 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the final layer: Attentive multilayer fusion for vision transformers
Jan 14, 2026With the rise of large-scale foundation models, efficiently adapting them to downstream tasks remains a central challenge. Linear probing, which freezes the backbone and trains a lightweight head, is computationally efficient but often restricted to last-layer representations. We show that task-relevant information is distributed across the network hierarchy rather than solely encoded in any of the last layers. To leverage this distribution of information, we apply an attentive probing mechanism that dynamically fuses representations from all layers of a Vision Transformer. This mechanism learns to identify the most relevant layers for a target task and combines low-level structural cues with high-level semantic abstractions. Across 20 diverse datasets and multiple pretrained foundation models, our method achieves consistent, substantial gains over standard linear probes. Attention heatmaps further reveal that tasks different from the pre-training domain benefit most from intermediate representations. Overall, our findings underscore the value of intermediate layer information and demonstrate a principled, task aware approach for unlocking their potential in probing-based adaptation.
Atlas 2 - Foundation models for clinical deployment
Jan 08, 2026Pathology foundation models substantially advanced the possibilities in computational pathology -- yet tradeoffs in terms of performance, robustness, and computational requirements remained, which limited their clinical deployment. In this report, we present Atlas 2, Atlas 2-B, and Atlas 2-S, three pathology vision foundation models which bridge these shortcomings by showing state-of-the-art performance in prediction performance, robustness, and resource efficiency in a comprehensive evaluation across eighty public benchmarks. Our models were trained on the largest pathology foundation model dataset to date comprising 5.5 million histopathology whole slide images, collected from three medical institutions Charité - Universtätsmedizin Berlin, LMU Munich, and Mayo Clinic.
Training objective drives the consistency of representational similarity across datasets
Nov 08, 2024



The Platonic Representation Hypothesis claims that recent foundation models are converging to a shared representation space as a function of their downstream task performance, irrespective of the objectives and data modalities used to train these models. Representational similarity is generally measured for individual datasets and is not necessarily consistent across datasets. Thus, one may wonder whether this convergence of model representations is confounded by the datasets commonly used in machine learning. Here, we propose a systematic way to measure how representational similarity between models varies with the set of stimuli used to construct the representations. We find that the objective function is the most crucial factor in determining the consistency of representational similarities across datasets. Specifically, self-supervised vision models learn representations whose relative pairwise similarities generalize better from one dataset to another compared to those of image classification or image-text models. Moreover, the correspondence between representational similarities and the models' task behavior is dataset-dependent, being most strongly pronounced for single-domain datasets. Our work provides a framework for systematically measuring similarities of model representations across datasets and linking those similarities to differences in task behavior.
When Does Perceptual Alignment Benefit Vision Representations?
Oct 14, 2024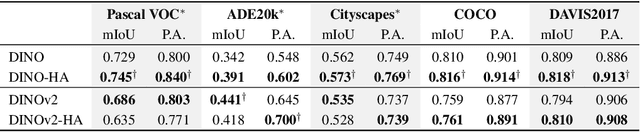
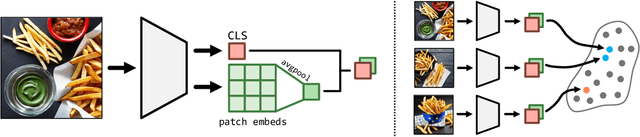
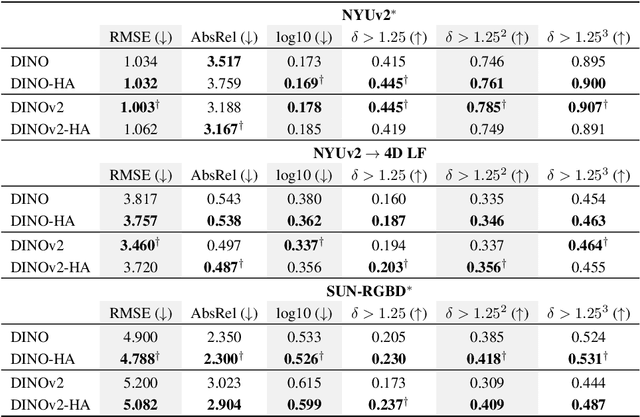
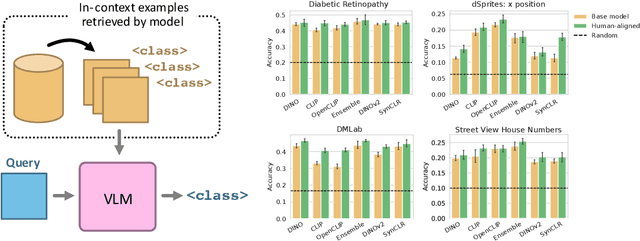
Humans judge perceptual similarity according to diverse visual attributes, including scene layout, subject location, and camera pose. Existing vision models understand a wide range of semantic abstractions but improperly weigh these attributes and thus make inferences misaligned with human perception. While vision representations have previously benefited from alignment in contexts like image generation, the utility of perceptually aligned representations in more general-purpose settings remains unclear. Here, we investigate how aligning vision model representations to human perceptual judgments impacts their usability across diverse computer vision tasks. We finetune state-of-the-art models on human similarity judgments for image triplets and evaluate them across standard vision benchmarks. We find that aligning models to perceptual judgments yields representations that improve upon the original backbones across many downstream tasks, including counting, segmentation, depth estimation, instance retrieval, and retrieval-augmented generation. In addition, we find that performance is widely preserved on other tasks, including specialized out-of-distribution domains such as in medical imaging and 3D environment frames. Our results suggest that injecting an inductive bias about human perceptual knowledge into vision models can contribute to better representations.
Aligning Machine and Human Visual Representations across Abstraction Levels
Sep 10, 2024



Deep neural networks have achieved success across a wide range of applications, including as models of human behavior in vision tasks. However, neural network training and human learning differ in fundamental ways, and neural networks often fail to generalize as robustly as humans do, raising questions regarding the similarity of their underlying representations. What is missing for modern learning systems to exhibit more human-like behavior? We highlight a key misalignment between vision models and humans: whereas human conceptual knowledge is hierarchically organized from fine- to coarse-scale distinctions, model representations do not accurately capture all these levels of abstraction. To address this misalignment, we first train a teacher model to imitate human judgments, then transfer human-like structure from its representations into pretrained state-of-the-art vision foundation models. These human-aligned models more accurately approximate human behavior and uncertainty across a wide range of similarity tasks, including a new dataset of human judgments spanning multiple levels of semantic abstractions. They also perform better on a diverse set of machine learning tasks, increasing generalization and out-of-distribution robustness. Thus, infusing neural networks with additional human knowledge yields a best-of-both-worlds representation that is both more consistent with human cognition and more practically useful, thus paving the way toward more robust, interpretable, and human-like artificial intelligence systems.
Dimensions underlying the representational alignment of deep neural networks with humans
Jun 27, 2024Determining the similarities and differences between humans and artificial intelligence is an important goal both in machine learning and cognitive neuroscience. However, similarities in representations only inform us about the degree of alignment, not the factors that determine it. Drawing upon recent developments in cognitive science, we propose a generic framework for yielding comparable representations in humans and deep neural networks (DNN). Applying this framework to humans and a DNN model of natural images revealed a low-dimensional DNN embedding of both visual and semantic dimensions. In contrast to humans, DNNs exhibited a clear dominance of visual over semantic features, indicating divergent strategies for representing images. While in-silico experiments showed seemingly-consistent interpretability of DNN dimensions, a direct comparison between human and DNN representations revealed substantial differences in how they process images. By making representations directly comparable, our results reveal important challenges for representational alignment, offering a means for improving their comparability.
Getting aligned on representational alignment
Nov 02, 2023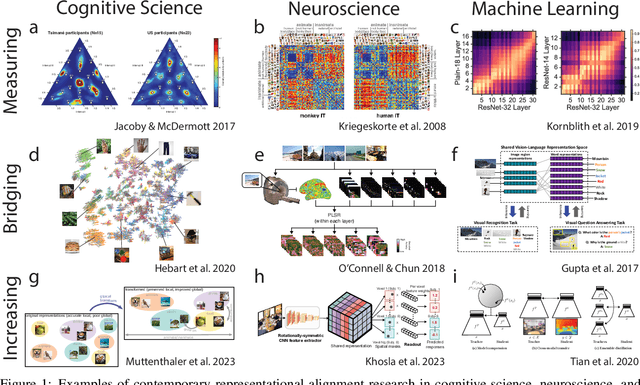
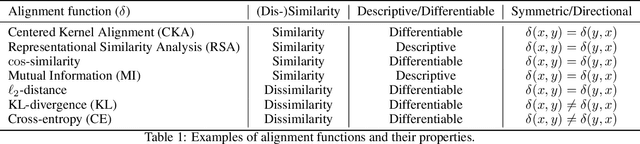
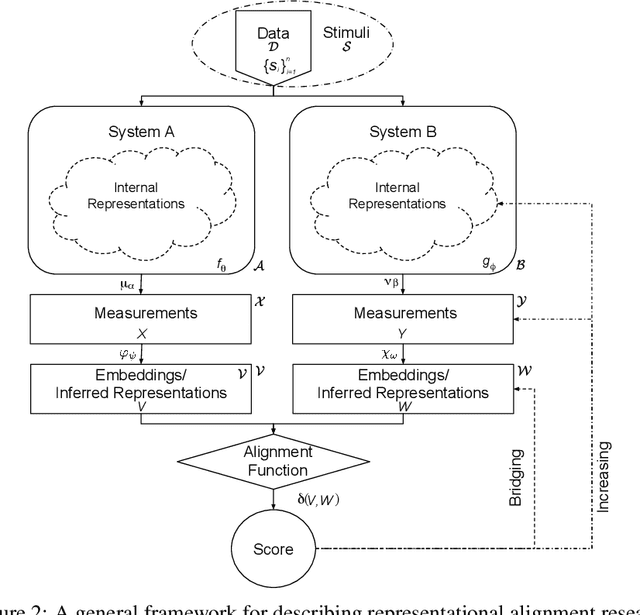
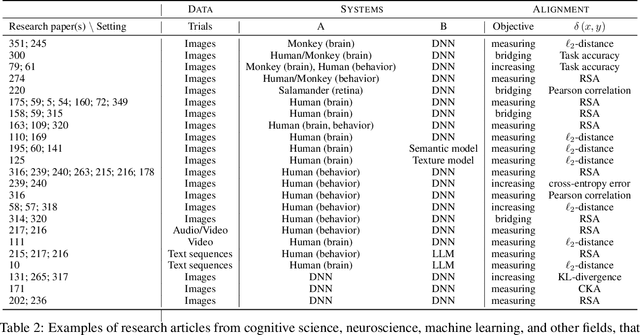
Biological and artificial information processing systems form representations that they can use to categorize, reason, plan, navigate, and make decisions. How can we measure the extent to which the representations formed by these diverse systems agree? Do similarities in representations then translate into similar behavior? How can a system's representations be modified to better match those of another system? These questions pertaining to the study of representational alignment are at the heart of some of the most active research areas in cognitive science, neuroscience, and machine learning. For example, cognitive scientists measure the representational alignment of multiple individuals to identify shared cognitive priors, neuroscientists align fMRI responses from multiple individuals into a shared representational space for group-level analyses, and ML researchers distill knowledge from teacher models into student models by increasing their alignment. Unfortunately, there is limited knowledge transfer between research communities interested in representational alignment, so progress in one field often ends up being rediscovered independently in another. Thus, greater cross-field communication would be advantageous. To improve communication between these fields, we propose a unifying framework that can serve as a common language between researchers studying representational alignment. We survey the literature from all three fields and demonstrate how prior work fits into this framework. Finally, we lay out open problems in representational alignment where progress can benefit all three of these fields. We hope that our work can catalyze cross-disciplinary collaboration and accelerate progress for all communities studying and developing information processing systems. We note that this is a working paper and encourage readers to reach out with their suggestions for future revisions.
Set Learning for Accurate and Calibrated Models
Jul 10, 2023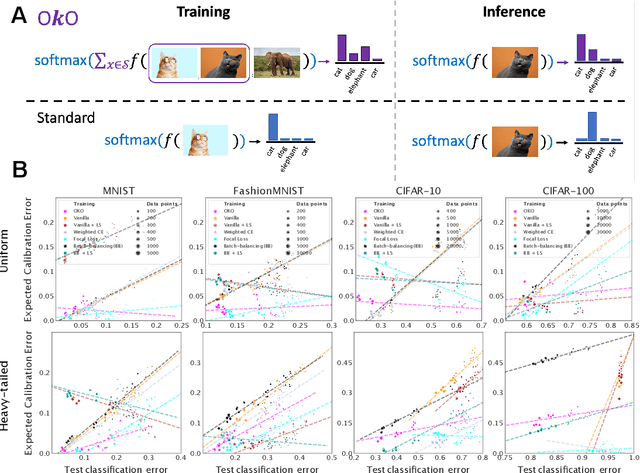
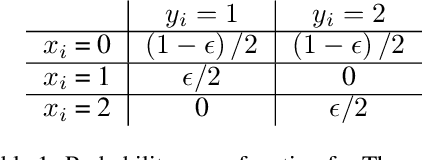
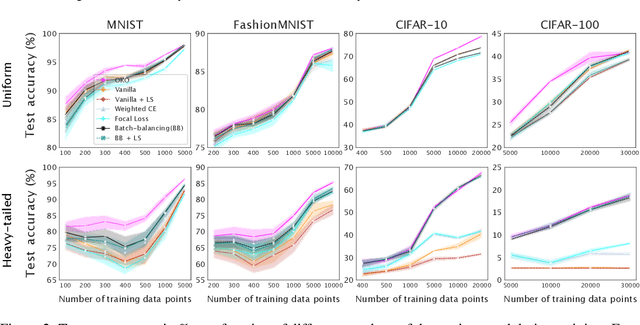
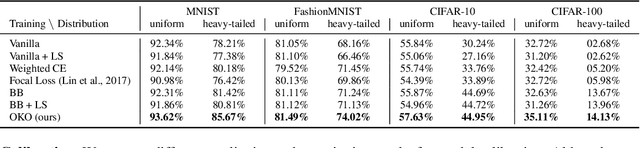
Model overconfidence and poor calibration are common in machine learning and difficult to account for when applying standard empirical risk minimization. In this work, we propose a novel method to alleviate these problems that we call odd-$k$-out learning (OKO), which minimizes the cross-entropy error for sets rather than for single examples. This naturally allows the model to capture correlations across data examples and achieves both better accuracy and calibration, especially in limited training data and class-imbalanced regimes. Perhaps surprisingly, OKO often yields better calibration even when training with hard labels and dropping any additional calibration parameter tuning, such as temperature scaling. We provide theoretical justification, establishing that OKO naturally yields better calibration, and provide extensive experimental analyses that corroborate our theoretical findings. We emphasize that OKO is a general framework that can be easily adapted to many settings and the trained model can be applied to single examples at inference time, without introducing significant run-time overhead or architecture changes.
Improving neural network representations using human similarity judgments
Jun 07, 2023Deep neural networks have reached human-level performance on many computer vision tasks. However, the objectives used to train these networks enforce only that similar images are embedded at similar locations in the representation space, and do not directly constrain the global structure of the resulting space. Here, we explore the impact of supervising this global structure by linearly aligning it with human similarity judgments. We find that a naive approach leads to large changes in local representational structure that harm downstream performance. Thus, we propose a novel method that aligns the global structure of representations while preserving their local structure. This global-local transform considerably improves accuracy across a variety of few-shot learning and anomaly detection tasks. Our results indicate that human visual representations are globally organized in a way that facilitates learning from few examples, and incorporating this global structure into neural network representations improves performance on downstream tasks.
Human alignment of neural network representations
Nov 21, 2022Today's computer vision models achieve human or near-human level performance across a wide variety of vision tasks. However, their architectures, data, and learning algorithms differ in numerous ways from those that give rise to human vision. In this paper, we investigate the factors that affect alignment between the representations learned by neural networks and human concept representations. Human representations are inferred from behavioral responses in an odd-one-out triplet task, where humans were presented with three images and had to select the odd-one-out. We find that model scale and architecture have essentially no effect on alignment with human behavioral responses, whereas the training dataset and objective function have a much larger impact. Using a sparse Bayesian model of human conceptual representations, we partition triplets by the concept that distinguishes the two similar images from the odd-one-out, finding that some concepts such as food and animals are well-represented in neural network representations whereas others such as royal or sports-related objects are not. Overall, although models trained on larger, more diverse datasets achieve better alignment with humans than models trained on ImageNet alone, our results indicate that scaling alone is unlikely to be sufficient to train neural networks with conceptual representations that match those used by humans.