 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimpler Diffusion (SiD2): 1.5 FID on ImageNet512 with pixel-space diffusion
Oct 25, 2024



Latent diffusion models have become the popular choice for scaling up diffusion models for high resolution image synthesis. Compared to pixel-space models that are trained end-to-end, latent models are perceived to be more efficient and to produce higher image quality at high resolution. Here we challenge these notions, and show that pixel-space models can in fact be very competitive to latent approaches both in quality and efficiency, achieving 1.5 FID on ImageNet512 and new SOTA results on ImageNet128 and ImageNet256. We present a simple recipe for scaling end-to-end pixel-space diffusion models to high resolutions. 1: Use the sigmoid loss (Kingma & Gao, 2023) with our prescribed hyper-parameters. 2: Use our simplified memory-efficient architecture with fewer skip-connections. 3: Scale the model to favor processing the image at high resolution with fewer parameters, rather than using more parameters but at a lower resolution. When combining these three steps with recently proposed tricks like guidance intervals, we obtain a family of pixel-space diffusion models we call Simple Diffusion v2 (SiD2).
Plots Unlock Time-Series Understanding in Multimodal Models
Oct 03, 2024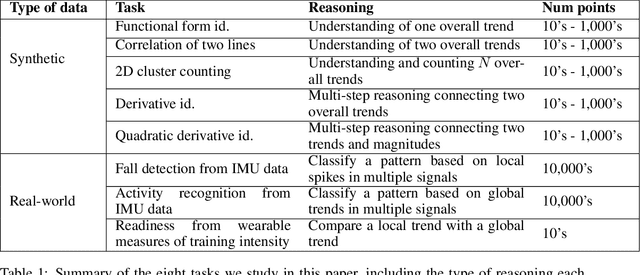

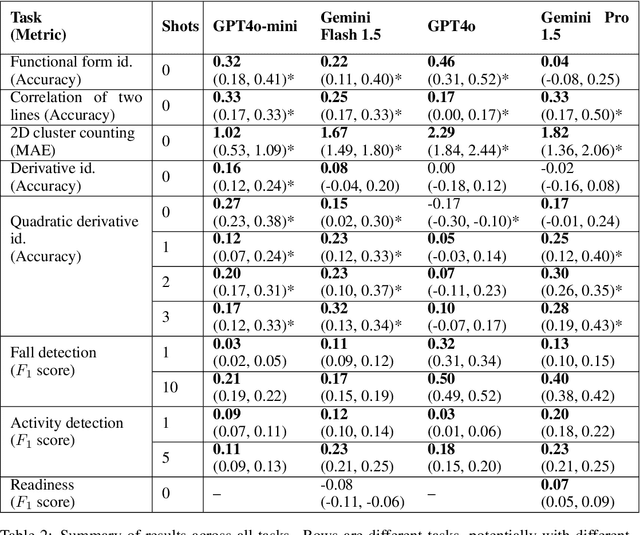
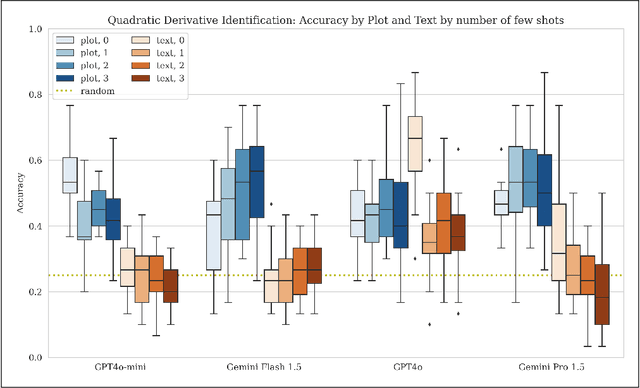
While multimodal foundation models can now natively work with data beyond text, they remain underutilized in analyzing the considerable amounts of multi-dimensional time-series data in fields like healthcare, finance, and social sciences, representing a missed opportunity for richer, data-driven insights. This paper proposes a simple but effective method that leverages the existing vision encoders of these models to "see" time-series data via plots, avoiding the need for additional, potentially costly, model training. Our empirical evaluations show that this approach outperforms providing the raw time-series data as text, with the additional benefit that visual time-series representations demonstrate up to a 90% reduction in model API costs. We validate our hypothesis through synthetic data tasks of increasing complexity, progressing from simple functional form identification on clean data, to extracting trends from noisy scatter plots. To demonstrate generalizability from synthetic tasks with clear reasoning steps to more complex, real-world scenarios, we apply our approach to consumer health tasks - specifically fall detection, activity recognition, and readiness assessment - which involve heterogeneous, noisy data and multi-step reasoning. The overall success in plot performance over text performance (up to an 120% performance increase on zero-shot synthetic tasks, and up to 150% performance increase on real-world tasks), across both GPT and Gemini model families, highlights our approach's potential for making the best use of the native capabilities of foundation models.