 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNonlinear dynamics of localization in neural receptive fields
Jan 28, 2025



Localized receptive fields -- neurons that are selective for certain contiguous spatiotemporal features of their input -- populate early sensory regions of the mammalian brain. Unsupervised learning algorithms that optimize explicit sparsity or independence criteria replicate features of these localized receptive fields, but fail to explain directly how localization arises through learning without efficient coding, as occurs in early layers of deep neural networks and might occur in early sensory regions of biological systems. We consider an alternative model in which localized receptive fields emerge without explicit top-down efficiency constraints -- a feedforward neural network trained on a data model inspired by the structure of natural images. Previous work identified the importance of non-Gaussian statistics to localization in this setting but left open questions about the mechanisms driving dynamical emergence. We address these questions by deriving the effective learning dynamics for a single nonlinear neuron, making precise how higher-order statistical properties of the input data drive emergent localization, and we demonstrate that the predictions of these effective dynamics extend to the many-neuron setting. Our analysis provides an alternative explanation for the ubiquity of localization as resulting from the nonlinear dynamics of learning in neural circuits.
Bayes in the age of intelligent machines
Nov 16, 2023The success of methods based on artificial neural networks in creating intelligent machines seems like it might pose a challenge to explanations of human cognition in terms of Bayesian inference. We argue that this is not the case, and that in fact these systems offer new opportunities for Bayesian modeling. Specifically, we argue that Bayesian models of cognition and artificial neural networks lie at different levels of analysis and are complementary modeling approaches, together offering a way to understand human cognition that spans these levels. We also argue that the same perspective can be applied to intelligent machines, where a Bayesian approach may be uniquely valuable in understanding the behavior of large, opaque artificial neural networks that are trained on proprietary data.
The Transient Nature of Emergent In-Context Learning in Transformers
Nov 15, 2023



Transformer neural networks can exhibit a surprising capacity for in-context learning (ICL) despite not being explicitly trained for it. Prior work has provided a deeper understanding of how ICL emerges in transformers, e.g. through the lens of mechanistic interpretability, Bayesian inference, or by examining the distributional properties of training data. However, in each of these cases, ICL is treated largely as a persistent phenomenon; namely, once ICL emerges, it is assumed to persist asymptotically. Here, we show that the emergence of ICL during transformer training is, in fact, often transient. We train transformers on synthetic data designed so that both ICL and in-weights learning (IWL) strategies can lead to correct predictions. We find that ICL first emerges, then disappears and gives way to IWL, all while the training loss decreases, indicating an asymptotic preference for IWL. The transient nature of ICL is observed in transformers across a range of model sizes and datasets, raising the question of how much to "overtrain" transformers when seeking compact, cheaper-to-run models. We find that L2 regularization may offer a path to more persistent ICL that removes the need for early stopping based on ICL-style validation tasks. Finally, we present initial evidence that ICL transience may be caused by competition between ICL and IWL circuits.
Getting aligned on representational alignment
Nov 02, 2023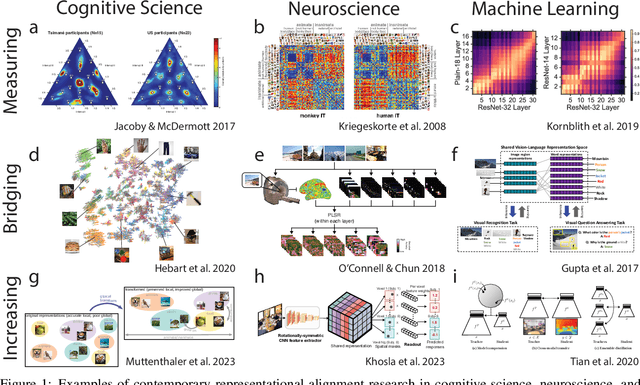
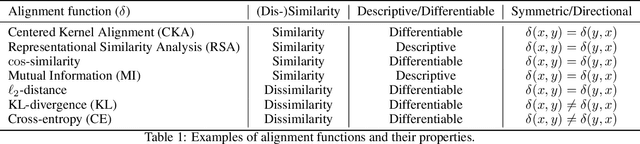
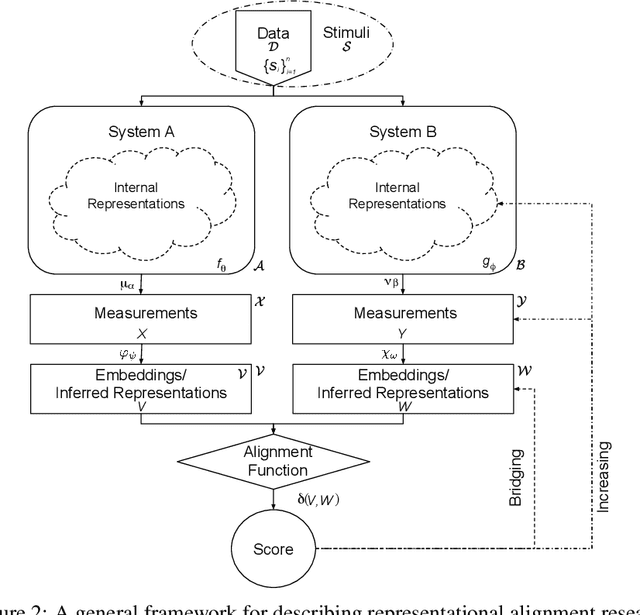
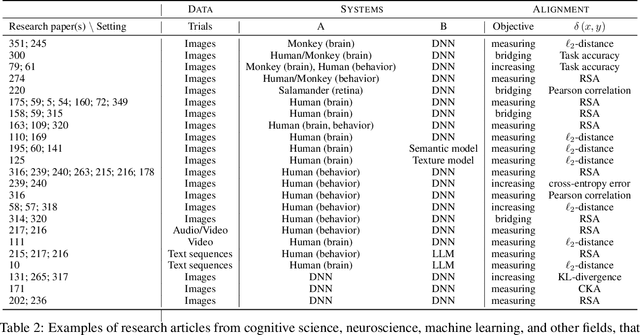
Biological and artificial information processing systems form representations that they can use to categorize, reason, plan, navigate, and make decisions. How can we measure the extent to which the representations formed by these diverse systems agree? Do similarities in representations then translate into similar behavior? How can a system's representations be modified to better match those of another system? These questions pertaining to the study of representational alignment are at the heart of some of the most active research areas in cognitive science, neuroscience, and machine learning. For example, cognitive scientists measure the representational alignment of multiple individuals to identify shared cognitive priors, neuroscientists align fMRI responses from multiple individuals into a shared representational space for group-level analyses, and ML researchers distill knowledge from teacher models into student models by increasing their alignment. Unfortunately, there is limited knowledge transfer between research communities interested in representational alignment, so progress in one field often ends up being rediscovered independently in another. Thus, greater cross-field communication would be advantageous. To improve communication between these fields, we propose a unifying framework that can serve as a common language between researchers studying representational alignment. We survey the literature from all three fields and demonstrate how prior work fits into this framework. Finally, we lay out open problems in representational alignment where progress can benefit all three of these fields. We hope that our work can catalyze cross-disciplinary collaboration and accelerate progress for all communities studying and developing information processing systems. We note that this is a working paper and encourage readers to reach out with their suggestions for future revisions.
Statistical physics, Bayesian inference and neural information processing
Sep 29, 2023

Lecture notes from the course given by Professor Sara A. Solla at the Les Houches summer school on "Statistical physics of Machine Learning". The notes discuss neural information processing through the lens of Statistical Physics. Contents include Bayesian inference and its connection to a Gibbs description of learning and generalization, Generalized Linear Models as a controlled alternative to backpropagation through time, and linear and non-linear techniques for dimensionality reduction.
Gaussian process surrogate models for neural networks
Aug 11, 2022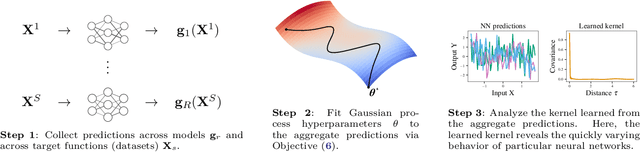
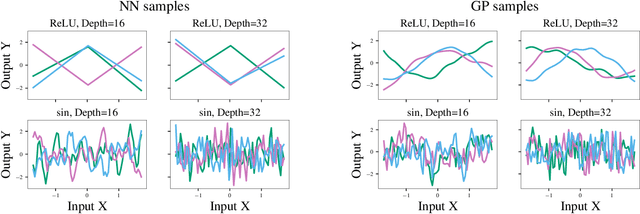

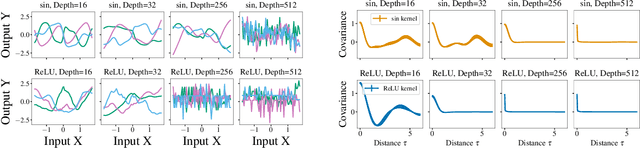
The lack of insight into deep learning systems hinders their systematic design. In science and engineering, modeling is a methodology used to understand complex systems whose internal processes are opaque. Modeling replaces a complex system with a simpler surrogate that is more amenable to interpretation. Drawing inspiration from this, we construct a class of surrogate models for neural networks using Gaussian processes. Rather than deriving the kernels for certain limiting cases of neural networks, we learn the kernels of the Gaussian process empirically from the naturalistic behavior of neural networks. We first evaluate our approach with two case studies inspired by previous theoretical studies of neural network behavior in which we capture neural network preferences for learning low frequencies and identify pathological behavior in deep neural networks. In two further practical case studies, we use the learned kernel to predict the generalization properties of neural networks.
Distinguishing rule- and exemplar-based generalization in learning systems
Oct 08, 2021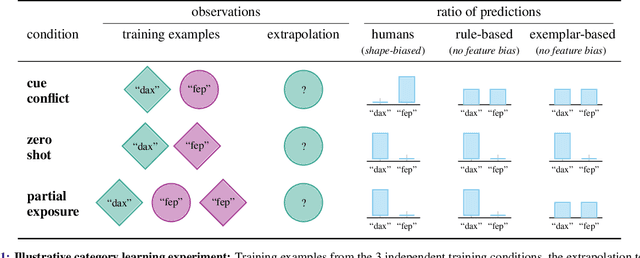
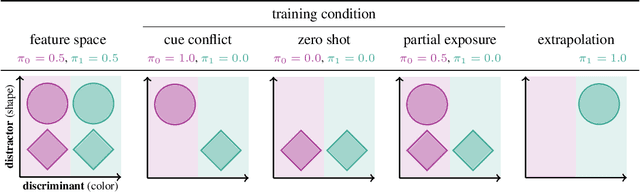
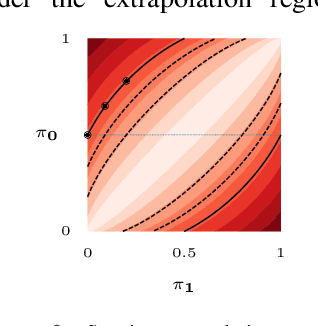
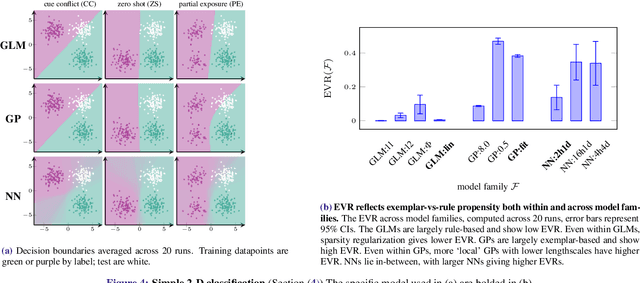
Despite the increasing scale of datasets in machine learning, generalization to unseen regions of the data distribution remains crucial. Such extrapolation is by definition underdetermined and is dictated by a learner's inductive biases. Machine learning systems often do not share the same inductive biases as humans and, as a result, extrapolate in ways that are inconsistent with our expectations. We investigate two distinct such inductive biases: feature-level bias (differences in which features are more readily learned) and exemplar-vs-rule bias (differences in how these learned features are used for generalization). Exemplar- vs. rule-based generalization has been studied extensively in cognitive psychology, and, in this work, we present a protocol inspired by these experimental approaches for directly probing this trade-off in learning systems. The measures we propose characterize changes in extrapolation behavior when feature coverage is manipulated in a combinatorial setting. We present empirical results across a range of models and across both expository and real-world image and language domains. We demonstrate that measuring the exemplar-rule trade-off while controlling for feature-level bias provides a more complete picture of extrapolation behavior than existing formalisms. We find that most standard neural network models have a propensity towards exemplar-based extrapolation and discuss the implications of these findings for research on data augmentation, fairness, and systematic generalization.
Passive attention in artificial neural networks predicts human visual selectivity
Jul 14, 2021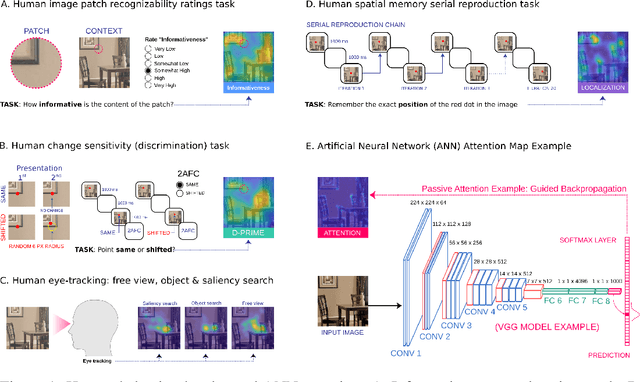
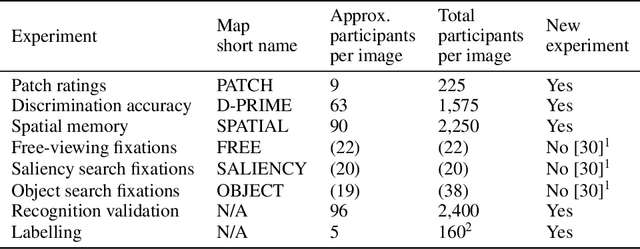
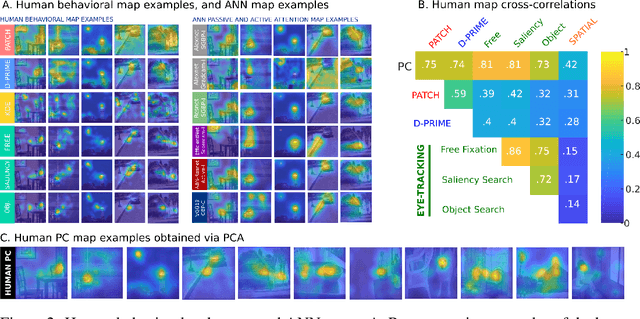
Developments in machine learning interpretability techniques over the past decade have provided new tools to observe the image regions that are most informative for classification and localization in artificial neural networks (ANNs). Are the same regions similarly informative to human observers? Using data from 78 new experiments and 6,610 participants, we show that passive attention techniques reveal a significant overlap with human visual selectivity estimates derived from 6 distinct behavioral tasks including visual discrimination, spatial localization, recognizability, free-viewing, cued-object search, and saliency search fixations. We find that input visualizations derived from relatively simple ANN architectures probed using guided backpropagation methods are the best predictors of a shared component in the joint variability of the human measures. We validate these correlational results with causal manipulations using recognition experiments. We show that images masked with ANN attention maps were easier for humans to classify than control masks in a speeded recognition experiment. Similarly, we find that recognition performance in the same ANN models was likewise influenced by masking input images using human visual selectivity maps. This work contributes a new approach to evaluating the biological and psychological validity of leading ANNs as models of human vision: by examining their similarities and differences in terms of their visual selectivity to the information contained in images.
Are Convolutional Neural Networks or Transformers more like human vision?
May 15, 2021
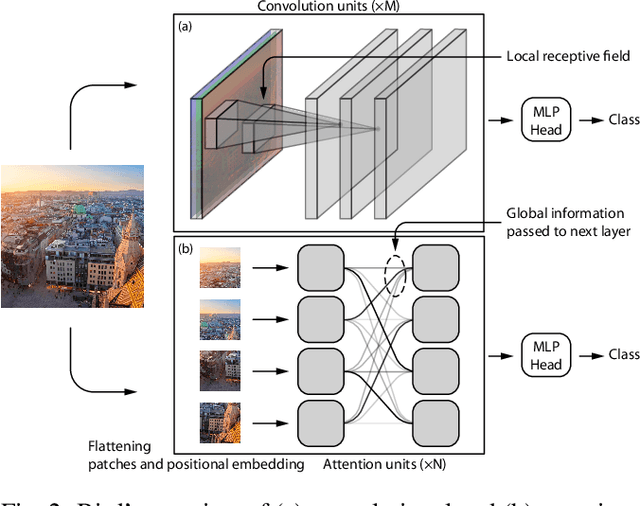

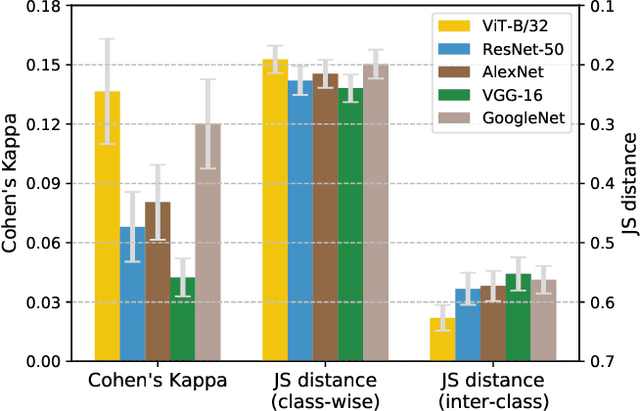
Modern machine learning models for computer vision exceed humans in accuracy on specific visual recognition tasks, notably on datasets like ImageNet. However, high accuracy can be achieved in many ways. The particular decision function found by a machine learning system is determined not only by the data to which the system is exposed, but also the inductive biases of the model, which are typically harder to characterize. In this work, we follow a recent trend of in-depth behavioral analyses of neural network models that go beyond accuracy as an evaluation metric by looking at patterns of errors. Our focus is on comparing a suite of standard Convolutional Neural Networks (CNNs) and a recently-proposed attention-based network, the Vision Transformer (ViT), which relaxes the translation-invariance constraint of CNNs and therefore represents a model with a weaker set of inductive biases. Attention-based networks have previously been shown to achieve higher accuracy than CNNs on vision tasks, and we demonstrate, using new metrics for examining error consistency with more granularity, that their errors are also more consistent with those of humans. These results have implications both for building more human-like vision models, as well as for understanding visual object recognition in humans.
Connecting Context-specific Adaptation in Humans to Meta-learning
Dec 01, 2020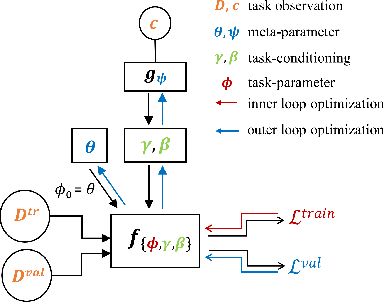
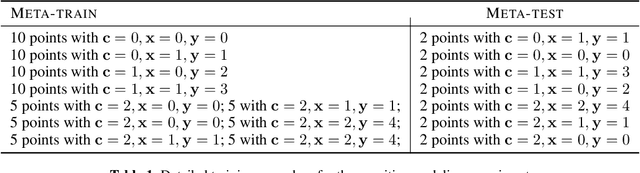


Cognitive control, the ability of a system to adapt to the demands of a task, is an integral part of cognition. A widely accepted fact about cognitive control is that it is context-sensitive: Adults and children alike infer information about a task's demands from contextual cues and use these inferences to learn from ambiguous cues. However, the precise way in which people use contextual cues to guide adaptation to a new task remains poorly understood. This work connects the context-sensitive nature of cognitive control to a method for meta-learning with context-conditioned adaptation. We begin by identifying an essential difference between human learning and current approaches to meta-learning: In contrast to humans, existing meta-learning algorithms do not make use of task-specific contextual cues but instead rely exclusively on online feedback in the form of task-specific labels or rewards. To remedy this, we introduce a framework for using contextual information about a task to guide the initialization of task-specific models before adaptation to online feedback. We show how context-conditioned meta-learning can capture human behavior in a cognitive task and how it can be scaled to improve the speed of learning in various settings, including few-shot classification and low-sample reinforcement learning. Our work demonstrates that guiding meta-learning with task information can capture complex, human-like behavior, thereby deepening our understanding of cognitive control.