a human experiment, we show that our model correlates strongly with human judgments, whereas unimodal ablated models and large multimodal neural model baselines show poor correlation.
Identifying, Evaluating, and Mitigating Risks of AI Thought Partnerships
May 22, 2025Artificial Intelligence (AI) systems have historically been used as tools that execute narrowly defined tasks. Yet recent advances in AI have unlocked possibilities for a new class of models that genuinely collaborate with humans in complex reasoning, from conceptualizing problems to brainstorming solutions. Such AI thought partners enable novel forms of collaboration and extended cognition, yet they also pose major risks-including and beyond risks of typical AI tools and agents. In this commentary, we systematically identify risks of AI thought partners through a novel framework that identifies risks at multiple levels of analysis, including Real-time, Individual, and Societal risks arising from collaborative cognition (RISc). We leverage this framework to propose concrete metrics for risk evaluation, and finally suggest specific mitigation strategies for developers and policymakers. As AI thought partners continue to proliferate, these strategies can help prevent major harms and ensure that humans actively benefit from productive thought partnerships.
When Should We Orchestrate Multiple Agents?
Mar 17, 2025Strategies for orchestrating the interactions between multiple agents, both human and artificial, can wildly overestimate performance and underestimate the cost of orchestration. We design a framework to orchestrate agents under realistic conditions, such as inference costs or availability constraints. We show theoretically that orchestration is only effective if there are performance or cost differentials between agents. We then empirically demonstrate how orchestration between multiple agents can be helpful for selecting agents in a simulated environment, picking a learning strategy in the infamous Rogers' Paradox from social science, and outsourcing tasks to other agents during a question-answer task in a user study.
General Scales Unlock AI Evaluation with Explanatory and Predictive Power
Mar 09, 2025Ensuring safe and effective use of AI requires understanding and anticipating its performance on novel tasks, from advanced scientific challenges to transformed workplace activities. So far, benchmarking has guided progress in AI, but it has offered limited explanatory and predictive power for general-purpose AI systems, given the low transferability across diverse tasks. In this paper, we introduce general scales for AI evaluation that can explain what common AI benchmarks really measure, extract ability profiles of AI systems, and predict their performance for new task instances, in- and out-of-distribution. Our fully-automated methodology builds on 18 newly-crafted rubrics that place instance demands on general scales that do not saturate. Illustrated for 15 large language models and 63 tasks, high explanatory power is unleashed from inspecting the demand and ability profiles, bringing insights on the sensitivity and specificity exhibited by different benchmarks, and how knowledge, metacognition and reasoning are affected by model size, chain-of-thought and distillation. Surprisingly, high predictive power at the instance level becomes possible using these demand levels, providing superior estimates over black-box baseline predictors based on embeddings or finetuning, especially in out-of-distribution settings (new tasks and new benchmarks). The scales, rubrics, battery, techniques and results presented here represent a major step for AI evaluation, underpinning the reliable deployment of AI in the years ahead.
On Benchmarking Human-Like Intelligence in Machines
Feb 27, 2025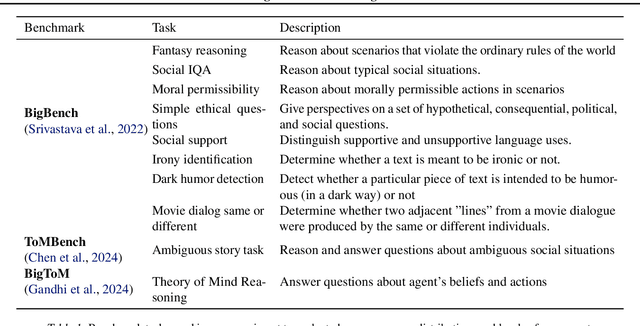
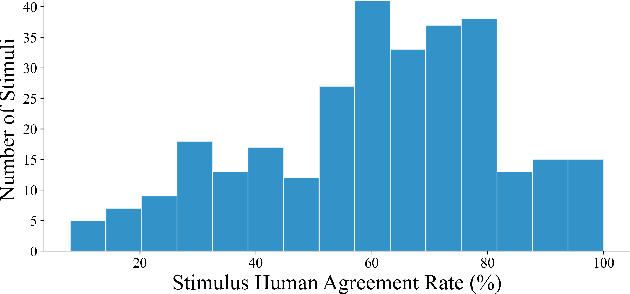
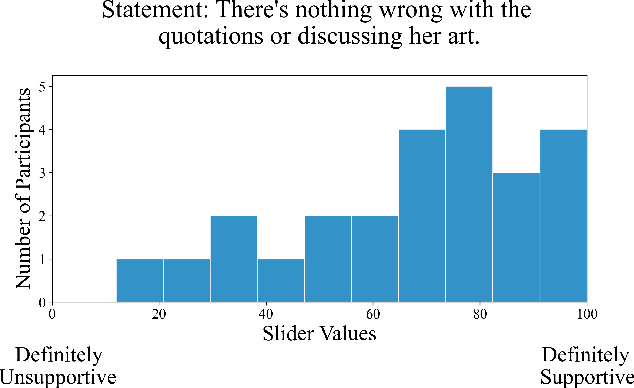
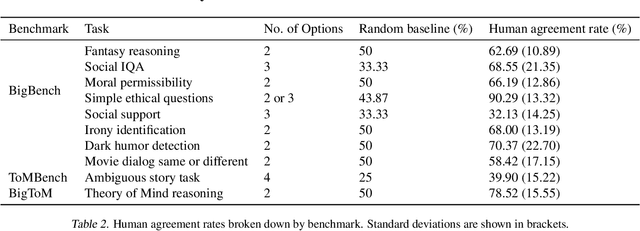
Recent benchmark studies have claimed that AI has approached or even surpassed human-level performances on various cognitive tasks. However, this position paper argues that current AI evaluation paradigms are insufficient for assessing human-like cognitive capabilities. We identify a set of key shortcomings: a lack of human-validated labels, inadequate representation of human response variability and uncertainty, and reliance on simplified and ecologically-invalid tasks. We support our claims by conducting a human evaluation study on ten existing AI benchmarks, suggesting significant biases and flaws in task and label designs. To address these limitations, we propose five concrete recommendations for developing future benchmarks that will enable more rigorous and meaningful evaluations of human-like cognitive capacities in AI with various implications for such AI applications.
Data for Mathematical Copilots: Better Ways of Presenting Proofs for Machine Learning
Dec 19, 2024

The suite of datasets commonly used to train and evaluate the mathematical capabilities of AI-based mathematical copilots (primarily large language models) exhibit several shortcomings. These limitations include a restricted scope of mathematical complexity, typically not exceeding lower undergraduate-level mathematics, binary rating protocols and other issues, which makes comprehensive proof-based evaluation suites difficult. We systematically explore these limitations and contend that enhancing the capabilities of large language models, or any forthcoming advancements in AI-based mathematical assistants (copilots or "thought partners"), necessitates a paradigm shift in the design of mathematical datasets and the evaluation criteria of mathematical ability: It is necessary to move away from result-based datasets (theorem statement to theorem proof) and convert the rich facets of mathematical research practice to data LLMs can train on. Examples of these are mathematical workflows (sequences of atomic, potentially subfield-dependent tasks that are often performed when creating new mathematics), which are an important part of the proof-discovery process. Additionally, we advocate for mathematical dataset developers to consider the concept of "motivated proof", introduced by G. P\'olya in 1949, which can serve as a blueprint for datasets that offer a better proof learning signal, alleviating some of the mentioned limitations. Lastly, we introduce math datasheets for datasets, extending the general, dataset-agnostic variants of datasheets: We provide a questionnaire designed specifically for math datasets that we urge dataset creators to include with their datasets. This will make creators aware of potential limitations of their datasets while at the same time making it easy for readers to assess it from the point of view of training and evaluating mathematical copilots.
Can Large Language Models Understand Symbolic Graphics Programs?
Aug 15, 2024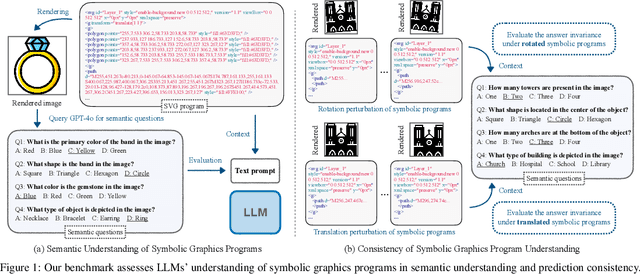

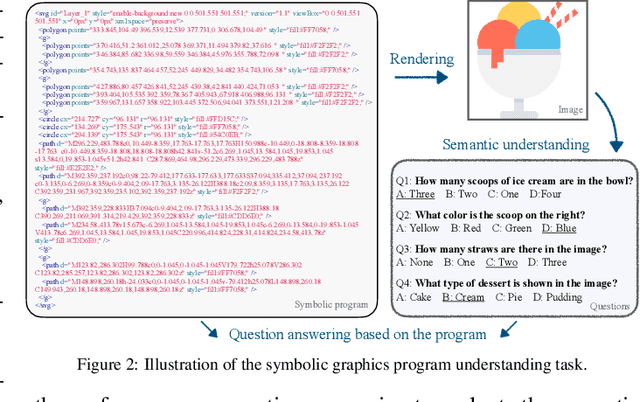
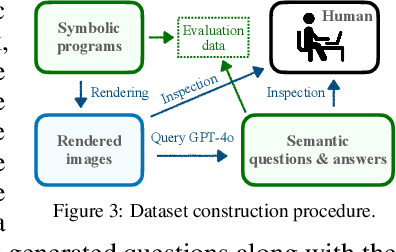
Assessing the capabilities of large language models (LLMs) is often challenging, in part, because it is hard to find tasks to which they have not been exposed during training. We take one step to address this challenge by turning to a new task: focusing on symbolic graphics programs, which are a popular representation for graphics content that procedurally generates visual data. LLMs have shown exciting promise towards program synthesis, but do they understand symbolic graphics programs? Unlike conventional programs, symbolic graphics programs can be translated to graphics content. Here, we characterize an LLM's understanding of symbolic programs in terms of their ability to answer questions related to the graphics content. This task is challenging as the questions are difficult to answer from the symbolic programs alone -- yet, they would be easy to answer from the corresponding graphics content as we verify through a human experiment. To understand symbolic programs, LLMs may need to possess the ability to imagine how the corresponding graphics content would look without directly accessing the rendered visual content. We use this task to evaluate LLMs by creating a large benchmark for the semantic understanding of symbolic graphics programs. This benchmark is built via program-graphics correspondence, hence requiring minimal human efforts. We evaluate current LLMs on our benchmark to elucidate a preliminary assessment of their ability to reason about visual scenes from programs. We find that this task distinguishes existing LLMs and models considered good at reasoning perform better. Lastly, we introduce Symbolic Instruction Tuning (SIT) to improve this ability. Specifically, we query GPT4-o with questions and images generated by symbolic programs. Such data are then used to finetune an LLM. We also find that SIT data can improve the general instruction following ability of LLMs.
Building Machines that Learn and Think with People
Jul 22, 2024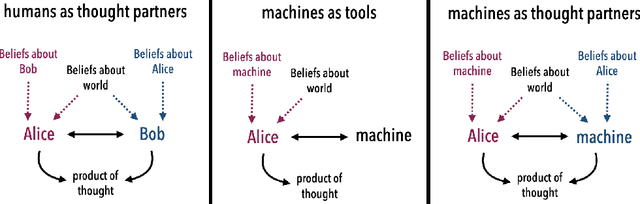
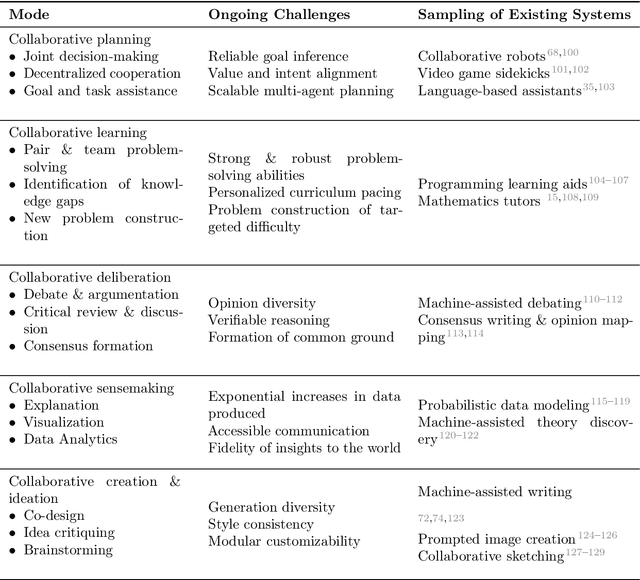
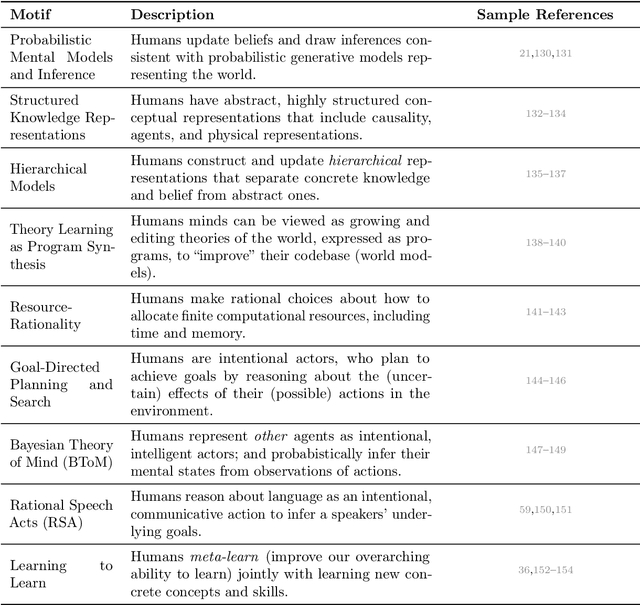
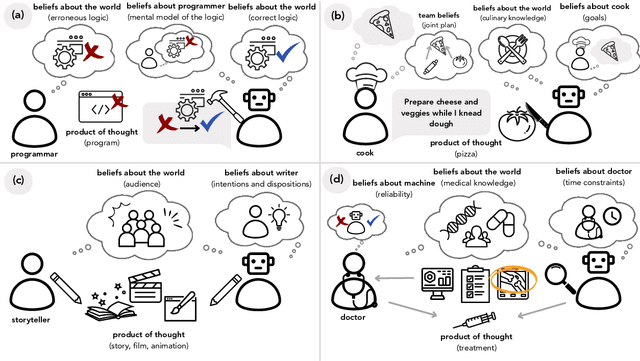
What do we want from machine intelligence? We envision machines that are not just tools for thought, but partners in thought: reasonable, insightful, knowledgeable, reliable, and trustworthy systems that think with us. Current artificial intelligence (AI) systems satisfy some of these criteria, some of the time. In this Perspective, we show how the science of collaborative cognition can be put to work to engineer systems that really can be called ``thought partners,'' systems built to meet our expectations and complement our limitations. We lay out several modes of collaborative thought in which humans and AI thought partners can engage and propose desiderata for human-compatible thought partnerships. Drawing on motifs from computational cognitive science, we motivate an alternative scaling path for the design of thought partners and ecosystems around their use through a Bayesian lens, whereby the partners we construct actively build and reason over models of the human and world.
People use fast, goal-directed simulation to reason about novel games
Jul 19, 2024We can evaluate features of problems and their potential solutions well before we can effectively solve them. When considering a game we have never played, for instance, we might infer whether it is likely to be challenging, fair, or fun simply from hearing the game rules, prior to deciding whether to invest time in learning the game or trying to play it well. Many studies of game play have focused on optimality and expertise, characterizing how people and computational models play based on moderate to extensive search and after playing a game dozens (if not thousands or millions) of times. Here, we study how people reason about a range of simple but novel connect-n style board games. We ask people to judge how fair and how fun the games are from very little experience: just thinking about the game for a minute or so, before they have ever actually played with anyone else, and we propose a resource-limited model that captures their judgments using only a small number of partial game simulations and almost no lookahead search.