 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMerge to Mix: Mixing Datasets via Model Merging
May 21, 2025Mixing datasets for fine-tuning large models (LMs) has become critical for maximizing performance on downstream tasks. However, composing effective dataset mixtures typically relies on heuristics and trial-and-error, often requiring multiple fine-tuning runs to achieve the desired outcome. We propose a novel method, $\textit{Merge to Mix}$, that accelerates composing dataset mixtures through model merging. Model merging is a recent technique that combines the abilities of multiple individually fine-tuned LMs into a single LM by using a few simple arithmetic operations. Our key insight is that merging models individually fine-tuned on each dataset in a mixture can effectively serve as a surrogate for a model fine-tuned on the entire mixture. Merge to Mix leverages this insight to accelerate selecting dataset mixtures without requiring full fine-tuning on each candidate mixture. Our experiments demonstrate that Merge to Mix surpasses state-of-the-art methods in dataset selection for fine-tuning LMs.
Task Arithmetic Through The Lens Of One-Shot Federated Learning
Nov 27, 2024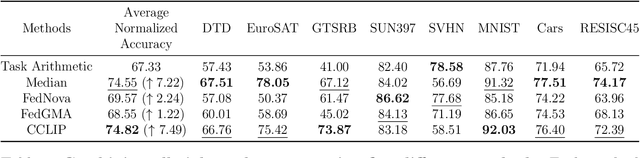
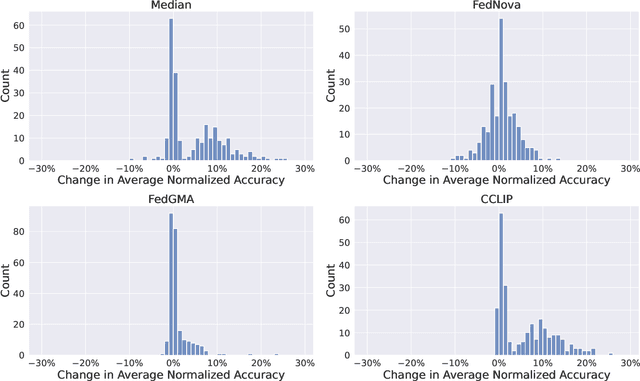
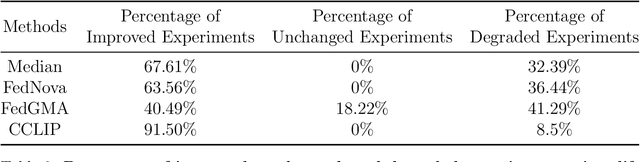
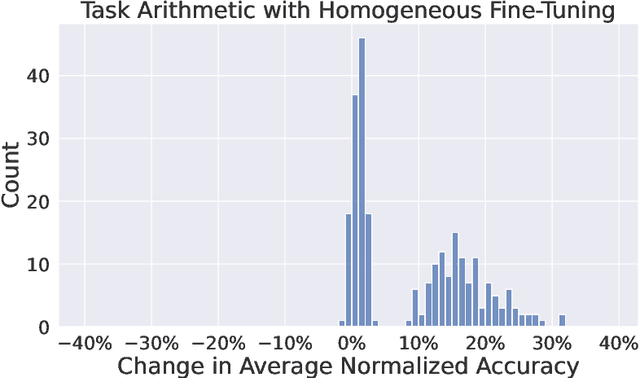
Task Arithmetic is a model merging technique that enables the combination of multiple models' capabilities into a single model through simple arithmetic in the weight space, without the need for additional fine-tuning or access to the original training data. However, the factors that determine the success of Task Arithmetic remain unclear. In this paper, we examine Task Arithmetic for multi-task learning by framing it as a one-shot Federated Learning problem. We demonstrate that Task Arithmetic is mathematically equivalent to the commonly used algorithm in Federated Learning, called Federated Averaging (FedAvg). By leveraging well-established theoretical results from FedAvg, we identify two key factors that impact the performance of Task Arithmetic: data heterogeneity and training heterogeneity. To mitigate these challenges, we adapt several algorithms from Federated Learning to improve the effectiveness of Task Arithmetic. Our experiments demonstrate that applying these algorithms can often significantly boost performance of the merged model compared to the original Task Arithmetic approach. This work bridges Task Arithmetic and Federated Learning, offering new theoretical perspectives on Task Arithmetic and improved practical methodologies for model merging.
Configural processing as an optimized strategy for robust object recognition in neural networks
Jul 18, 2024



Configural processing, the perception of spatial relationships among an object's components, is crucial for object recognition. However, the teleology and underlying neurocomputational mechanisms of such processing are still elusive, notwithstanding decades of research. We hypothesized that processing objects via configural cues provides a more robust means to recognizing them relative to local featural cues. We evaluated this hypothesis by devising identification tasks with composite letter stimuli and comparing different neural network models trained with either only local or configural cues available. We found that configural cues yielded more robust performance to geometric transformations such as rotation or scaling. Furthermore, when both features were simultaneously available, configural cues were favored over local featural cues. Layerwise analysis revealed that the sensitivity to configural cues emerged later relative to local feature cues, possibly contributing to the robustness to pixel-level transformations. Notably, this configural processing occurred in a purely feedforward manner, without the need for recurrent computations. Our findings with letter stimuli were successfully extended to naturalistic face images. Thus, our study provides neurocomputational evidence that configural processing emerges in a na\"ive network based on task contingencies, and is beneficial for robust object processing under varying viewing conditions.
Multi-domain improves out-of-distribution and data-limited scenarios for medical image analysis
Oct 10, 2023Current machine learning methods for medical image analysis primarily focus on developing models tailored for their specific tasks, utilizing data within their target domain. These specialized models tend to be data-hungry and often exhibit limitations in generalizing to out-of-distribution samples. Recently, foundation models have been proposed, which combine data from various domains and demonstrate excellent generalization capabilities. Building upon this, this work introduces the incorporation of diverse medical image domains, including different imaging modalities like X-ray, MRI, CT, and ultrasound images, as well as various viewpoints such as axial, coronal, and sagittal views. We refer to this approach as multi-domain model and compare its performance to that of specialized models. Our findings underscore the superior generalization capabilities of multi-domain models, particularly in scenarios characterized by limited data availability and out-of-distribution, frequently encountered in healthcare applications. The integration of diverse data allows multi-domain models to utilize shared information across domains, enhancing the overall outcomes significantly. To illustrate, for organ recognition, multi-domain model can enhance accuracy by up to 10% compared to conventional specialized models.
D3: Data Diversity Design for Systematic Generalization in Visual Question Answering
Sep 15, 2023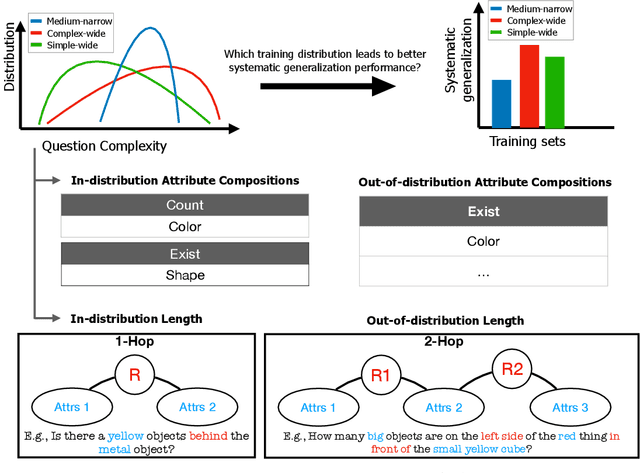


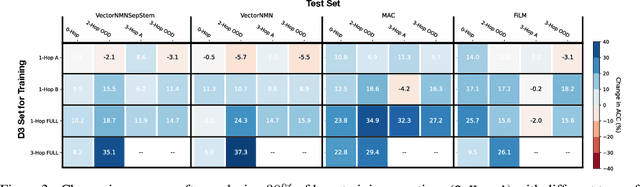
Systematic generalization is a crucial aspect of intelligence, which refers to the ability to generalize to novel tasks by combining known subtasks and concepts. One critical factor that has been shown to influence systematic generalization is the diversity of training data. However, diversity can be defined in various ways, as data have many factors of variation. A more granular understanding of how different aspects of data diversity affect systematic generalization is lacking. We present new evidence in the problem of Visual Question Answering (VQA) that reveals that the diversity of simple tasks (i.e. tasks formed by a few subtasks and concepts) plays a key role in achieving systematic generalization. This implies that it may not be essential to gather a large and varied number of complex tasks, which could be costly to obtain. We demonstrate that this result is independent of the similarity between the training and testing data and applies to well-known families of neural network architectures for VQA (i.e. monolithic architectures and neural module networks). Additionally, we observe that neural module networks leverage all forms of data diversity we evaluated, while monolithic architectures require more extensive amounts of data to do so. These findings provide a first step towards understanding the interactions between data diversity design, neural network architectures, and systematic generalization capabilities.
Modularity Trumps Invariance for Compositional Robustness
Jun 15, 2023
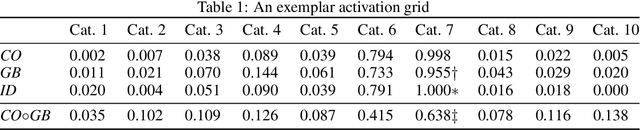
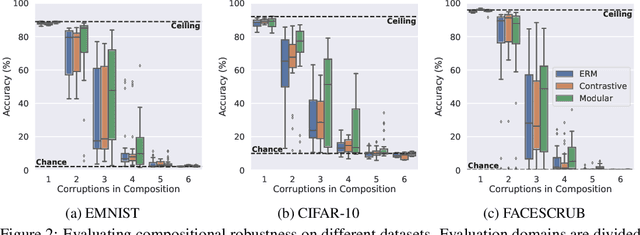
By default neural networks are not robust to changes in data distribution. This has been demonstrated with simple image corruptions, such as blurring or adding noise, degrading image classification performance. Many methods have been proposed to mitigate these issues but for the most part models are evaluated on single corruptions. In reality, visual space is compositional in nature, that is, that as well as robustness to elemental corruptions, robustness to compositions of corruptions is also needed. In this work we develop a compositional image classification task where, given a few elemental corruptions, models are asked to generalize to compositions of these corruptions. That is, to achieve compositional robustness. We experimentally compare empirical risk minimization with an invariance building pairwise contrastive loss and, counter to common intuitions in domain generalization, achieve only marginal improvements in compositional robustness by encouraging invariance. To move beyond invariance, following previously proposed inductive biases that model architectures should reflect data structure, we introduce a modular architecture whose structure replicates the compositional nature of the task. We then show that this modular approach consistently achieves better compositional robustness than non-modular approaches. We additionally find empirical evidence that the degree of invariance between representations of 'in-distribution' elemental corruptions fails to correlate with robustness to 'out-of-distribution' compositions of corruptions.
Deephys: Deep Electrophysiology, Debugging Neural Networks under Distribution Shifts
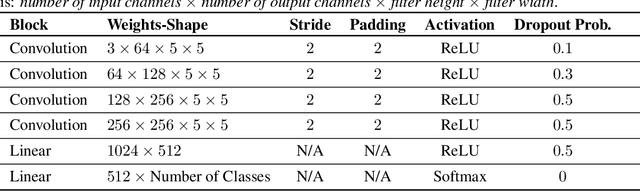
Mar 17, 2023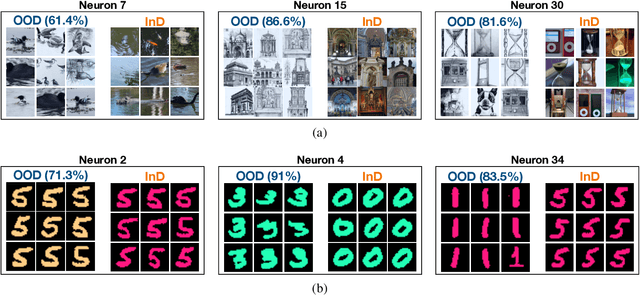
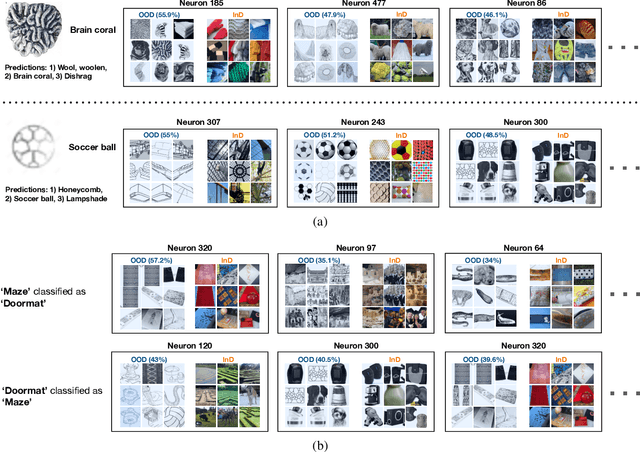
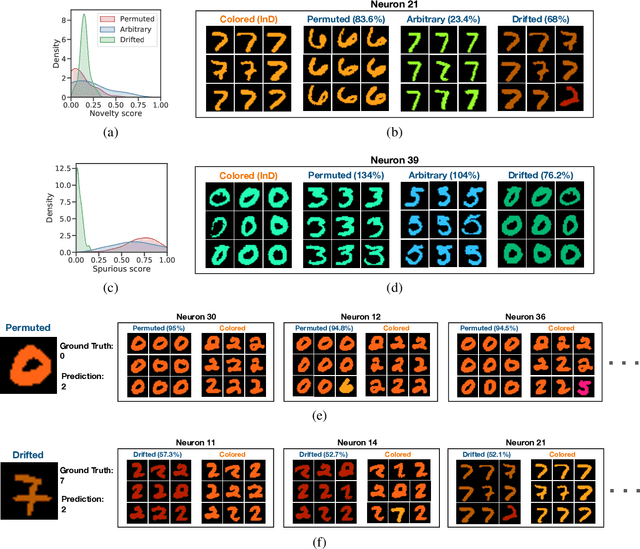
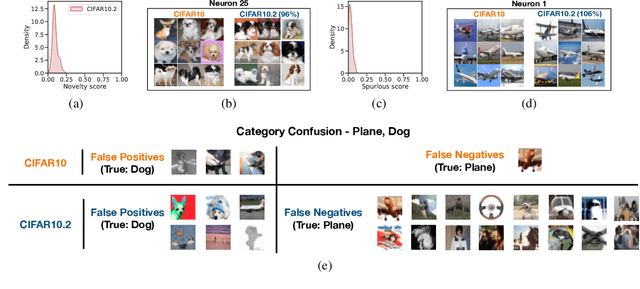
Deep Neural Networks (DNNs) often fail in out-of-distribution scenarios. In this paper, we introduce a tool to visualize and understand such failures. We draw inspiration from concepts from neural electrophysiology, which are based on inspecting the internal functioning of a neural networks by analyzing the feature tuning and invariances of individual units. Deep Electrophysiology, in short Deephys, provides insights of the DNN's failures in out-of-distribution scenarios by comparative visualization of the neural activity in in-distribution and out-of-distribution datasets. Deephys provides seamless analyses of individual neurons, individual images, and a set of set of images from a category, and it is capable of revealing failures due to the presence of spurious features and novel features. We substantiate the validity of the qualitative visualizations of Deephys thorough quantitative analyses using convolutional and transformers architectures, in several datasets and distribution shifts (namely, colored MNIST, CIFAR-10 and ImageNet).
Transformer Module Networks for Systematic Generalization in Visual Question Answering
Jan 27, 2022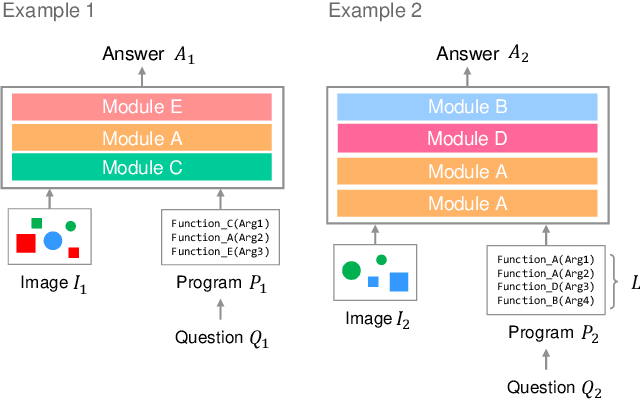
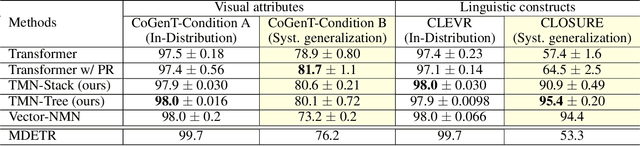
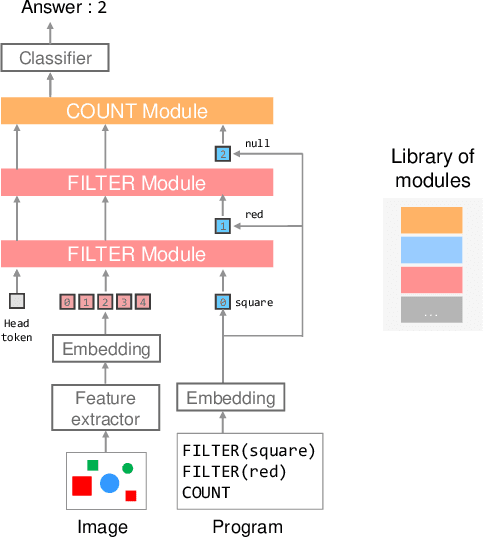

Transformer-based models achieve great performance on Visual Question Answering (VQA). However, when we evaluate them on systematic generalization, i.e., handling novel combinations of known concepts, their performance degrades. Neural Module Networks (NMNs) are a promising approach for systematic generalization that consists on composing modules, i.e., neural networks that tackle a sub-task. Inspired by Transformers and NMNs, we propose Transformer Module Network (TMN), a novel Transformer-based model for VQA that dynamically composes modules into a question-specific Transformer network. TMNs achieve state-of-the-art systematic generalization performance in three VQA datasets, namely, CLEVR-CoGenT, CLOSURE and GQA-SGL, in some cases improving more than 30% over standard Transformers.
Do Neural Networks for Segmentation Understand Insideness?
Jan 25, 2022The insideness problem is an aspect of image segmentation that consists of determining which pixels are inside and outside a region. Deep Neural Networks (DNNs) excel in segmentation benchmarks, but it is unclear if they have the ability to solve the insideness problem as it requires evaluating long-range spatial dependencies. In this paper, the insideness problem is analysed in isolation, without texture or semantic cues, such that other aspects of segmentation do not interfere in the analysis. We demonstrate that DNNs for segmentation with few units have sufficient complexity to solve insideness for any curve. Yet, such DNNs have severe problems with learning general solutions. Only recurrent networks trained with small images learn solutions that generalize well to almost any curve. Recurrent networks can decompose the evaluation of long-range dependencies into a sequence of local operations, and learning with small images alleviates the common difficulties of training recurrent networks with a large number of unrolling steps.
A Robust Optimization Approach to Deep Learning
Dec 17, 2021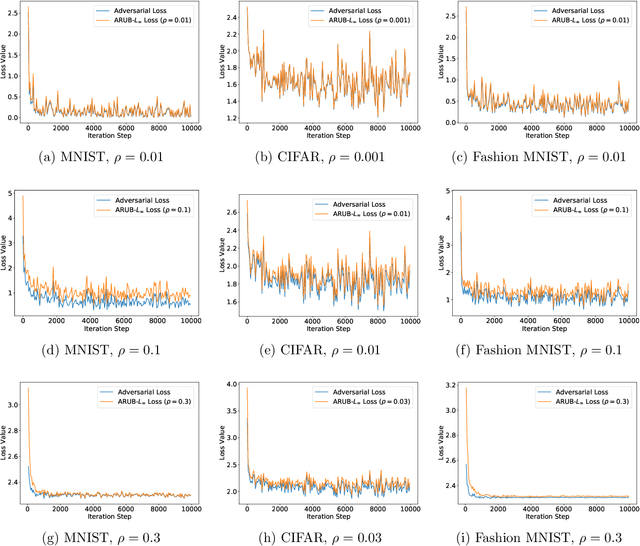

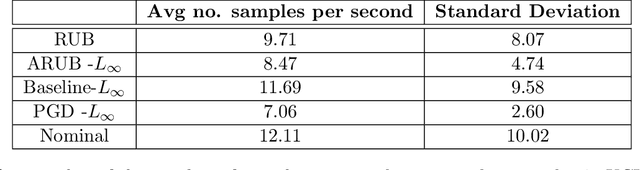
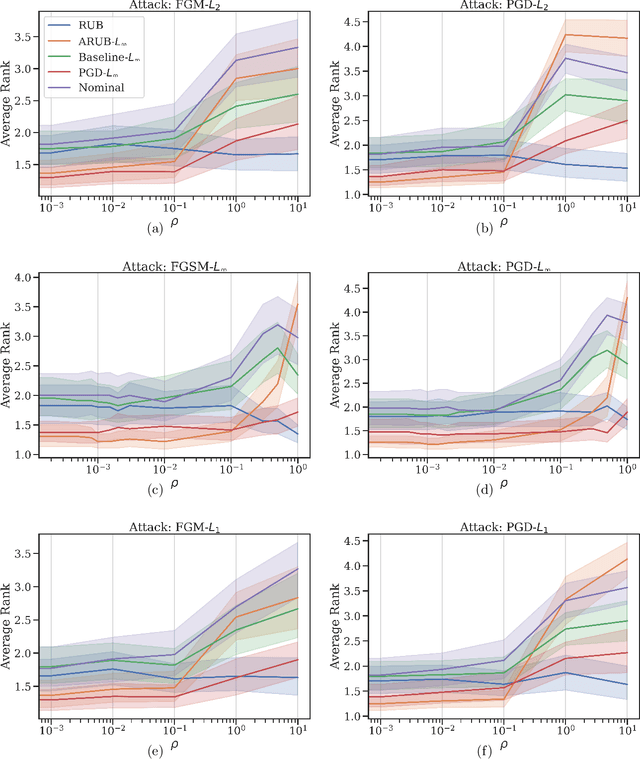
Many state-of-the-art adversarial training methods leverage upper bounds of the adversarial loss to provide security guarantees. Yet, these methods require computations at each training step that can not be incorporated in the gradient for backpropagation. We introduce a new, more principled approach to adversarial training based on a closed form solution of an upper bound of the adversarial loss, which can be effectively trained with backpropagation. This bound is facilitated by state-of-the-art tools from robust optimization. We derive two new methods with our approach. The first method (Approximated Robust Upper Bound or aRUB) uses the first order approximation of the network as well as basic tools from linear robust optimization to obtain an approximate upper bound of the adversarial loss that can be easily implemented. The second method (Robust Upper Bound or RUB), computes an exact upper bound of the adversarial loss. Across a variety of tabular and vision data sets we demonstrate the effectiveness of our more principled approach -- RUB is substantially more robust than state-of-the-art methods for larger perturbations, while aRUB matches the performance of state-of-the-art methods for small perturbations. Also, both RUB and aRUB run faster than standard adversarial training (at the expense of an increase in memory). All the code to reproduce the results can be found at https://github.com/kimvc7/Robustness.