 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimisation of Aircraft Maintenance Schedules
Dec 19, 2025


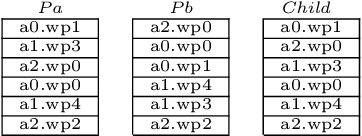
We present an aircraft maintenance scheduling problem, which requires suitably qualified staff to be assigned to maintenance tasks on each aircraft. The tasks on each aircraft must be completed within a given turn around window so that the aircraft may resume revenue earning service. This paper presents an initial study based on the application of an Evolutionary Algorithm to the problem. Evolutionary Algorithms evolve a solution to a problem by evaluating many possible solutions, focusing the search on those solutions that are of a higher quality, as defined by a fitness function. In this paper, we benchmark the algorithm on 60 generated problem instances to demonstrate the underlying representation and associated genetic operators.
D3: Data Diversity Design for Systematic Generalization in Visual Question Answering
Sep 15, 2023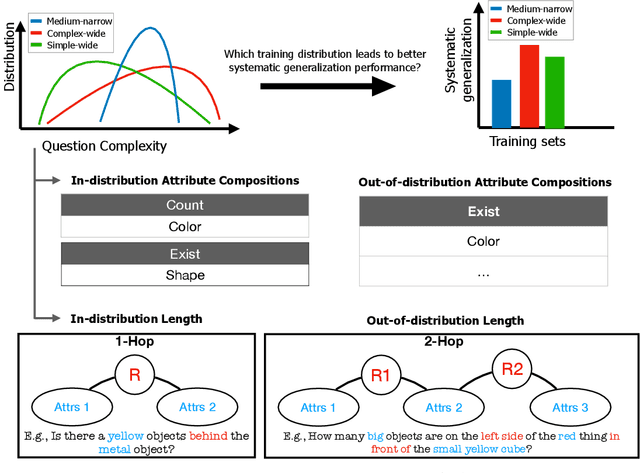


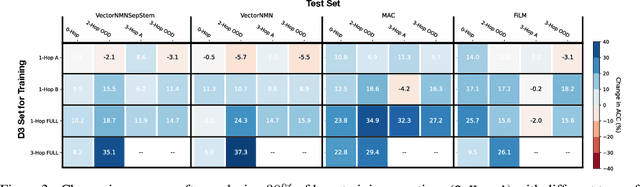
Systematic generalization is a crucial aspect of intelligence, which refers to the ability to generalize to novel tasks by combining known subtasks and concepts. One critical factor that has been shown to influence systematic generalization is the diversity of training data. However, diversity can be defined in various ways, as data have many factors of variation. A more granular understanding of how different aspects of data diversity affect systematic generalization is lacking. We present new evidence in the problem of Visual Question Answering (VQA) that reveals that the diversity of simple tasks (i.e. tasks formed by a few subtasks and concepts) plays a key role in achieving systematic generalization. This implies that it may not be essential to gather a large and varied number of complex tasks, which could be costly to obtain. We demonstrate that this result is independent of the similarity between the training and testing data and applies to well-known families of neural network architectures for VQA (i.e. monolithic architectures and neural module networks). Additionally, we observe that neural module networks leverage all forms of data diversity we evaluated, while monolithic architectures require more extensive amounts of data to do so. These findings provide a first step towards understanding the interactions between data diversity design, neural network architectures, and systematic generalization capabilities.
Semi-Supervised 3D Hand Shape and Pose Estimation with Label Propagation
Nov 30, 2021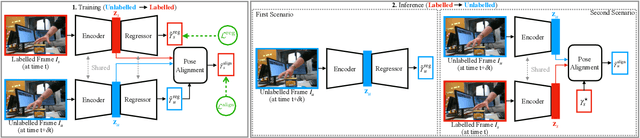
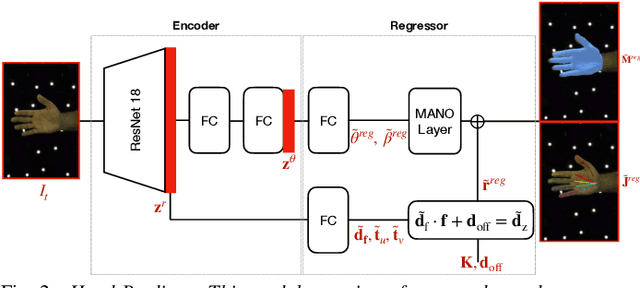
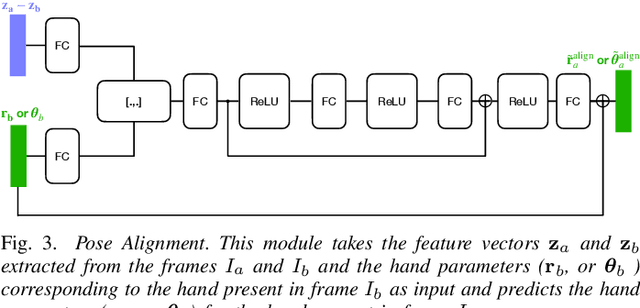

To obtain 3D annotations, we are restricted to controlled environments or synthetic datasets, leading us to 3D datasets with less generalizability to real-world scenarios. To tackle this issue in the context of semi-supervised 3D hand shape and pose estimation, we propose the Pose Alignment network to propagate 3D annotations from labelled frames to nearby unlabelled frames in sparsely annotated videos. We show that incorporating the alignment supervision on pairs of labelled-unlabelled frames allows us to improve the pose estimation accuracy. Besides, we show that the proposed Pose Alignment network can effectively propagate annotations on unseen sparsely labelled videos without fine-tuning.
CogSense: A Cognitively Inspired Framework for Perception Adaptation
Jul 22, 2021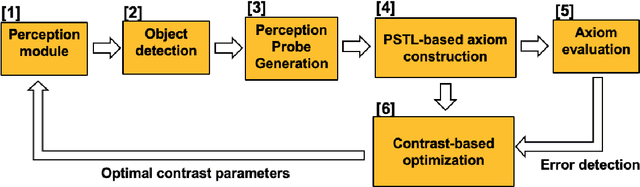
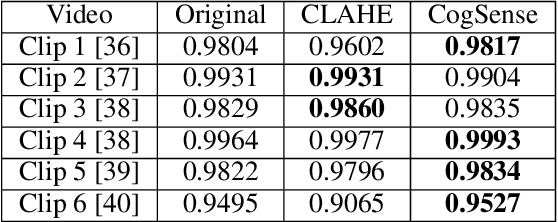

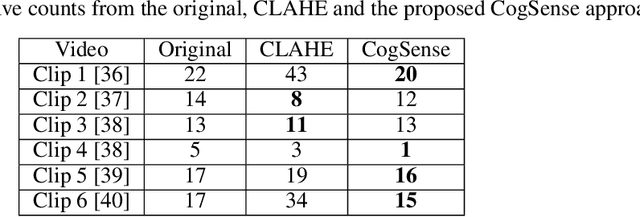
This paper proposes the CogSense system, which is inspired by sense-making cognition and perception in the mammalian brain to perform perception error detection and perception parameter adaptation using probabilistic signal temporal logic. As a specific application, a contrast-based perception adaption method is presented and validated. The proposed method evaluates perception errors using heterogeneous probe functions computed from the detected objects and subsequently solves a contrast optimization problem to correct perception errors. The CogSense probe functions utilize the characteristics of geometry, dynamics, and detected blob image quality of the objects to develop axioms in a probabilistic signal temporal logic framework. By evaluating these axioms, we can formally verify whether the detections are valid or erroneous. Further, using the CogSense axioms, we generate the probabilistic signal temporal logic-based constraints to finally solve the contrast-based optimization problem to reduce false positives and false negatives.
Few-shot Weakly-Supervised Object Detection via Directional Statistics
Mar 25, 2021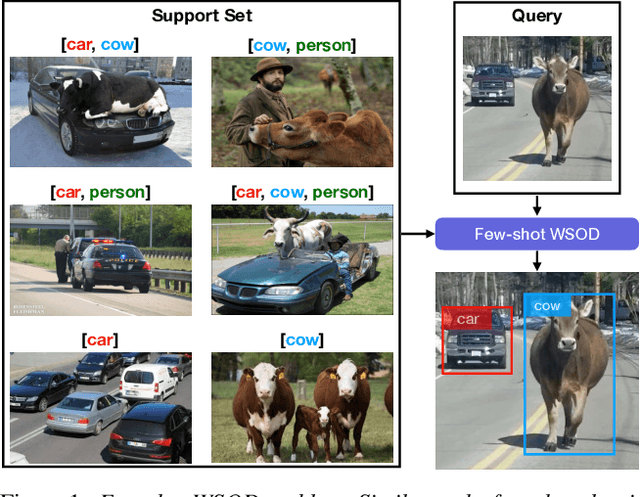
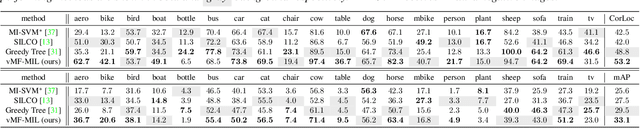
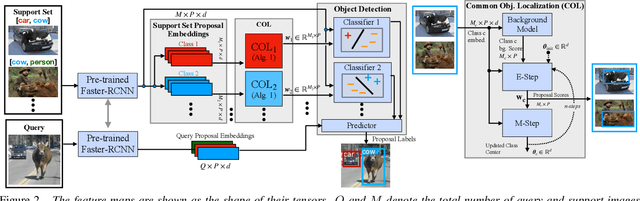

Detecting novel objects from few examples has become an emerging topic in computer vision recently. However, these methods need fully annotated training images to learn new object categories which limits their applicability in real world scenarios such as field robotics. In this work, we propose a probabilistic multiple instance learning approach for few-shot Common Object Localization (COL) and few-shot Weakly Supervised Object Detection (WSOD). In these tasks, only image-level labels, which are much cheaper to acquire, are available. We find that operating on features extracted from the last layer of a pre-trained Faster-RCNN is more effective compared to previous episodic learning based few-shot COL methods. Our model simultaneously learns the distribution of the novel objects and localizes them via expectation-maximization steps. As a probabilistic model, we employ von Mises-Fisher (vMF) distribution which captures the semantic information better than Gaussian distribution when applied to the pre-trained embedding space. When the novel objects are localized, we utilize them to learn a linear appearance model to detect novel classes in new images. Our extensive experiments show that the proposed method, despite being simple, outperforms strong baselines in few-shot COL and WSOD, as well as large-scale WSOD tasks.
Post-hoc Calibration of Neural Networks
Jun 23, 2020



Calibration of neural networks is a critical aspect to consider when incorporating machine learning models in real-world decision-making systems where the confidence of decisions are equally important as the decisions themselves. In recent years, there is a surge of research on neural network calibration and the majority of the works can be categorized into post-hoc calibration methods, defined as methods that learn an additional function to calibrate an already trained base network. In this work, we intend to understand the post-hoc calibration methods from a theoretical point of view. Especially, it is known that minimizing Negative Log-Likelihood (NLL) will lead to a calibrated network on the training set if the global optimum is attained (Bishop, 1994). Nevertheless, it is not clear learning an additional function in a post-hoc manner would lead to calibration in the theoretical sense. To this end, we prove that even though the base network ($f$) does not lead to the global optimum of NLL, by adding additional layers ($g$) and minimizing NLL by optimizing the parameters of $g$ one can obtain a calibrated network $g \circ f$. This not only provides a less stringent condition to obtain a calibrated network but also provides a theoretical justification of post-hoc calibration methods. Our experiments on various image classification benchmarks confirm the theory.
Calibration of Neural Networks using Splines
Jun 23, 2020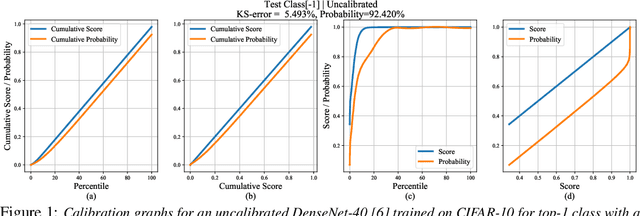
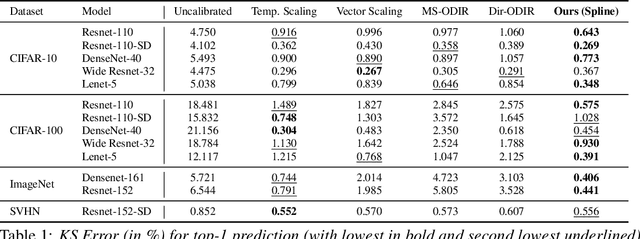
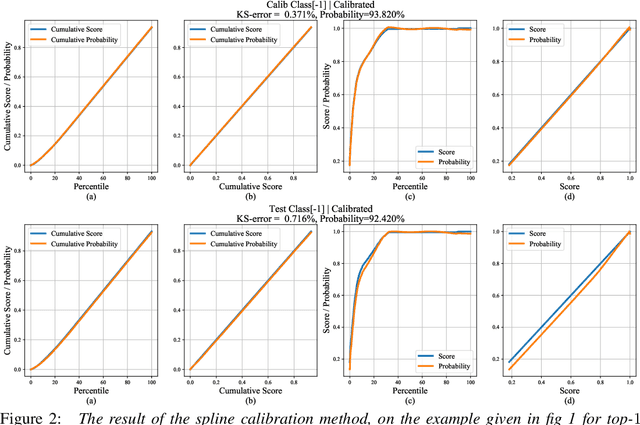

Calibrating neural networks is of utmost importance when employing them in safety-critical applications where the downstream decision making depends on the predicted probabilities. Measuring calibration error amounts to comparing two empirical distributions. In this work, we introduce a binning-free calibration measure inspired by the classical Kolmogorov-Smirnov (KS) statistical test in which the main idea is to compare the respective cumulative probability distributions. From this, by approximating the empirical cumulative distribution using a differentiable function via splines, we obtain a recalibration function, which maps the network outputs to actual (calibrated) class assignment probabilities. The spine-fitting is performed using a held-out calibration set and the obtained recalibration function is evaluated on an unseen test set. We tested our method against existing calibration approaches on various image classification datasets and our spline-based recalibration approach consistently outperforms existing methods on KS error as well as other commonly used calibration measures.
In Defense of Graph Inference Algorithms for Weakly Supervised Object Localization
Mar 18, 2020
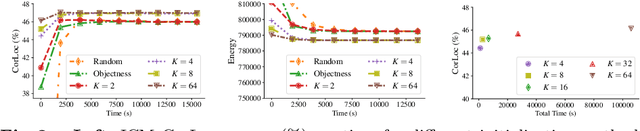


Weakly Supervised Object Localization (WSOL) methods have become increasingly popular since they only require image level labels as opposed to expensive bounding box annotations required by fully supervised algorithms. Typically, a WSOL model is first trained to predict class generic objectness scores on an off-the-shelf fully supervised source dataset and then it is progressively adapted to learn the objects in the weakly supervised target dataset. In this work, we argue that learning only an objectness function is a weak form of knowledge transfer and propose to learn a classwise pairwise similarity function that directly compares two input proposals as well. The combined localization model and the estimated object annotations are jointly learned in an alternating optimization paradigm as is typically done in standard WSOL methods. In contrast to the existing work that learns pairwise similarities, our proposed approach optimizes a unified objective with convergence guarantee and it is computationally efficient for large-scale applications. Experiments on the COCO and ILSVRC 2013 detection datasets show that the performance of the localization model improves significantly with the inclusion of pairwise similarity function. For instance, in the ILSVRC dataset, the Correct Localization (CorLoc) performance improves from 72.7% to 78.2% which is a new state-of-the-art for weakly supervised object localization task.
Intra Order-preserving Functions for Calibration of Multi-Class Neural Networks
Mar 15, 2020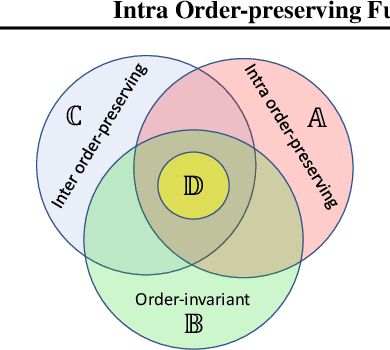

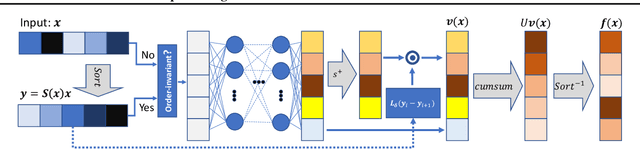

Predicting calibrated confidence scores for multi-class deep networks is important for avoiding rare but costly mistakes. A common approach is to learn a post-hoc calibration function that transforms the output of the original network into calibrated confidence scores while maintaining the network's accuracy. However, previous post-hoc calibration techniques work only with simple calibration functions, potentially lacking sufficient representation to calibrate the complex function landscape of deep networks. In this work, we aim to learn general post-hoc calibration functions that can preserve the top-k predictions of any deep network. We call this family of functions intra order-preserving functions. We propose a new neural network architecture that represents a class of intra order-preserving functions by combining common neural network components. Additionally, we introduce order-invariant and diagonal sub-families, which can act as regularization for better generalization when the training data size is small. We show the effectiveness of the proposed method across a wide range of datasets and classifiers. Our method outperforms state-of-the-art post-hoc calibration methods, namely temperature scaling and Dirichlet calibration, in multiple settings.
Learning to Find Common Objects Across Image Collections
Apr 29, 2019

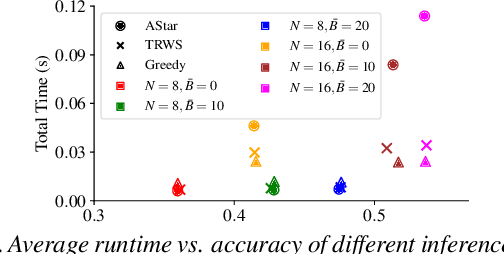
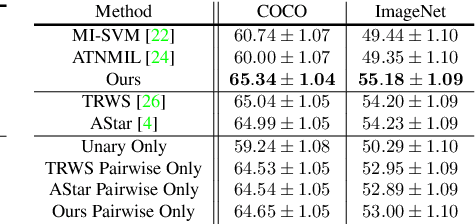
We address the problem of finding a set of images containing a common, but unknown, object category from a collection of image proposals. Our formulation assumes that we are given a collection of bags where each bag is a set of image proposals. Our goal is to select one image from each bag such that the selected images are of the same object category. We model the selection as an energy minimization problem with unary and pairwise potential functions. Inspired by recent few-shot learning algorithms, we propose an approach to learn the potential functions directly from the data. Furthermore, we propose a fast and simple greedy inference algorithm for energy minimization. We evaluate our approach on few-shot common object recognition and object co-localization tasks. Our experiments show that learning the pairwise and unary terms greatly improves the performance of the model over several well-known methods for these tasks. The proposed greedy optimization algorithm achieves performance comparable to state-of-the-art structured inference algorithms while being ~10 times faster. The code is publicly available on https://github.com/haamoon/finding_common_object.