 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Rate Diffusion: Accelerating diffusion models with an interleaved heavy-light network
May 18, 2026Diffusion models achieve state-of-the-art generative performance but suffer from high computational costs during inference due to the repeated evaluation of a heavy neural network. In this work, we propose Dual-Rate Diffusion, a method to accelerate sampling by interleaving the execution of a heavy high-capacity context encoder and a light efficient denoising model. The context encoder is evaluated sparsely to extract high-dimensional features, which are effectively reused by the light denoising model at every step to refine the sample efficiently. This approach significantly accelerates inference without compromising sample quality. On ImageNet benchmarks, Dual-Rate Diffusion matches the performance of standard baselines while reducing computational cost by a factor of $2$-$4$. Furthermore, we demonstrate that our method is compatible with distillation techniques, such as Moment Matching Distillation, enabling further efficiency gains in few-step generation.
Beyond Single Tokens: Distilling Discrete Diffusion Models via Discrete MMD
Mar 20, 2026It is currently difficult to distill discrete diffusion models. In contrast, continuous diffusion literature has many distillation approaches methods that can reduce sampling steps to a handful. Our method, Discrete Moment Matching Distillation (D-MMD), leverages ideas that have been highly successful in the continuous domain. Whereas previous discrete distillation methods collapse, D-MMD maintains high quality and diversity (given sufficient sampling steps). This is demonstrated on both text and image datasets. Moreover, the newly distilled generators can outperform their teachers.
Unified Latents (UL): How to train your latents
Feb 19, 2026We present Unified Latents (UL), a framework for learning latent representations that are jointly regularized by a diffusion prior and decoded by a diffusion model. By linking the encoder's output noise to the prior's minimum noise level, we obtain a simple training objective that provides a tight upper bound on the latent bitrate. On ImageNet-512, our approach achieves competitive FID of 1.4, with high reconstruction quality (PSNR) while requiring fewer training FLOPs than models trained on Stable Diffusion latents. On Kinetics-600, we set a new state-of-the-art FVD of 1.3.
Simpler Diffusion (SiD2): 1.5 FID on ImageNet512 with pixel-space diffusion
Oct 25, 2024



Latent diffusion models have become the popular choice for scaling up diffusion models for high resolution image synthesis. Compared to pixel-space models that are trained end-to-end, latent models are perceived to be more efficient and to produce higher image quality at high resolution. Here we challenge these notions, and show that pixel-space models can in fact be very competitive to latent approaches both in quality and efficiency, achieving 1.5 FID on ImageNet512 and new SOTA results on ImageNet128 and ImageNet256. We present a simple recipe for scaling end-to-end pixel-space diffusion models to high resolutions. 1: Use the sigmoid loss (Kingma & Gao, 2023) with our prescribed hyper-parameters. 2: Use our simplified memory-efficient architecture with fewer skip-connections. 3: Scale the model to favor processing the image at high resolution with fewer parameters, rather than using more parameters but at a lower resolution. When combining these three steps with recently proposed tricks like guidance intervals, we obtain a family of pixel-space diffusion models we call Simple Diffusion v2 (SiD2).
Multistep Distillation of Diffusion Models via Moment Matching
Jun 06, 2024We present a new method for making diffusion models faster to sample. The method distills many-step diffusion models into few-step models by matching conditional expectations of the clean data given noisy data along the sampling trajectory. Our approach extends recently proposed one-step methods to the multi-step case, and provides a new perspective by interpreting these approaches in terms of moment matching. By using up to 8 sampling steps, we obtain distilled models that outperform not only their one-step versions but also their original many-step teacher models, obtaining new state-of-the-art results on the Imagenet dataset. We also show promising results on a large text-to-image model where we achieve fast generation of high resolution images directly in image space, without needing autoencoders or upsamplers.
HAMMR: HierArchical MultiModal React agents for generic VQA
Apr 08, 2024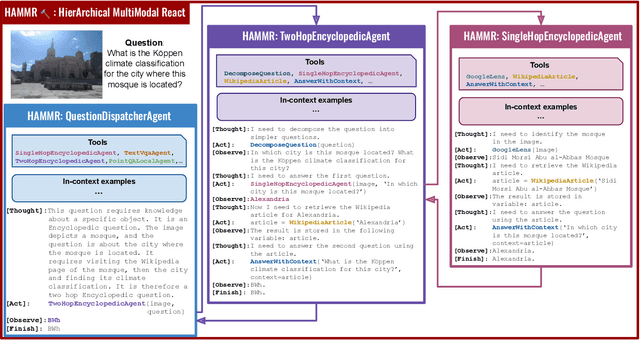
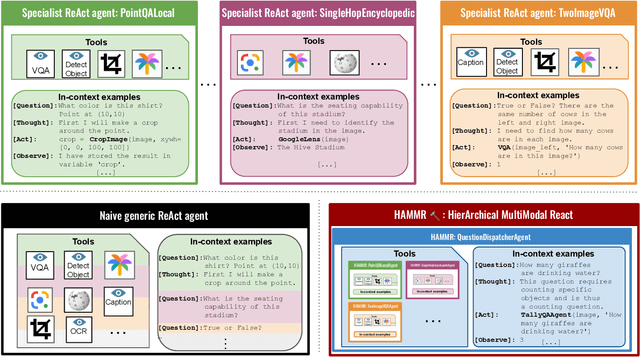


Combining Large Language Models (LLMs) with external specialized tools (LLMs+tools) is a recent paradigm to solve multimodal tasks such as Visual Question Answering (VQA). While this approach was demonstrated to work well when optimized and evaluated for each individual benchmark, in practice it is crucial for the next generation of real-world AI systems to handle a broad range of multimodal problems. Therefore we pose the VQA problem from a unified perspective and evaluate a single system on a varied suite of VQA tasks including counting, spatial reasoning, OCR-based reasoning, visual pointing, external knowledge, and more. In this setting, we demonstrate that naively applying the LLM+tools approach using the combined set of all tools leads to poor results. This motivates us to introduce HAMMR: HierArchical MultiModal React. We start from a multimodal ReAct-based system and make it hierarchical by enabling our HAMMR agents to call upon other specialized agents. This enhances the compositionality of the LLM+tools approach, which we show to be critical for obtaining high accuracy on generic VQA. Concretely, on our generic VQA suite, HAMMR outperforms the naive LLM+tools approach by 19.5%. Additionally, HAMMR achieves state-of-the-art results on this task, outperforming the generic standalone PaLI-X VQA model by 5.0%.
How (not) to ensemble LVLMs for VQA
Oct 10, 2023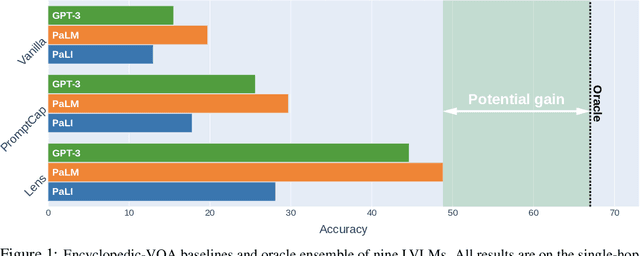


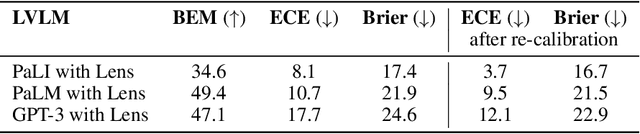
This paper studies ensembling in the era of Large Vision-Language Models (LVLMs). Ensembling is a classical method to combine different models to get increased performance. In the recent work on Encyclopedic-VQA the authors examine a wide variety of models to solve their task: from vanilla LVLMs, to models including the caption as extra context, to models augmented with Lens-based retrieval of Wikipedia pages. Intuitively these models are highly complementary, which should make them ideal for ensembling. Indeed, an oracle experiment shows potential gains from 48.8% accuracy (the best single model) all the way up to 67% (best possible ensemble). So it is a trivial exercise to create an ensemble with substantial real gains. Or is it?
Encyclopedic VQA: Visual questions about detailed properties of fine-grained categories
Jun 15, 2023We propose Encyclopedic-VQA, a large scale visual question answering (VQA) dataset featuring visual questions about detailed properties of fine-grained categories and instances. It contains 221k unique question+answer pairs each matched with (up to) 5 images, resulting in a total of 1M VQA samples. Moreover, our dataset comes with a controlled knowledge base derived from Wikipedia, marking the evidence to support each answer. Empirically, we show that our dataset poses a hard challenge for large vision+language models as they perform poorly on our dataset: PaLI [14] is state-of-the-art on OK-VQA [37], yet it only achieves 13.0% accuracy on our dataset. Moreover, we experimentally show that progress on answering our encyclopedic questions can be achieved by augmenting large models with a mechanism that retrieves relevant information from the knowledge base. An oracle experiment with perfect retrieval achieves 87.0% accuracy on the single-hop portion of our dataset, and an automatic retrieval-augmented prototype yields 48.8%. We believe that our dataset enables future research on retrieval-augmented vision+language models.
Infinite Class Mixup
May 17, 2023



Mixup is a widely adopted strategy for training deep networks, where additional samples are augmented by interpolating inputs and labels of training pairs. Mixup has shown to improve classification performance, network calibration, and out-of-distribution generalisation. While effective, a cornerstone of Mixup, namely that networks learn linear behaviour patterns between classes, is only indirectly enforced since the output interpolation is performed at the probability level. This paper seeks to address this limitation by mixing the classifiers directly instead of mixing the labels for each mixed pair. We propose to define the target of each augmented sample as a uniquely new classifier, whose parameters are a linear interpolation of the classifier vectors of the input pair. The space of all possible classifiers is continuous and spans all interpolations between classifier pairs. To make optimisation tractable, we propose a dual-contrastive Infinite Class Mixup loss, where we contrast the classifier of a mixed pair to both the classifiers and the predicted outputs of other mixed pairs in a batch. Infinite Class Mixup is generic in nature and applies to many variants of Mixup. Empirically, we show that it outperforms standard Mixup and variants such as RegMixup and Remix on balanced, long-tailed, and data-constrained benchmarks, highlighting its broad applicability.
Scaling Vision Transformers to 22 Billion Parameters
Feb 10, 2023



The scaling of Transformers has driven breakthrough capabilities for language models. At present, the largest large language models (LLMs) contain upwards of 100B parameters. Vision Transformers (ViT) have introduced the same architecture to image and video modelling, but these have not yet been successfully scaled to nearly the same degree; the largest dense ViT contains 4B parameters (Chen et al., 2022). We present a recipe for highly efficient and stable training of a 22B-parameter ViT (ViT-22B) and perform a wide variety of experiments on the resulting model. When evaluated on downstream tasks (often with a lightweight linear model on frozen features), ViT-22B demonstrates increasing performance with scale. We further observe other interesting benefits of scale, including an improved tradeoff between fairness and performance, state-of-the-art alignment to human visual perception in terms of shape/texture bias, and improved robustness. ViT-22B demonstrates the potential for "LLM-like" scaling in vision, and provides key steps towards getting there.