 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeaching Models to Teach Themselves: Reasoning at the Edge of Learnability
Jan 26, 2026Can a model learn to escape its own learning plateau? Reinforcement learning methods for finetuning large reasoning models stall on datasets with low initial success rates, and thus little training signal. We investigate a fundamental question: Can a pretrained LLM leverage latent knowledge to generate an automated curriculum for problems it cannot solve? To explore this, we design SOAR: A self-improvement framework designed to surface these pedagogical signals through meta-RL. A teacher copy of the model proposes synthetic problems for a student copy, and is rewarded with its improvement on a small subset of hard problems. Critically, SOAR grounds the curriculum in measured student progress rather than intrinsic proxy rewards. Our study on the hardest subsets of mathematical benchmarks (0/128 success) reveals three core findings. First, we show that it is possible to realize bi-level meta-RL that unlocks learning under sparse, binary rewards by sharpening a latent capacity of pretrained models to generate useful stepping stones. Second, grounded rewards outperform intrinsic reward schemes used in prior LLM self-play, reliably avoiding the instability and diversity collapse modes they typically exhibit. Third, analyzing the generated questions reveals that structural quality and well-posedness are more critical for learning progress than solution correctness. Our results suggest that the ability to generate useful stepping stones does not require the preexisting ability to actually solve the hard problems, paving a principled path to escape reasoning plateaus without additional curated data.
What Makes for a Good Stereoscopic Image?
Dec 30, 2024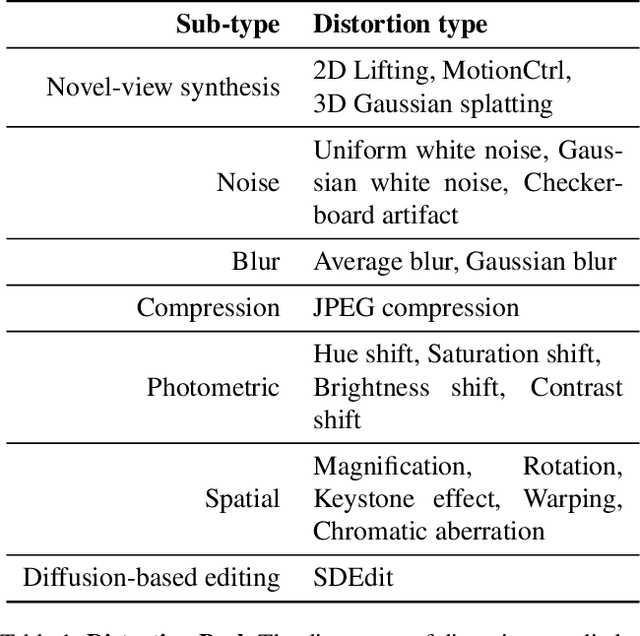

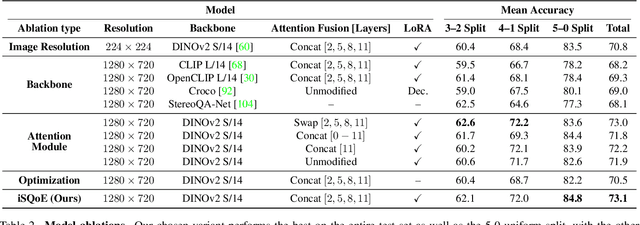
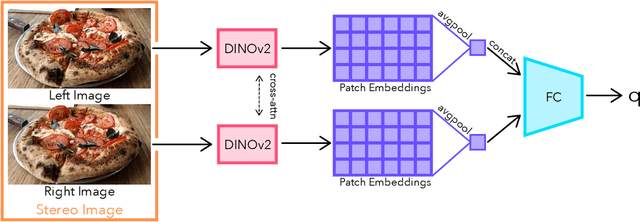
With rapid advancements in virtual reality (VR) headsets, effectively measuring stereoscopic quality of experience (SQoE) has become essential for delivering immersive and comfortable 3D experiences. However, most existing stereo metrics focus on isolated aspects of the viewing experience such as visual discomfort or image quality, and have traditionally faced data limitations. To address these gaps, we present SCOPE (Stereoscopic COntent Preference Evaluation), a new dataset comprised of real and synthetic stereoscopic images featuring a wide range of common perceptual distortions and artifacts. The dataset is labeled with preference annotations collected on a VR headset, with our findings indicating a notable degree of consistency in user preferences across different headsets. Additionally, we present iSQoE, a new model for stereo quality of experience assessment trained on our dataset. We show that iSQoE aligns better with human preferences than existing methods when comparing mono-to-stereo conversion methods.
Personalized Representation from Personalized Generation
Dec 20, 2024Modern vision models excel at general purpose downstream tasks. It is unclear, however, how they may be used for personalized vision tasks, which are both fine-grained and data-scarce. Recent works have successfully applied synthetic data to general-purpose representation learning, while advances in T2I diffusion models have enabled the generation of personalized images from just a few real examples. Here, we explore a potential connection between these ideas, and formalize the challenge of using personalized synthetic data to learn personalized representations, which encode knowledge about an object of interest and may be flexibly applied to any downstream task relating to the target object. We introduce an evaluation suite for this challenge, including reformulations of two existing datasets and a novel dataset explicitly constructed for this purpose, and propose a contrastive learning approach that makes creative use of image generators. We show that our method improves personalized representation learning for diverse downstream tasks, from recognition to segmentation, and analyze characteristics of image generation approaches that are key to this gain.
When Does Perceptual Alignment Benefit Vision Representations?
Oct 14, 2024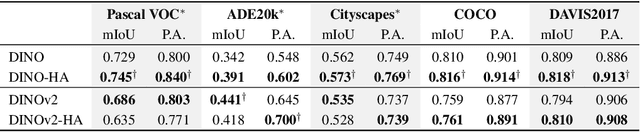
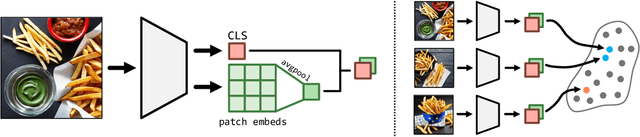
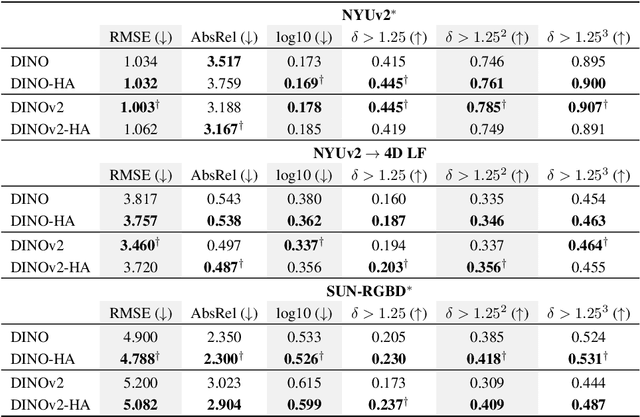
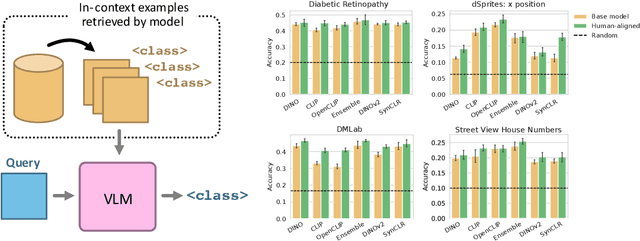
Humans judge perceptual similarity according to diverse visual attributes, including scene layout, subject location, and camera pose. Existing vision models understand a wide range of semantic abstractions but improperly weigh these attributes and thus make inferences misaligned with human perception. While vision representations have previously benefited from alignment in contexts like image generation, the utility of perceptually aligned representations in more general-purpose settings remains unclear. Here, we investigate how aligning vision model representations to human perceptual judgments impacts their usability across diverse computer vision tasks. We finetune state-of-the-art models on human similarity judgments for image triplets and evaluate them across standard vision benchmarks. We find that aligning models to perceptual judgments yields representations that improve upon the original backbones across many downstream tasks, including counting, segmentation, depth estimation, instance retrieval, and retrieval-augmented generation. In addition, we find that performance is widely preserved on other tasks, including specialized out-of-distribution domains such as in medical imaging and 3D environment frames. Our results suggest that injecting an inductive bias about human perceptual knowledge into vision models can contribute to better representations.
DreamSim: Learning New Dimensions of Human Visual Similarity using Synthetic Data
Jun 26, 2023Current perceptual similarity metrics operate at the level of pixels and patches. These metrics compare images in terms of their low-level colors and textures, but fail to capture mid-level similarities and differences in image layout, object pose, and semantic content. In this paper, we develop a perceptual metric that assesses images holistically. Our first step is to collect a new dataset of human similarity judgments over image pairs that are alike in diverse ways. Critical to this dataset is that judgments are nearly automatic and shared by all observers. To achieve this we use recent text-to-image models to create synthetic pairs that are perturbed along various dimensions. We observe that popular perceptual metrics fall short of explaining our new data, and we introduce a new metric, DreamSim, tuned to better align with human perception. We analyze how our metric is affected by different visual attributes, and find that it focuses heavily on foreground objects and semantic content while also being sensitive to color and layout. Notably, despite being trained on synthetic data, our metric generalizes to real images, giving strong results on retrieval and reconstruction tasks. Furthermore, our metric outperforms both prior learned metrics and recent large vision models on these tasks.
Do Neural Networks for Segmentation Understand Insideness?
Jan 25, 2022The insideness problem is an aspect of image segmentation that consists of determining which pixels are inside and outside a region. Deep Neural Networks (DNNs) excel in segmentation benchmarks, but it is unclear if they have the ability to solve the insideness problem as it requires evaluating long-range spatial dependencies. In this paper, the insideness problem is analysed in isolation, without texture or semantic cues, such that other aspects of segmentation do not interfere in the analysis. We demonstrate that DNNs for segmentation with few units have sufficient complexity to solve insideness for any curve. Yet, such DNNs have severe problems with learning general solutions. Only recurrent networks trained with small images learn solutions that generalize well to almost any curve. Recurrent networks can decompose the evaluation of long-range dependencies into a sequence of local operations, and learning with small images alleviates the common difficulties of training recurrent networks with a large number of unrolling steps.
Symmetry Perception by Deep Networks: Inadequacy of Feed-Forward Architectures and Improvements with Recurrent Connections
Dec 08, 2021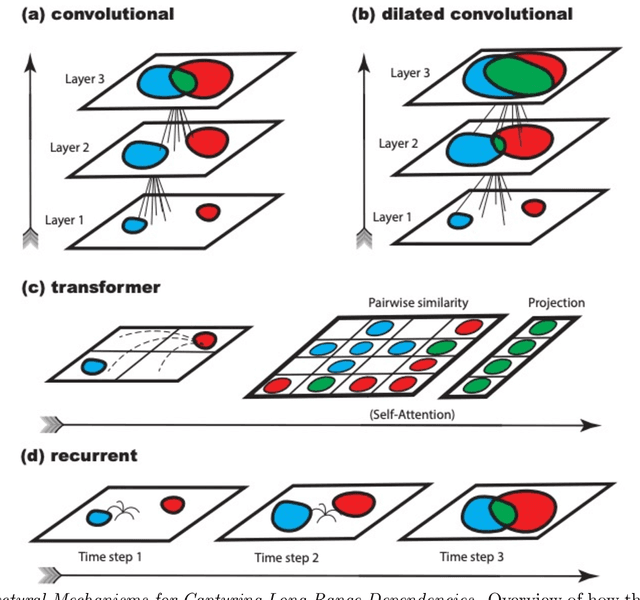

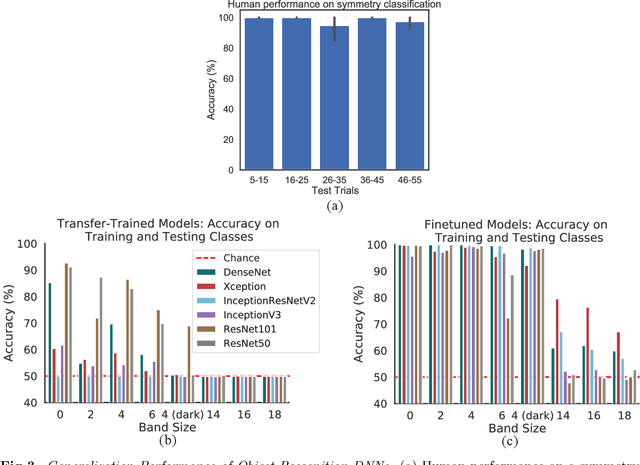
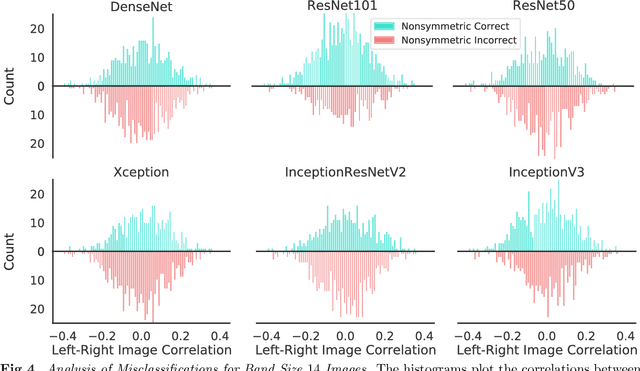
Symmetry is omnipresent in nature and perceived by the visual system of many species, as it facilitates detecting ecologically important classes of objects in our environment. Symmetry perception requires abstraction of non-local spatial dependencies between image regions, and its underlying neural mechanisms remain elusive. In this paper, we evaluate Deep Neural Network (DNN) architectures on the task of learning symmetry perception from examples. We demonstrate that feed-forward DNNs that excel at modelling human performance on object recognition tasks, are unable to acquire a general notion of symmetry. This is the case even when the DNNs are architected to capture non-local spatial dependencies, such as through `dilated' convolutions and the recently introduced `transformers' design. By contrast, we find that recurrent architectures are capable of learning to perceive symmetry by decomposing the non-local spatial dependencies into a sequence of local operations, that are reusable for novel images. These results suggest that recurrent connections likely play an important role in symmetry perception in artificial systems, and possibly, biological ones too.
GAN-based Data Augmentation for Chest X-ray Classification
Jul 07, 2021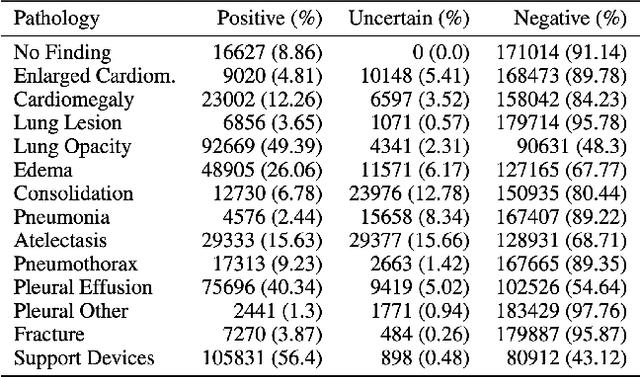
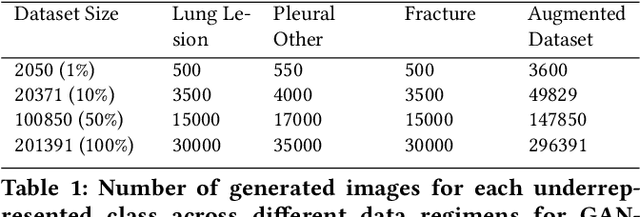
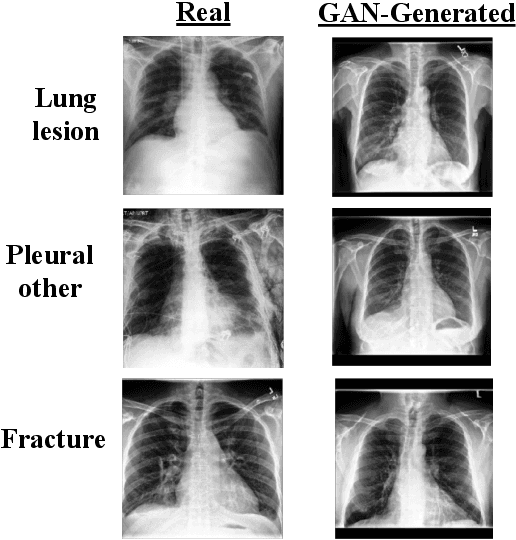
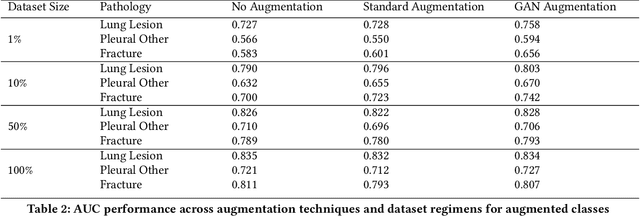
A common problem in computer vision -- particularly in medical applications -- is a lack of sufficiently diverse, large sets of training data. These datasets often suffer from severe class imbalance. As a result, networks often overfit and are unable to generalize to novel examples. Generative Adversarial Networks (GANs) offer a novel method of synthetic data augmentation. In this work, we evaluate the use of GAN- based data augmentation to artificially expand the CheXpert dataset of chest radiographs. We compare performance to traditional augmentation and find that GAN-based augmentation leads to higher downstream performance for underrepresented classes. Furthermore, we see that this result is pronounced in low data regimens. This suggests that GAN-based augmentation a promising area of research to improve network performance when data collection is prohibitively expensive.